 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Teacher Perception of Automatically Extracted Grammar Concepts for L2 Language Learning
Oct 27, 2023

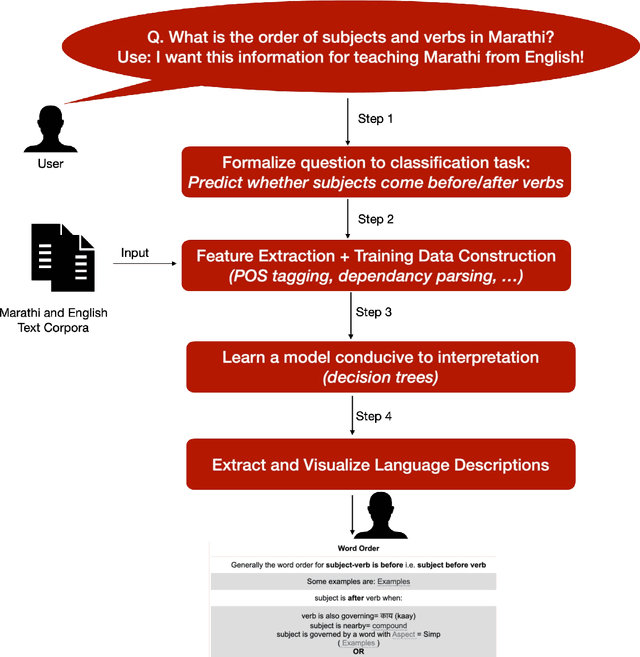

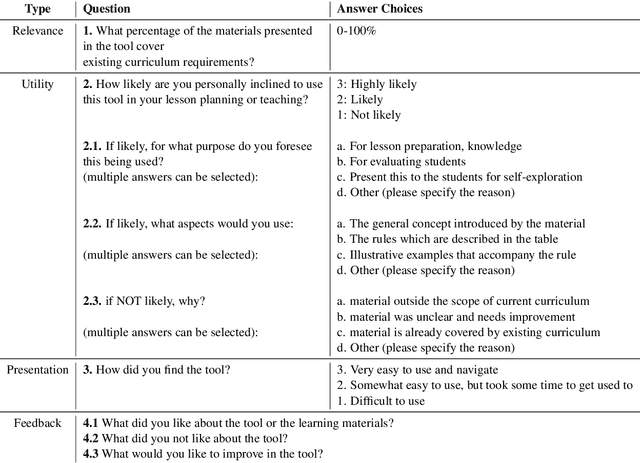
One of the challenges in language teaching is how best to organize rules regarding syntax, semantics, or phonology in a meaningful manner. This not only requires content creators to have pedagogical skills, but also have that language's deep understanding. While comprehensive materials to develop such curricula are available in English and some broadly spoken languages, for many other languages, teachers need to manually create them in response to their students' needs. This is challenging because i) it requires that such experts be accessible and have the necessary resources, and ii) describing all the intricacies of a language is time-consuming and prone to omission. In this work, we aim to facilitate this process by automatically discovering and visualizing grammar descriptions. We extract descriptions from a natural text corpus that answer questions about morphosyntax (learning of word order, agreement, case marking, or word formation) and semantics (learning of vocabulary). We apply this method for teaching two Indian languages, Kannada and Marathi, which, unlike English, do not have well-developed resources for second language learning. To assess the perceived utility of the extracted material, we enlist the help of language educators from schools in North America to perform a manual evaluation, who find the materials have potential to be used for their lesson preparation and learner evaluation.
Unified Segment-to-Segment Framework for Simultaneous Sequence Generation
Oct 27, 2023Simultaneous sequence generation is a pivotal task for real-time scenarios, such as streaming speech recognition, simultaneous machine translation and simultaneous speech translation, where the target sequence is generated while receiving the source sequence. The crux of achieving high-quality generation with low latency lies in identifying the optimal moments for generating, accomplished by learning a mapping between the source and target sequences. However, existing methods often rely on task-specific heuristics for different sequence types, limiting the model's capacity to adaptively learn the source-target mapping and hindering the exploration of multi-task learning for various simultaneous tasks. In this paper, we propose a unified segment-to-segment framework (Seg2Seg) for simultaneous sequence generation, which learns the mapping in an adaptive and unified manner. During the process of simultaneous generation, the model alternates between waiting for a source segment and generating a target segment, making the segment serve as the natural bridge between the source and target. To accomplish this, Seg2Seg introduces a latent segment as the pivot between source to target and explores all potential source-target mappings via the proposed expectation training, thereby learning the optimal moments for generating. Experiments on multiple simultaneous generation tasks demonstrate that Seg2Seg achieves state-of-the-art performance and exhibits better generality across various tasks.
Practical Computational Power of Linear Transformers and Their Recurrent and Self-Referential Extensions
Oct 24, 2023Recent studies of the computational power of recurrent neural networks (RNNs) reveal a hierarchy of RNN architectures, given real-time and finite-precision assumptions. Here we study auto-regressive Transformers with linearised attention, a.k.a. linear Transformers (LTs) or Fast Weight Programmers (FWPs). LTs are special in the sense that they are equivalent to RNN-like sequence processors with a fixed-size state, while they can also be expressed as the now-popular self-attention networks. We show that many well-known results for the standard Transformer directly transfer to LTs/FWPs. Our formal language recognition experiments demonstrate how recently proposed FWP extensions such as recurrent FWPs and self-referential weight matrices successfully overcome certain limitations of the LT, e.g., allowing for generalisation on the parity problem. Our code is public.
Spike Accumulation Forwarding for Effective Training of Spiking Neural Networks
Oct 16, 2023In this article, we propose a new paradigm for training spiking neural networks (SNNs), spike accumulation forwarding (SAF). It is known that SNNs are energy-efficient but difficult to train. Consequently, many researchers have proposed various methods to solve this problem, among which online training through time (OTTT) is a method that allows inferring at each time step while suppressing the memory cost. However, to compute efficiently on GPUs, OTTT requires operations with spike trains and weighted summation of spike trains during forwarding. In addition, OTTT has shown a relationship with the Spike Representation, an alternative training method, though theoretical agreement with Spike Representation has yet to be proven. Our proposed method can solve these problems; namely, SAF can halve the number of operations during the forward process, and it can be theoretically proven that SAF is consistent with the Spike Representation and OTTT, respectively. Furthermore, we confirmed the above contents through experiments and showed that it is possible to reduce memory and training time while maintaining accuracy.
Towards a Deep Learning-based Online Quality Prediction System for Welding Processes
Oct 20, 2023The digitization of manufacturing processes enables promising applications for machine learning-assisted quality assurance. A widely used manufacturing process that can strongly benefit from data-driven solutions is gas metal arc welding (GMAW). The welding process is characterized by complex cause-effect relationships between material properties, process conditions and weld quality. In non-laboratory environments with frequently changing process parameters, accurate determination of weld quality by destructive testing is economically unfeasible. Deep learning offers the potential to identify the relationships in available process data and predict the weld quality from process observations. In this paper, we present a concept for a deep learning based predictive quality system in GMAW. At its core, the concept involves a pipeline consisting of four major phases: collection and management of multi-sensor data (e.g. current and voltage), real-time processing and feature engineering of the time series data by means of autoencoders, training and deployment of suitable recurrent deep learning models for quality predictions, and model evolutions under changing process conditions using continual learning. The concept provides the foundation for future research activities in which we will realize an online predictive quality system for running production.
Super resolution of histopathological frozen sections via deep learning preserving tissue structure
Oct 17, 2023Histopathology plays a pivotal role in medical diagnostics. In contrast to preparing permanent sections for histopathology, a time-consuming process, preparing frozen sections is significantly faster and can be performed during surgery, where the sample scanning time should be optimized. Super-resolution techniques allow imaging the sample in lower magnification and sparing scanning time. In this paper, we present a new approach to super resolution for histopathological frozen sections, with focus on achieving better distortion measures, rather than pursuing photorealistic images that may compromise critical diagnostic information. Our deep-learning architecture focuses on learning the error between interpolated images and real images, thereby it generates high-resolution images while preserving critical image details, reducing the risk of diagnostic misinterpretation. This is done by leveraging the loss functions in the frequency domain, assigning higher weights to the reconstruction of complex, high-frequency components. In comparison to existing methods, we obtained significant improvements in terms of Structural Similarity Index (SSIM) and Peak Signal-to-Noise Ratio (PSNR), as well as indicated details that lost in the low-resolution frozen-section images, affecting the pathologist's clinical decisions. Our approach has a great potential in providing more-rapid frozen-section imaging, with less scanning, while preserving the high resolution in the imaged sample.
Dynamic Resource Management in Integrated NOMA Terrestrial-Satellite Networks using Multi-Agent Reinforcement Learning
Oct 18, 2023This study introduces a resource allocation framework for integrated satellite-terrestrial networks to address these challenges. The framework leverages local cache pool deployments and non-orthogonal multiple access (NOMA) to reduce time delays and improve energy efficiency. Our proposed approach utilizes a multi-agent enabled deep deterministic policy gradient algorithm (MADDPG) to optimize user association, cache design, and transmission power control, resulting in enhanced energy efficiency. The approach comprises two phases: User Association and Power Control, where users are treated as agents, and Cache Optimization, where the satellite (Bs) is considered the agent. Through extensive simulations, we demonstrate that our approach surpasses conventional single-agent deep reinforcement learning algorithms in addressing cache design and resource allocation challenges in integrated terrestrial-satellite networks. Specifically, our proposed approach achieves significantly higher energy efficiency and reduced time delays compared to existing methods.
SpecTr: Fast Speculative Decoding via Optimal Transport
Oct 23, 2023Autoregressive sampling from large language models has led to state-of-the-art results in several natural language tasks. However, autoregressive sampling generates tokens one at a time making it slow, and even prohibitive in certain tasks. One way to speed up sampling is $\textit{speculative decoding}$: use a small model to sample a $\textit{draft}$ (block or sequence of tokens), and then score all tokens in the draft by the large language model in parallel. A subset of the tokens in the draft are accepted (and the rest rejected) based on a statistical method to guarantee that the final output follows the distribution of the large model. In this work, we provide a principled understanding of speculative decoding through the lens of optimal transport (OT) with $\textit{membership cost}$. This framework can be viewed as an extension of the well-known $\textit{maximal-coupling}$ problem. This new formulation enables us to generalize the speculative decoding method to allow for a set of $k$ candidates at the token-level, which leads to an improved optimal membership cost. We show that the optimal draft selection algorithm (transport plan) can be computed via linear programming, whose best-known runtime is exponential in $k$. We then propose a valid draft selection algorithm whose acceptance probability is $(1-1/e)$-optimal multiplicatively. Moreover, it can be computed in time almost linear with size of domain of a single token. Using this $new draft selection$ algorithm, we develop a new autoregressive sampling algorithm called $\textit{SpecTr}$, which provides speedup in decoding while ensuring that there is no quality degradation in the decoded output. We experimentally demonstrate that for state-of-the-art large language models, the proposed approach achieves a wall clock speedup of 2.13X, a further 1.37X speedup over speculative decoding on standard benchmarks.
DiffRef3D: A Diffusion-based Proposal Refinement Framework for 3D Object Detection
Oct 25, 2023Denoising diffusion models show remarkable performances in generative tasks, and their potential applications in perception tasks are gaining interest. In this paper, we introduce a novel framework named DiffRef3D which adopts the diffusion process on 3D object detection with point clouds for the first time. Specifically, we formulate the proposal refinement stage of two-stage 3D object detectors as a conditional diffusion process. During training, DiffRef3D gradually adds noise to the residuals between proposals and target objects, then applies the noisy residuals to proposals to generate hypotheses. The refinement module utilizes these hypotheses to denoise the noisy residuals and generate accurate box predictions. In the inference phase, DiffRef3D generates initial hypotheses by sampling noise from a Gaussian distribution as residuals and refines the hypotheses through iterative steps. DiffRef3D is a versatile proposal refinement framework that consistently improves the performance of existing 3D object detection models. We demonstrate the significance of DiffRef3D through extensive experiments on the KITTI benchmark. Code will be available.
Frequency-Aware Transformer for Learned Image Compression
Oct 25, 2023Learned image compression (LIC) has gained traction as an effective solution for image storage and transmission in recent years. However, existing LIC methods are redundant in latent representation due to limitations in capturing anisotropic frequency components and preserving directional details. To overcome these challenges, we propose a novel frequency-aware transformer (FAT) block that for the first time achieves multiscale directional ananlysis for LIC. The FAT block comprises frequency-decomposition window attention (FDWA) modules to capture multiscale and directional frequency components of natural images. Additionally, we introduce frequency-modulation feed-forward network (FMFFN) to adaptively modulate different frequency components, improving rate-distortion performance. Furthermore, we present a transformer-based channel-wise autoregressive (T-CA) model that effectively exploits channel dependencies. Experiments show that our method achieves state-of-the-art rate-distortion performance compared to existing LIC methods, and evidently outperforms latest standardized codec VTM-12.1 by 14.5%, 15.1%, 13.0% in BD-rate on the Kodak, Tecnick, and CLIC datasets.