 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Continual Event Extraction with Semantic Confusion Rectification
Oct 24, 2023
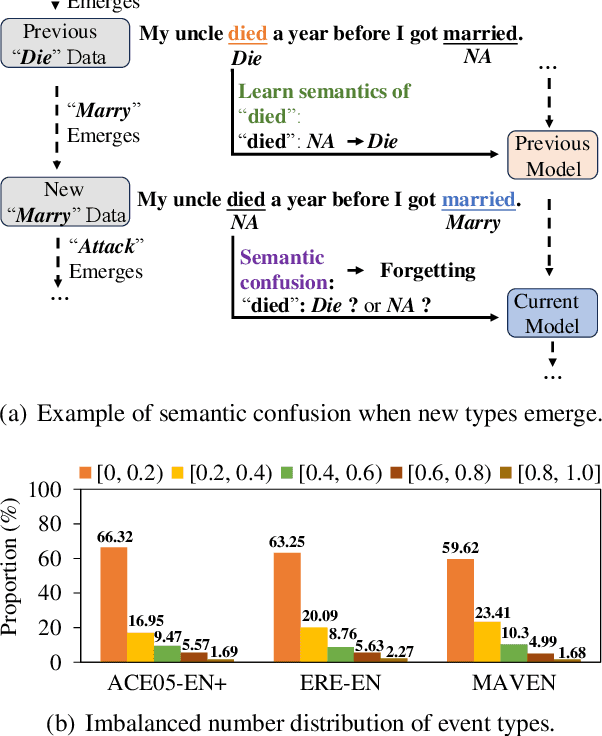
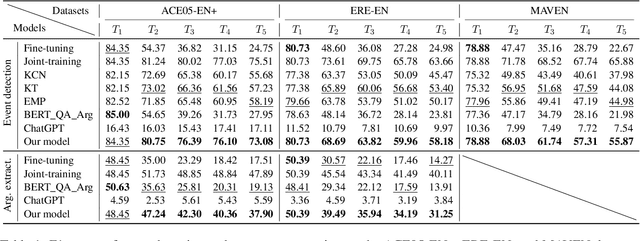
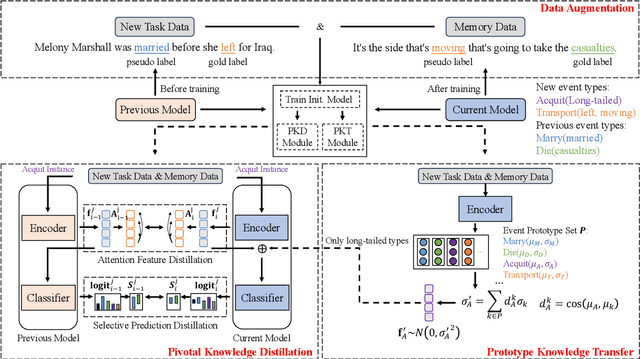
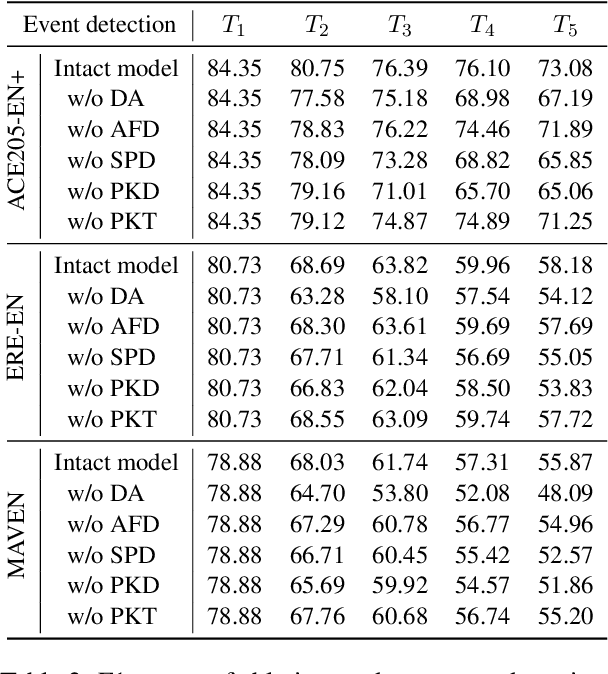
We study continual event extraction, which aims to extract incessantly emerging event information while avoiding forgetting. We observe that the semantic confusion on event types stems from the annotations of the same text being updated over time. The imbalance between event types even aggravates this issue. This paper proposes a novel continual event extraction model with semantic confusion rectification. We mark pseudo labels for each sentence to alleviate semantic confusion. We transfer pivotal knowledge between current and previous models to enhance the understanding of event types. Moreover, we encourage the model to focus on the semantics of long-tailed event types by leveraging other associated types. Experimental results show that our model outperforms state-of-the-art baselines and is proficient in imbalanced datasets.
Robust Depth Linear Error Decomposition with Double Total Variation and Nuclear Norm for Dynamic MRI Reconstruction
Oct 23, 2023Compressed Sensing (CS) significantly speeds up Magnetic Resonance Image (MRI) processing and achieves accurate MRI reconstruction from under-sampled k-space data. According to the current research, there are still several problems with dynamic MRI k-space reconstruction based on CS. 1) There are differences between the Fourier domain and the Image domain, and the differences between MRI processing of different domains need to be considered. 2) As three-dimensional data, dynamic MRI has its spatial-temporal characteristics, which need to calculate the difference and consistency of surface textures while preserving structural integrity and uniqueness. 3) Dynamic MRI reconstruction is time-consuming and computationally resource-dependent. In this paper, we propose a novel robust low-rank dynamic MRI reconstruction optimization model via highly under-sampled and Discrete Fourier Transform (DFT) called the Robust Depth Linear Error Decomposition Model (RDLEDM). Our method mainly includes linear decomposition, double Total Variation (TV), and double Nuclear Norm (NN) regularizations. By adding linear image domain error analysis, the noise is reduced after under-sampled and DFT processing, and the anti-interference ability of the algorithm is enhanced. Double TV and NN regularizations can utilize both spatial-temporal characteristics and explore the complementary relationship between different dimensions in dynamic MRI sequences. In addition, Due to the non-smoothness and non-convexity of TV and NN terms, it is difficult to optimize the unified objective model. To address this issue, we utilize a fast algorithm by solving a primal-dual form of the original problem. Compared with five state-of-the-art methods, extensive experiments on dynamic MRI data demonstrate the superior performance of the proposed method in terms of both reconstruction accuracy and time complexity.
Iterative PnP and its application in 3D-2D vascular image registration for robot navigation
Oct 19, 2023This paper reports on a new real-time robot-centered 3D-2D vascular image alignment algorithm, which is robust to outliers and can align nonrigid shapes. Few works have managed to achieve both real-time and accurate performance for vascular intervention robots. This work bridges high-accuracy 3D-2D registration techniques and computational efficiency requirements in intervention robot applications. We categorize centerline-based vascular 3D-2D image registration problems as an iterative Perspective-n-Point (PnP) problem and propose to use the Levenberg-Marquardt solver on the Lie manifold. Then, the recently developed Reproducing Kernel Hilbert Space (RKHS) algorithm is introduced to overcome the ``big-to-small'' problem in typical robotic scenarios. Finally, an iterative reweighted least squares is applied to solve RKHS-based formulation efficiently. Experiments indicate that the proposed algorithm processes registration over 50 Hz (rigid) and 20 Hz (nonrigid) and obtains competing registration accuracy similar to other works. Results indicate that our Iterative PnP is suitable for future vascular intervention robot applications.
NP-SBFL: Bridging the Gap Between Spectrum-Based Fault Localization and Faulty Neural Pathways Diagnosis
Oct 29, 2023Deep learning has revolutionized various real-world applications, but the quality of Deep Neural Networks (DNNs) remains a concern. DNNs are complex and have millions of parameters, making it difficult to determine their contributions to fulfilling a task. Moreover, the behavior of a DNN is highly influenced by the data used during training, making it challenging to collect enough data to exercise all potential DNN behavior under all possible scenarios. This paper proposes a novel NP-SBFL method that adapts spectrum-based fault localization (SBFL) to locate faulty neural pathways. Our method identifies critical neurons using the layer-wise relevance propagation (LRP) technique and determines which critical neurons are faulty. We propose a multi-stage gradient ascent (MGA), an extension of gradient ascent, to effectively activate a sequence of neurons one at a time while maintaining the activation of previous neurons. We evaluated the effectiveness of our method on two commonly used datasets, MNIST and CIFAR-10, two baselines DeepFault and NP-SBFL-GA, and three suspicious neuron measures, Tarantula, Ochiai, and Barinel. The empirical results showed that NP-SBFL-MGA is statistically more effective than the baselines at identifying suspicious paths and synthesizing adversarial inputs. Particularly, Tarantula on NP-SBFL-MGA had the highest fault detection rate at 96.75%, surpassing DeepFault on Ochiai (89.90%) and NP-SBFL-GA on Ochiai (60.61%). Our approach also yielded comparable results to the baselines in synthesizing naturalness inputs, and we found a positive correlation between the coverage of critical paths and the number of failed tests in DNN fault localization.
Joint Localization and Communication Enhancement in Uplink Integrated Sensing and Communications System with Clock Asynchronism
Oct 28, 2023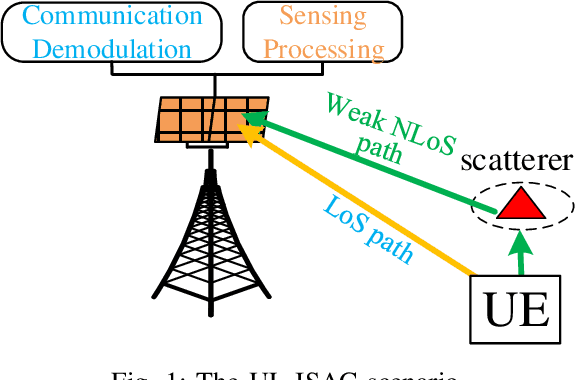
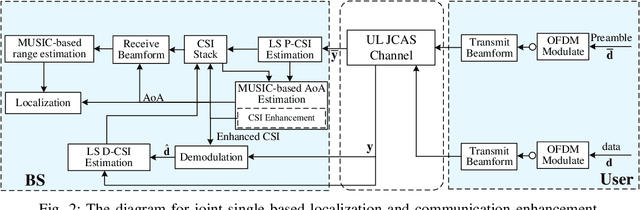
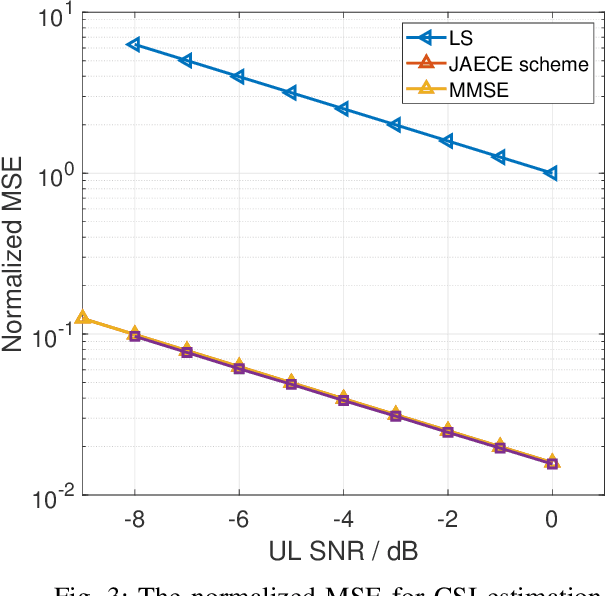
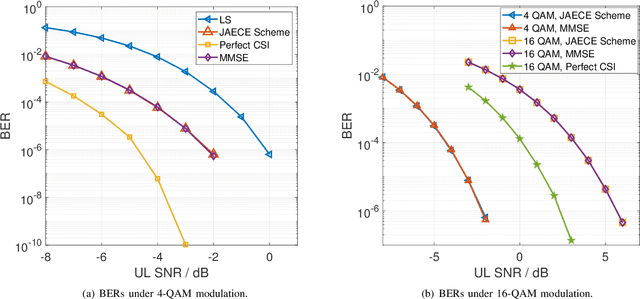
In this paper, we propose a joint single-base localization and communication enhancement scheme for the uplink (UL) integrated sensing and communications (ISAC) system with asynchronism, which can achieve accurate single-base localization of user equipment (UE) and significantly improve the communication reliability despite the existence of timing offset (TO) due to the clock asynchronism between UE and base station (BS). Our proposed scheme integrates the CSI enhancement into the multiple signal classification (MUSIC)-based AoA estimation and thus imposes no extra complexity on the ISAC system. We further exploit a MUSIC-based range estimation method and prove that it can suppress the time-varying TO-related phase terms. Exploiting the AoA and range estimation of UE, we can estimate the location of UE. Finally, we propose a joint CSI and data signals-based localization scheme that can coherently exploit the data and the CSI signals to improve the AoA and range estimation, which further enhances the single-base localization of UE. The extensive simulation results show that the enhanced CSI can achieve equivalent bit error rate performance to the minimum mean square error (MMSE) CSI estimator. The proposed joint CSI and data signals-based localization scheme can achieve decimeter-level localization accuracy despite the existing clock asynchronism and improve the localization mean square error (MSE) by about 8 dB compared with the maximum likelihood (ML)-based benchmark method.
Self-Supervised Multi-Modality Learning for Multi-Label Skin Lesion Classification
Oct 28, 2023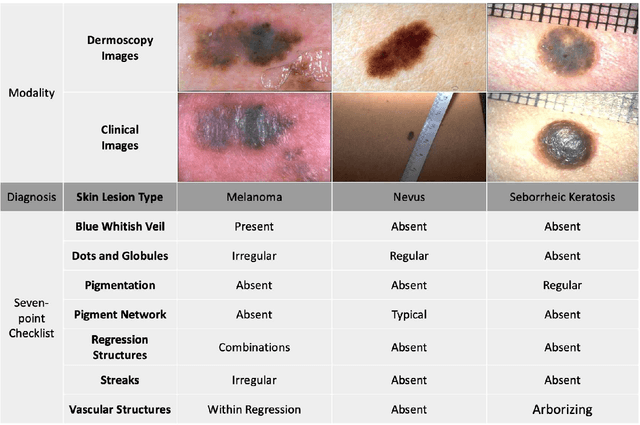
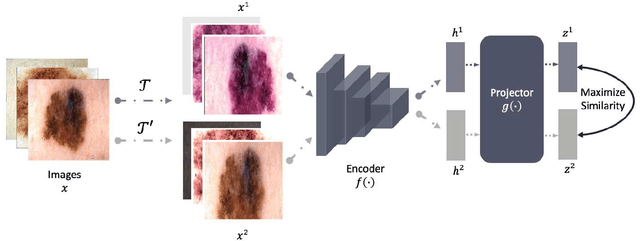
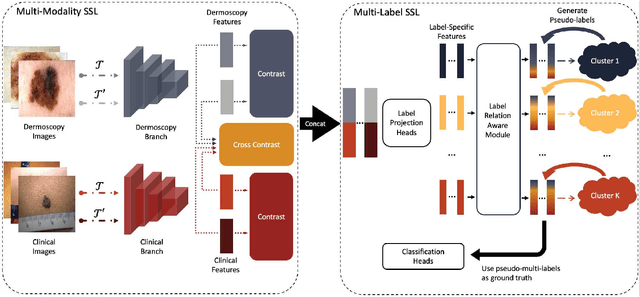
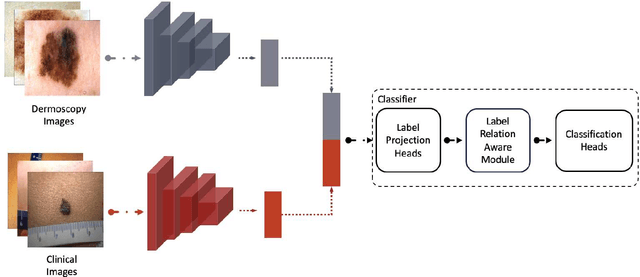
The clinical diagnosis of skin lesion involves the analysis of dermoscopic and clinical modalities. Dermoscopic images provide a detailed view of the surface structures whereas clinical images offer a complementary macroscopic information. The visual diagnosis of melanoma is also based on seven-point checklist which involves identifying different visual attributes. Recently, supervised learning approaches such as convolutional neural networks (CNNs) have shown great performances using both dermoscopic and clinical modalities (Multi-modality). The seven different visual attributes in the checklist are also used to further improve the the diagnosis. The performances of these approaches, however, are still reliant on the availability of large-scaled labeled data. The acquisition of annotated dataset is an expensive and time-consuming task, more so with annotating multi-attributes. To overcome this limitation, we propose a self-supervised learning (SSL) algorithm for multi-modality skin lesion classification. Our algorithm enables the multi-modality learning by maximizing the similarities between paired dermoscopic and clinical images from different views. In addition, we generate surrogate pseudo-multi-labels that represent seven attributes via clustering analysis. We also propose a label-relation-aware module to refine each pseudo-label embedding and capture the interrelationships between pseudo-multi-labels. We validated the effectiveness of our algorithm using well-benchmarked seven-point skin lesion dataset. Our results show that our algorithm achieved better performances than other state-of-the-art SSL counterparts.
Online Decision Mediation
Oct 28, 2023
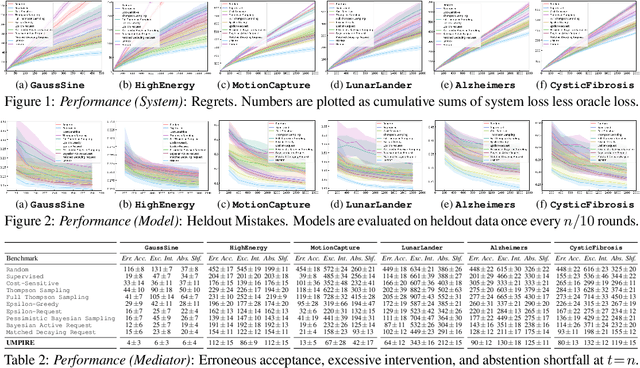
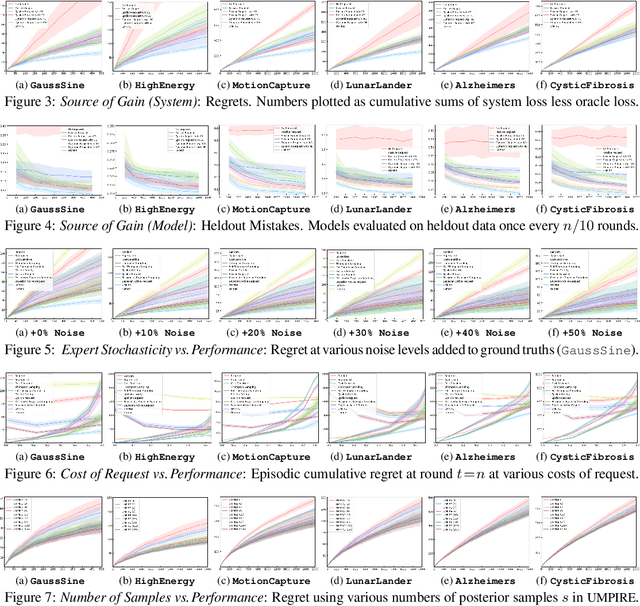
Consider learning a decision support assistant to serve as an intermediary between (oracle) expert behavior and (imperfect) human behavior: At each time, the algorithm observes an action chosen by a fallible agent, and decides whether to *accept* that agent's decision, *intervene* with an alternative, or *request* the expert's opinion. For instance, in clinical diagnosis, fully-autonomous machine behavior is often beyond ethical affordances, thus real-world decision support is often limited to monitoring and forecasting. Instead, such an intermediary would strike a prudent balance between the former (purely prescriptive) and latter (purely descriptive) approaches, while providing an efficient interface between human mistakes and expert feedback. In this work, we first formalize the sequential problem of *online decision mediation* -- that is, of simultaneously learning and evaluating mediator policies from scratch with *abstentive feedback*: In each round, deferring to the oracle obviates the risk of error, but incurs an upfront penalty, and reveals the otherwise hidden expert action as a new training data point. Second, we motivate and propose a solution that seeks to trade off (immediate) loss terms against (future) improvements in generalization error; in doing so, we identify why conventional bandit algorithms may fail. Finally, through experiments and sensitivities on a variety of datasets, we illustrate consistent gains over applicable benchmarks on performance measures with respect to the mediator policy, the learned model, and the decision-making system as a whole.
Course Correcting Koopman Representations
Oct 23, 2023Koopman representations aim to learn features of nonlinear dynamical systems (NLDS) which lead to linear dynamics in the latent space. Theoretically, such features can be used to simplify many problems in modeling and control of NLDS. In this work we study autoencoder formulations of this problem, and different ways they can be used to model dynamics, specifically for future state prediction over long horizons. We discover several limitations of predicting future states in the latent space and propose an inference-time mechanism, which we refer to as Periodic Reencoding, for faithfully capturing long term dynamics. We justify this method both analytically and empirically via experiments in low and high dimensional NLDS.
Spike Accumulation Forwarding for Effective Training of Spiking Neural Networks
Oct 16, 2023In this article, we propose a new paradigm for training spiking neural networks (SNNs), spike accumulation forwarding (SAF). It is known that SNNs are energy-efficient but difficult to train. Consequently, many researchers have proposed various methods to solve this problem, among which online training through time (OTTT) is a method that allows inferring at each time step while suppressing the memory cost. However, to compute efficiently on GPUs, OTTT requires operations with spike trains and weighted summation of spike trains during forwarding. In addition, OTTT has shown a relationship with the Spike Representation, an alternative training method, though theoretical agreement with Spike Representation has yet to be proven. Our proposed method can solve these problems; namely, SAF can halve the number of operations during the forward process, and it can be theoretically proven that SAF is consistent with the Spike Representation and OTTT, respectively. Furthermore, we confirmed the above contents through experiments and showed that it is possible to reduce memory and training time while maintaining accuracy.
Every Parameter Matters: Ensuring the Convergence of Federated Learning with Dynamic Heterogeneous Models Reduction
Oct 26, 2023Cross-device Federated Learning (FL) faces significant challenges where low-end clients that could potentially make unique contributions are excluded from training large models due to their resource bottlenecks. Recent research efforts have focused on model-heterogeneous FL, by extracting reduced-size models from the global model and applying them to local clients accordingly. Despite the empirical success, general theoretical guarantees of convergence on this method remain an open question. This paper presents a unifying framework for heterogeneous FL algorithms with online model extraction and provides a general convergence analysis for the first time. In particular, we prove that under certain sufficient conditions and for both IID and non-IID data, these algorithms converge to a stationary point of standard FL for general smooth cost functions. Moreover, we introduce the concept of minimum coverage index, together with model reduction noise, which will determine the convergence of heterogeneous federated learning, and therefore we advocate for a holistic approach that considers both factors to enhance the efficiency of heterogeneous federated learning.