 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VCISR: Blind Single Image Super-Resolution with Video Compression Synthetic Data
Nov 02, 2023


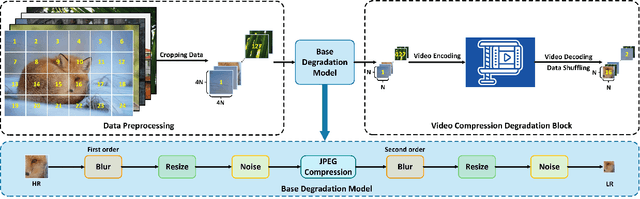

In the blind single image super-resolution (SISR) task, existing works have been successful in restoring image-level unknown degradations. However, when a single video frame becomes the input, these works usually fail to address degradations caused by video compression, such as mosquito noise, ringing, blockiness, and staircase noise. In this work, we for the first time, present a video compression-based degradation model to synthesize low-resolution image data in the blind SISR task. Our proposed image synthesizing method is widely applicable to existing image datasets, so that a single degraded image can contain distortions caused by the lossy video compression algorithms. This overcomes the leak of feature diversity in video data and thus retains the training efficiency. By introducing video coding artifacts to SISR degradation models, neural networks can super-resolve images with the ability to restore video compression degradations, and achieve better results on restoring generic distortions caused by image compression as well. Our proposed approach achieves superior performance in SOTA no-reference Image Quality Assessment, and shows better visual quality on various datasets. In addition, we evaluate the SISR neural network trained with our degradation model on video super-resolution (VSR) datasets. Compared to architectures specifically designed for the VSR purpose, our method exhibits similar or better performance, evidencing that the presented strategy on infusing video-based degradation is generalizable to address more complicated compression artifacts even without temporal cues.
Terrain-Informed Self-Supervised Learning: Enhancing Building Footprint Extraction from LiDAR Data with Limited Annotations
Nov 02, 2023Estimating building footprint maps from geospatial data is of paramount importance in urban planning, development, disaster management, and various other applications. Deep learning methodologies have gained prominence in building segmentation maps, offering the promise of precise footprint extraction without extensive post-processing. However, these methods face challenges in generalization and label efficiency, particularly in remote sensing, where obtaining accurate labels can be both expensive and time-consuming. To address these challenges, we propose terrain-aware self-supervised learning, tailored to remote sensing, using digital elevation models from LiDAR data. We propose to learn a model to differentiate between bare Earth and superimposed structures enabling the network to implicitly learn domain-relevant features without the need for extensive pixel-level annotations. We test the effectiveness of our approach by evaluating building segmentation performance on test datasets with varying label fractions. Remarkably, with only 1% of the labels (equivalent to 25 labeled examples), our method improves over ImageNet pre-training, showing the advantage of leveraging unlabeled data for feature extraction in the domain of remote sensing. The performance improvement is more pronounced in few-shot scenarios and gradually closes the gap with ImageNet pre-training as the label fraction increases. We test on a dataset characterized by substantial distribution shifts and labeling errors to demonstrate the generalizability of our approach. When compared to other baselines, including ImageNet pretraining and more complex architectures, our approach consistently performs better, demonstrating the efficiency and effectiveness of self-supervised terrain-aware feature learning.
Learning to Adapt CLIP for Few-Shot Monocular Depth Estimation
Nov 02, 2023Pre-trained Vision-Language Models (VLMs), such as CLIP, have shown enhanced performance across a range of tasks that involve the integration of visual and linguistic modalities. When CLIP is used for depth estimation tasks, the patches, divided from the input images, can be combined with a series of semantic descriptions of the depth information to obtain similarity results. The coarse estimation of depth is then achieved by weighting and summing the depth values, called depth bins, corresponding to the predefined semantic descriptions. The zero-shot approach circumvents the computational and time-intensive nature of traditional fully-supervised depth estimation methods. However, this method, utilizing fixed depth bins, may not effectively generalize as images from different scenes may exhibit distinct depth distributions. To address this challenge, we propose a few-shot-based method which learns to adapt the VLMs for monocular depth estimation to balance training costs and generalization capabilities. Specifically, it assigns different depth bins for different scenes, which can be selected by the model during inference. Additionally, we incorporate learnable prompts to preprocess the input text to convert the easily human-understood text into easily model-understood vectors and further enhance the performance. With only one image per scene for training, our extensive experiment results on the NYU V2 and KITTI dataset demonstrate that our method outperforms the previous state-of-the-art method by up to 10.6\% in terms of MARE.
GREEMA: Proposal and Experimental Verification of Growing Robot by Eating Environmental MAterial for Landslide Disaster
Nov 02, 2023In areas that are inaccessible to humans, such as the lunar surface and landslide sites, there is a need for multiple autonomous mobile robot systems that can replace human workers. In particular, at landslide sites such as river channel blockages, robots are required to remove water and sediment from the site as soon as possible. Conventionally, several construction machines have been deployed to the site for civil engineering work. However, because of the large size and weight of conventional construction equipment, it is difficult to move multiple units of construction equipment to the site, resulting in significant transportation costs and time. To solve such problems, this study proposes a novel growing robot by eating environmental material called GREEMA, which is lightweight and compact during transportation, but can function by eating on environmental materials once it arrives at the site. GREEMA actively takes in environmental materials such as water and sediment, uses them as its structure, and removes them by moving itself. In this paper, we developed and experimentally verified two types of GREEMAs. First, we developed a fin-type swimming robot that passively takes water into its body using a water-absorbing polymer and forms a body to express its swimming function. Second, we constructed an arm-type robot that eats soil to increase the rigidity of its body. We discuss the results of these two experiments from the viewpoint of Explicit-Implicit control and describe the design theory of GREEMA.
Intelligent QoS aware slice resource allocation with user association parameterization for beyond 5G ORAN based architecture using DRL
Nov 02, 2023The diverse requirements of beyond 5G services increase design complexity and demand dynamic adjustments to the network parameters. This can be achieved with slicing and programmable network architectures such as the open radio access network (ORAN). It facilitates the tuning of the network components exactly to the demands of future-envisioned applications as well as intelligence at the edge of the network. Artificial intelligence (AI) has recently drawn a lot of interest for its potential to solve challenging issues in wireless communication. Due to the non-deterministic, random, and complex behavior of models and parameters involved in the process, radio resource management is one of the topics that needs to be addressed with such techniques. The study presented in this paper proposes quality of service (QoS)-aware intra-slice resource allocation that provides superior performance compared to baseline and state of the art strategies. The slice-dedicated intelligent agents learn how to handle resources at near-RT RIC level time granularities while optimizing various key performance indicators (KPIs) and meeting QoS requirements for each end user. In order to improve KPIs and system performance with various reward functions, the study discusses Markov's decision process (MDP) and deep reinforcement learning (DRL) techniques, notably the deep Q network (DQN). The simulation evaluates the efficacy of the algorithm under dynamic conditions and various network characteristics. Results and analysis demonstrate the improvement in the performance of the network for enhanced mobile broadband (eMBB) and ultra-reliable low latency (URLLC) slice categories.
On the Consistency and Robustness of Saliency Explanations for Time Series Classification
Sep 04, 2023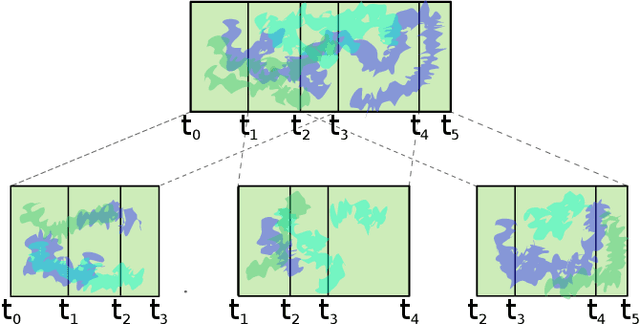
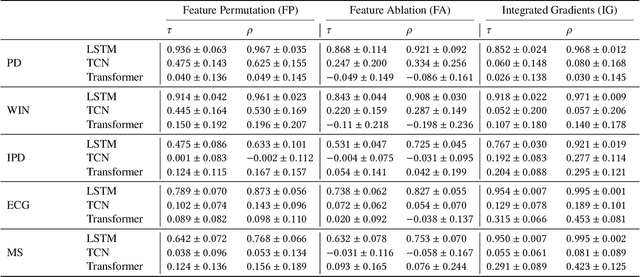
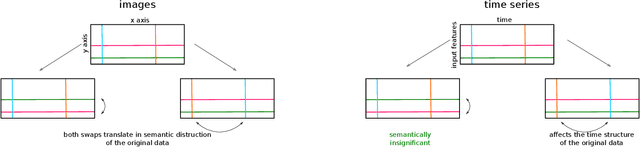
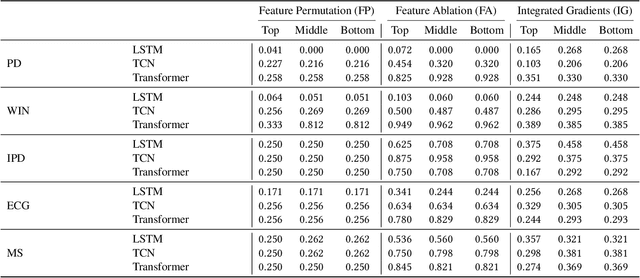
Interpretable machine learning and explainable artificial intelligence have become essential in many applications. The trade-off between interpretability and model performance is the traitor to developing intrinsic and model-agnostic interpretation methods. Although model explanation approaches have achieved significant success in vision and natural language domains, explaining time series remains challenging. The complex pattern in the feature domain, coupled with the additional temporal dimension, hinders efficient interpretation. Saliency maps have been applied to interpret time series windows as images. However, they are not naturally designed for sequential data, thus suffering various issues. This paper extensively analyzes the consistency and robustness of saliency maps for time series features and temporal attribution. Specifically, we examine saliency explanations from both perturbation-based and gradient-based explanation models in a time series classification task. Our experimental results on five real-world datasets show that they all lack consistent and robust performances to some extent. By drawing attention to the flawed saliency explanation models, we motivate to develop consistent and robust explanations for time series classification.
On the accuracy and efficiency of group-wise clipping in differentially private optimization
Oct 30, 2023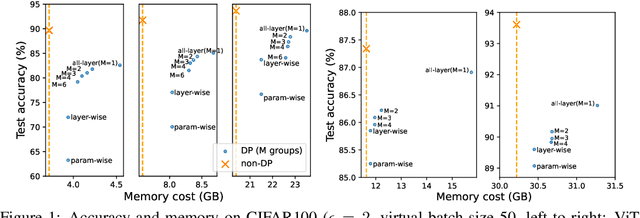
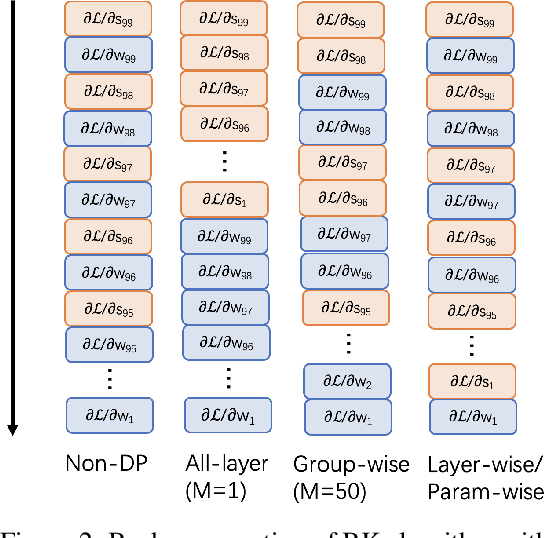
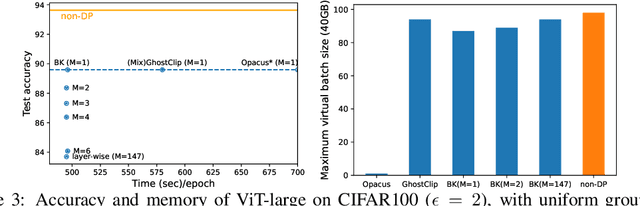
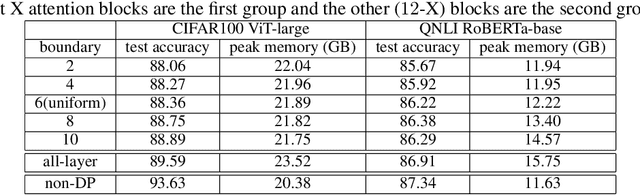
Recent advances have substantially improved the accuracy, memory cost, and training speed of differentially private (DP) deep learning, especially on large vision and language models with millions to billions of parameters. In this work, we thoroughly study the per-sample gradient clipping style, a key component in DP optimization. We show that different clipping styles have the same time complexity but instantiate an accuracy-memory trade-off: while the all-layer clipping (of coarse granularity) is the most prevalent and usually gives the best accuracy, it incurs heavier memory cost compared to other group-wise clipping, such as the layer-wise clipping (of finer granularity). We formalize this trade-off through our convergence theory and complexity analysis. Importantly, we demonstrate that the accuracy gap between group-wise clipping and all-layer clipping becomes smaller for larger models, while the memory advantage of the group-wise clipping remains. Consequently, the group-wise clipping allows DP optimization of large models to achieve high accuracy and low peak memory simultaneously.
On Measuring Fairness in Generative Models
Oct 30, 2023Recently, there has been increased interest in fair generative models. In this work, we conduct, for the first time, an in-depth study on fairness measurement, a critical component in gauging progress on fair generative models. We make three contributions. First, we conduct a study that reveals that the existing fairness measurement framework has considerable measurement errors, even when highly accurate sensitive attribute (SA) classifiers are used. These findings cast doubts on previously reported fairness improvements. Second, to address this issue, we propose CLassifier Error-Aware Measurement (CLEAM), a new framework which uses a statistical model to account for inaccuracies in SA classifiers. Our proposed CLEAM reduces measurement errors significantly, e.g., 4.98% $\rightarrow$ 0.62% for StyleGAN2 w.r.t. Gender. Additionally, CLEAM achieves this with minimal additional overhead. Third, we utilize CLEAM to measure fairness in important text-to-image generator and GANs, revealing considerable biases in these models that raise concerns about their applications. Code and more resources: https://sutd-visual-computing-group.github.io/CLEAM/.
Lyapunov-Based Dropout Deep Neural Network (Lb-DDNN) Controller
Oct 30, 2023Deep neural network (DNN)-based adaptive controllers can be used to compensate for unstructured uncertainties in nonlinear dynamic systems. However, DNNs are also very susceptible to overfitting and co-adaptation. Dropout regularization is an approach where nodes are randomly dropped during training to alleviate issues such as overfitting and co-adaptation. In this paper, a dropout DNN-based adaptive controller is developed. The developed dropout technique allows the deactivation of weights that are stochastically selected for each individual layer within the DNN. Simultaneously, a Lyapunov-based real-time weight adaptation law is introduced to update the weights of all layers of the DNN for online unsupervised learning. A non-smooth Lyapunov-based stability analysis is performed to ensure asymptotic convergence of the tracking error. Simulation results of the developed dropout DNN-based adaptive controller indicate a 38.32% improvement in the tracking error, a 53.67% improvement in the function approximation error, and 50.44% lower control effort when compared to a baseline adaptive DNN-based controller without dropout regularization.
Scenario-Aware Audio-Visual TF-GridNet for Target Speech Extraction
Oct 30, 2023Target speech extraction aims to extract, based on a given conditioning cue, a target speech signal that is corrupted by interfering sources, such as noise or competing speakers. Building upon the achievements of the state-of-the-art (SOTA) time-frequency speaker separation model TF-GridNet, we propose AV-GridNet, a visual-grounded variant that incorporates the face recording of a target speaker as a conditioning factor during the extraction process. Recognizing the inherent dissimilarities between speech and noise signals as interfering sources, we also propose SAV-GridNet, a scenario-aware model that identifies the type of interfering scenario first and then applies a dedicated expert model trained specifically for that scenario. Our proposed model achieves SOTA results on the second COG-MHEAR Audio-Visual Speech Enhancement Challenge, outperforming other models by a significant margin, objectively and in a listening test. We also perform an extensive analysis of the results under the two scenarios.