 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards a Deep Learning-based Online Quality Prediction System for Welding Processes
Oct 19, 2023
The digitization of manufacturing processes enables promising applications for machine learning-assisted quality assurance. A widely used manufacturing process that can strongly benefit from data-driven solutions is \ac{GMAW}. The welding process is characterized by complex cause-effect relationships between material properties, process conditions and weld quality. In non-laboratory environments with frequently changing process parameters, accurate determination of weld quality by destructive testing is economically unfeasible. Deep learning offers the potential to identify the relationships in available process data and predict the weld quality from process observations. In this paper, we present a concept for a deep learning based predictive quality system in \ac{GMAW}. At its core, the concept involves a pipeline consisting of four major phases: collection and management of multi-sensor data (e.g. current and voltage), real-time processing and feature engineering of the time series data by means of autoencoders, training and deployment of suitable recurrent deep learning models for quality predictions, and model evolutions under changing process conditions using continual learning. The concept provides the foundation for future research activities in which we will realize an online predictive quality system for running production.
A Skin Microbiome Model with AMP interactions and Analysis of Quasi-Stability vs Stability in Population Dynamics
Oct 23, 2023The skin microbiome plays an important role in the maintenance of a healthy skin. It is an ecosystem, composed of several species, competing for resources and interacting with the skin cells. Imbalance in the cutaneous microbiome, also called dysbiosis, has been correlated with several skin conditions, including acne and atopic dermatitis. Generally, dysbiosis is linked to colonization of the skin by a population of opportunistic pathogenic bacteria. Treatments consisting in non-specific elimination of cutaneous microflora have shown conflicting results. In this article, we introduce a mathematical model based on ordinary differential equations, with 2 types of bacteria populations (skin commensals and opportunistic pathogens) and including the production of antimicrobial peptides to study the mechanisms driving the dominance of one population over the other. By using published experimental data, assumed to correspond to the observation of stable states in our model, we reduce the number of parameters of the model from 13 to 5. We then use a formal specification in quantitative temporal logic to calibrate our model by global parameter optimization and perform sensitivity analyses. On the time scale of 2 days of the experiments, the model predicts that certain changes of the environment, like the elevation of skin surface pH, create favorable conditions for the emergence and colonization of the skin by the opportunistic pathogen population, while the production of human AMPs has non-linear effect on the balance between pathogens and commensals. Surprisingly, simulations on longer time scales reveal that the equilibrium reached around 2 days can in fact be a quasi-stable state followed by the reaching of a reversed stable state after 12 days or more. We analyse the conditions of quasi-stability observed in this model using tropical algebraic methods, and show their non-generic character in contrast to slow-fast systems. These conditions are then generalized to a large class of population dynamics models over any number of species.
Enhanced Backpressure Routing Using Wireless Link Features
Oct 14, 2023Backpressure (BP) routing is a well-established framework for distributed routing and scheduling in wireless multi-hop networks. However, the basic BP scheme suffers from poor end-to-end delay due to the drawbacks of slow startup, random walk, and the last packet problem. Biased BP with shortest path awareness can address the first two drawbacks, and sojourn time-based backlog metrics were proposed for the last packet problem. Furthermore, these BP variations require no additional signaling overhead in each time step compared to the basic BP. In this work, we further address three long-standing challenges associated with the aforementioned low-cost BP variations, including optimal scaling of the biases, bias maintenance under mobility, and incorporating sojourn time awareness into biased BP. Our analysis and experimental results show that proper scaling of biases can be achieved with the help of common link features, which can effectively reduce end-to-end delay of BP by mitigating the random walk of packets under low-to-medium traffic, including the last packet scenario. In addition, our low-overhead bias maintenance scheme is shown to be effective under mobility, and our bio-inspired sojourn time-aware backlog metric is demonstrated to be more efficient and effective for the last packet problem than existing approaches when incorporated into biased BP.
Generalized Multi-Level Replanning TAMP Framework for Dynamic Environment
Oct 23, 2023Task and Motion Planning (TAMP) algorithms can generate plans that combine logic and motion aspects for robots. However, these plans are sensitive to interference and control errors. To make TAMP more applicable in real-world, we propose the generalized multi-level replanning TAMP framework(GMRF), blending the probabilistic completeness of sampling-based TAMP algorithm with the robustness of reactive replanning. GMRF generates an nominal plan from the initial state, then dynamically reconstructs this nominal plan in real-time, reorders robot manipulations. Following the logic-level adjustment, GMRF will try to replan a new motion path to ensure the updated plan is feasible at the motion level. Finally, we conducted real-world experiments involving stack and rearrange task domains. The result demonstrate GMRF's ability to swiftly complete tasks in scenarios with varying degrees of interference.
What you see is what you get: Experience ranking with deep neural dataset-to-dataset similarity for topological localisation
Oct 20, 2023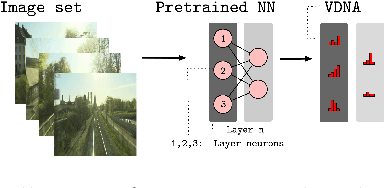
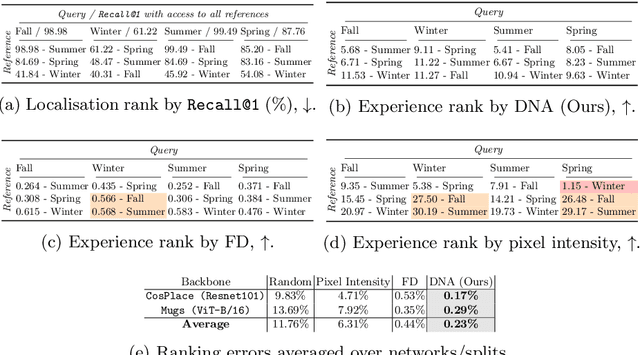


Recalling the most relevant visual memories for localisation or understanding a priori the likely outcome of localisation effort against a particular visual memory is useful for efficient and robust visual navigation. Solutions to this problem should be divorced from performance appraisal against ground truth - as this is not available at run-time - and should ideally be based on generalisable environmental observations. For this, we propose applying the recently developed Visual DNA as a highly scalable tool for comparing datasets of images - in this work, sequences of map and live experiences. In the case of localisation, important dataset differences impacting performance are modes of appearance change, including weather, lighting, and season. Specifically, for any deep architecture which is used for place recognition by matching feature volumes at a particular layer, we use distribution measures to compare neuron-wise activation statistics between live images and multiple previously recorded past experiences, with a potentially large seasonal (winter/summer) or time of day (day/night) shift. We find that differences in these statistics correlate to performance when localising using a past experience with the same appearance gap. We validate our approach over the Nordland cross-season dataset as well as data from Oxford's University Parks with lighting and mild seasonal change, showing excellent ability of our system to rank actual localisation performance across candidate experiences.
DeepFracture: A Generative Approach for Predicting Brittle Fractures
Oct 20, 2023
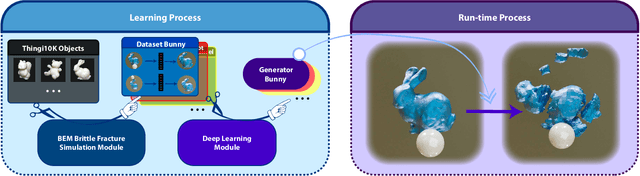
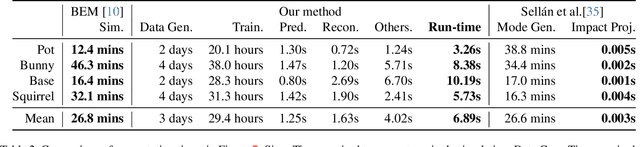
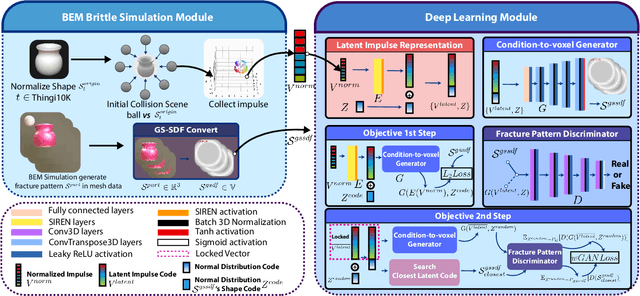
In the realm of brittle fracture animation, generating realistic destruction animations with physics simulation techniques can be computationally expensive. Although methods using Voronoi diagrams or pre-fractured patterns work for real-time applications, they often lack realism in portraying brittle fractures. This paper introduces a novel learning-based approach for seamlessly merging realistic brittle fracture animations with rigid-body simulations. Our method utilizes BEM brittle fracture simulations to create fractured patterns and collision conditions for a given shape, which serve as training data for the learning process. To effectively integrate collision conditions and fractured shapes into a deep learning framework, we introduce the concept of latent impulse representation and geometrically-segmented signed distance function (GS-SDF). The latent impulse representation serves as input, capturing information about impact forces on the shape's surface. Simultaneously, a GS-SDF is used as the output representation of the fractured shape. To address the challenge of optimizing multiple fractured pattern targets with a single latent code, we propose an eight-dimensional latent space based on a normal distribution code within our latent impulse representation design. This adaptation effectively transforms our neural network into a generative one. Our experimental results demonstrate that our approach can generate significantly more detailed brittle fractures compared to existing techniques, all while maintaining commendable computational efficiency during run-time.
Fair collaborative vehicle routing: A deep multi-agent reinforcement learning approach
Oct 26, 2023Collaborative vehicle routing occurs when carriers collaborate through sharing their transportation requests and performing transportation requests on behalf of each other. This achieves economies of scale, thus reducing cost, greenhouse gas emissions and road congestion. But which carrier should partner with whom, and how much should each carrier be compensated? Traditional game theoretic solution concepts are expensive to calculate as the characteristic function scales exponentially with the number of agents. This would require solving the vehicle routing problem (NP-hard) an exponential number of times. We therefore propose to model this problem as a coalitional bargaining game solved using deep multi-agent reinforcement learning, where - crucially - agents are not given access to the characteristic function. Instead, we implicitly reason about the characteristic function; thus, when deployed in production, we only need to evaluate the expensive post-collaboration vehicle routing problem once. Our contribution is that we are the first to consider both the route allocation problem and gain sharing problem simultaneously - without access to the expensive characteristic function. Through decentralised machine learning, our agents bargain with each other and agree to outcomes that correlate well with the Shapley value - a fair profit allocation mechanism. Importantly, we are able to achieve a reduction in run-time of 88%.
* Final, published version can be found here: https://www.sciencedirect.com/science/article/pii/S0968090X23003662
Learning Optimal Classification Trees Robust to Distribution Shifts
Oct 26, 2023We consider the problem of learning classification trees that are robust to distribution shifts between training and testing/deployment data. This problem arises frequently in high stakes settings such as public health and social work where data is often collected using self-reported surveys which are highly sensitive to e.g., the framing of the questions, the time when and place where the survey is conducted, and the level of comfort the interviewee has in sharing information with the interviewer. We propose a method for learning optimal robust classification trees based on mixed-integer robust optimization technology. In particular, we demonstrate that the problem of learning an optimal robust tree can be cast as a single-stage mixed-integer robust optimization problem with a highly nonlinear and discontinuous objective. We reformulate this problem equivalently as a two-stage linear robust optimization problem for which we devise a tailored solution procedure based on constraint generation. We evaluate the performance of our approach on numerous publicly available datasets, and compare the performance to a regularized, non-robust optimal tree. We show an increase of up to 12.48% in worst-case accuracy and of up to 4.85% in average-case accuracy across several datasets and distribution shifts from using our robust solution in comparison to the non-robust one.
Nearest Neighbor Search over Vectorized Lexico-Syntactic Patterns for Relation Extraction from Financial Documents
Oct 26, 2023Relation extraction (RE) has achieved remarkable progress with the help of pre-trained language models. However, existing RE models are usually incapable of handling two situations: implicit expressions and long-tail relation classes, caused by language complexity and data sparsity. Further, these approaches and models are largely inaccessible to users who don't have direct access to large language models (LLMs) and/or infrastructure for supervised training or fine-tuning. Rule-based systems also struggle with implicit expressions. Apart from this, Real world financial documents such as various 10-X reports (including 10-K, 10-Q, etc.) of publicly traded companies pose another challenge to rule-based systems in terms of longer and complex sentences. In this paper, we introduce a simple approach that consults training relations at test time through a nearest-neighbor search over dense vectors of lexico-syntactic patterns and provides a simple yet effective means to tackle the above issues. We evaluate our approach on REFinD and show that our method achieves state-of-the-art performance. We further show that it can provide a good start for human in the loop setup when a small number of annotations are available and it is also beneficial when domain experts can provide high quality patterns.
Sequence-Level Certainty Reduces Hallucination In Knowledge-Grounded Dialogue Generation
Oct 28, 2023Model hallucination has been a crucial interest of research in Natural Language Generation (NLG). In this work, we propose sequence-level certainty as a common theme over hallucination in NLG, and explore the correlation between sequence-level certainty and the level of hallucination in model responses. We categorize sequence-level certainty into two aspects: probabilistic certainty and semantic certainty, and reveal through experiments on Knowledge-Grounded Dialogue Generation (KGDG) task that both a higher level of probabilistic certainty and a higher level of semantic certainty in model responses are significantly correlated with a lower level of hallucination. What's more, we provide theoretical proof and analysis to show that semantic certainty is a good estimator of probabilistic certainty, and therefore has the potential as an alternative to probability-based certainty estimation in black-box scenarios. Based on the observation on the relationship between certainty and hallucination, we further propose Certainty-based Response Ranking (CRR), a decoding-time method for mitigating hallucination in NLG. Based on our categorization of sequence-level certainty, we propose 2 types of CRR approach: Probabilistic CRR (P-CRR) and Semantic CRR (S-CRR). P-CRR ranks individually sampled model responses using their arithmetic mean log-probability of the entire sequence. S-CRR approaches certainty estimation from meaning-space, and ranks a number of model response candidates based on their semantic certainty level, which is estimated by the entailment-based Agreement Score (AS). Through extensive experiments across 3 KGDG datasets, 3 decoding methods, and on 4 different models, we validate the effectiveness of our 2 proposed CRR methods to reduce model hallucination.