 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hybrid quantum image classification and federated learning for hepatic steatosis diagnosis
Nov 04, 2023
With the maturity achieved by deep learning techniques, intelligent systems that can assist physicians in the daily interpretation of clinical images can play a very important role. In addition, quantum techniques applied to deep learning can enhance this performance, and federated learning techniques can realize privacy-friendly collaborative learning among different participants, solving privacy issues due to the use of sensitive data and reducing the number of data to be collected for each individual participant. We present in this study a hybrid quantum neural network that can be used to quantify non-alcoholic liver steatosis and could be useful in the diagnostic process to determine a liver's suitability for transplantation; at the same time, we propose a federated learning approach based on a classical deep learning solution to solve the same problem, but using a reduced data set in each part. The liver steatosis image classification accuracy of the hybrid quantum neural network, the hybrid quantum ResNet model, consisted of 5 qubits and more than 100 variational gates, reaches 97%, which is 1.8% higher than its classical counterpart, ResNet. Crucially, that even with a reduced dataset, our hybrid approach consistently outperformed its classical counterpart, indicating superior generalization and less potential for overfitting in medical applications. In addition, a federated approach with multiple clients, up to 32, despite the lower accuracy, but still higher than 90%, would allow using, for each participant, a very small dataset, i.e., up to one-thirtieth. Our work, based over real-word clinical data can be regarded as a scalable and collaborative starting point, could thus fulfill the need for an effective and reliable computer-assisted system that facilitates the daily diagnostic work of the clinical pathologist.
Spatiotemporal Attention Enhances Lidar-Based Robot Navigation in Dynamic Environments
Oct 30, 2023Foresighted robot navigation in dynamic indoor environments with cost-efficient hardware necessitates the use of a lightweight yet dependable controller. So inferring the scene dynamics from sensor readings without explicit object tracking is a pivotal aspect of foresighted navigation among pedestrians. In this paper, we introduce a spatiotemporal attention pipeline for enhanced navigation based on 2D lidar sensor readings. This pipeline is complemented by a novel lidar-state representation that emphasizes dynamic obstacles over static ones. Subsequently, the attention mechanism enables selective scene perception across both space and time, resulting in improved overall navigation performance within dynamic scenarios. We thoroughly evaluated the approach in different scenarios and simulators, finding good generalization to unseen environments. The results demonstrate outstanding performance compared to state-of-the-art methods, thereby enabling the seamless deployment of the learned controller on a real robot.
Deep Kalman Filters Can Filter
Oct 30, 2023Deep Kalman filters (DKFs) are a class of neural network models that generate Gaussian probability measures from sequential data. Though DKFs are inspired by the Kalman filter, they lack concrete theoretical ties to the stochastic filtering problem, thus limiting their applicability to areas where traditional model-based filters have been used, e.g.\ model calibration for bond and option prices in mathematical finance. We address this issue in the mathematical foundations of deep learning by exhibiting a class of continuous-time DKFs which can approximately implement the conditional law of a broad class of non-Markovian and conditionally Gaussian signal processes given noisy continuous-times measurements. Our approximation results hold uniformly over sufficiently regular compact subsets of paths, where the approximation error is quantified by the worst-case 2-Wasserstein distance computed uniformly over the given compact set of paths.
Metric Flows with Neural Networks
Oct 30, 2023We develop a theory of flows in the space of Riemannian metrics induced by neural network gradient descent. This is motivated in part by recent advances in approximating Calabi-Yau metrics with neural networks and is enabled by recent advances in understanding flows in the space of neural networks. We derive the corresponding metric flow equations, which are governed by a metric neural tangent kernel, a complicated, non-local object that evolves in time. However, many architectures admit an infinite-width limit in which the kernel becomes fixed and the dynamics simplify. Additional assumptions can induce locality in the flow, which allows for the realization of Perelman's formulation of Ricci flow that was used to resolve the 3d Poincar\'e conjecture. We apply these ideas to numerical Calabi-Yau metrics, including a discussion on the importance of feature learning.
Score Matching-based Pseudolikelihood Estimation of Neural Marked Spatio-Temporal Point Process with Uncertainty Quantification
Oct 25, 2023Spatio-temporal point processes (STPPs) are potent mathematical tools for modeling and predicting events with both temporal and spatial features. Despite their versatility, most existing methods for learning STPPs either assume a restricted form of the spatio-temporal distribution, or suffer from inaccurate approximations of the intractable integral in the likelihood training objective. These issues typically arise from the normalization term of the probability density function. Moreover, current techniques fail to provide uncertainty quantification for model predictions, such as confidence intervals for the predicted event's arrival time and confidence regions for the event's location, which is crucial given the considerable randomness of the data. To tackle these challenges, we introduce SMASH: a Score MAtching-based pSeudolikeliHood estimator for learning marked STPPs with uncertainty quantification. Specifically, our framework adopts a normalization-free objective by estimating the pseudolikelihood of marked STPPs through score-matching and offers uncertainty quantification for the predicted event time, location and mark by computing confidence regions over the generated samples. The superior performance of our proposed framework is demonstrated through extensive experiments in both event prediction and uncertainty quantification.
Using Causality-Aware Graph Neural Networks to Predict Temporal Centralities in Dynamic Graphs
Oct 24, 2023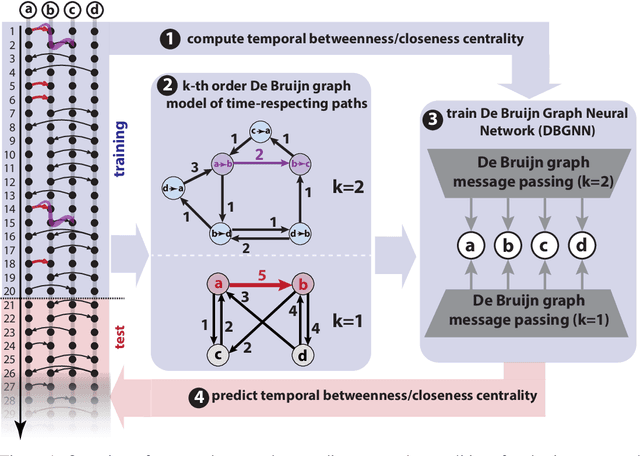
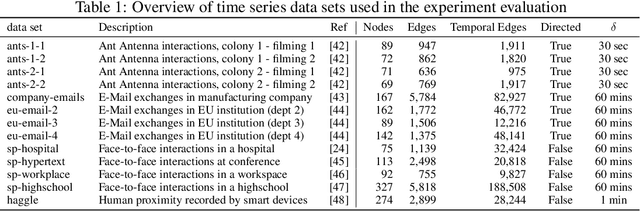
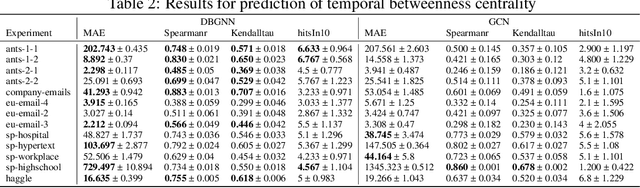
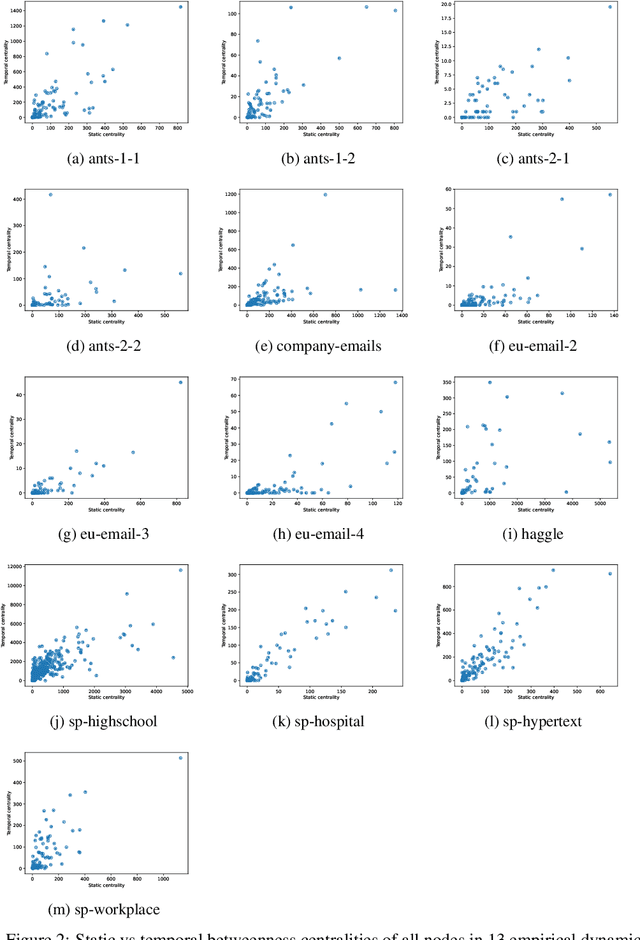
Node centralities play a pivotal role in network science, social network analysis, and recommender systems. In temporal data, static path-based centralities like closeness or betweenness can give misleading results about the true importance of nodes in a temporal graph. To address this issue, temporal generalizations of betweenness and closeness have been defined that are based on the shortest time-respecting paths between pairs of nodes. However, a major issue of those generalizations is that the calculation of such paths is computationally expensive. Addressing this issue, we study the application of De Bruijn Graph Neural Networks (DBGNN), a causality-aware graph neural network architecture, to predict temporal path-based centralities in time series data. We experimentally evaluate our approach in 13 temporal graphs from biological and social systems and show that it considerably improves the prediction of both betweenness and closeness centrality compared to a static Graph Convolutional Neural Network.
An Improved Transformer-based Model for Detecting Phishing, Spam, and Ham: A Large Language Model Approach
Nov 01, 2023Phishing and spam detection is long standing challenge that has been the subject of much academic research. Large Language Models (LLM) have vast potential to transform society and provide new and innovative approaches to solve well-established challenges. Phishing and spam have caused financial hardships and lost time and resources to email users all over the world and frequently serve as an entry point for ransomware threat actors. While detection approaches exist, especially heuristic-based approaches, LLMs offer the potential to venture into a new unexplored area for understanding and solving this challenge. LLMs have rapidly altered the landscape from business, consumers, and throughout academia and demonstrate transformational potential for the potential of society. Based on this, applying these new and innovative approaches to email detection is a rational next step in academic research. In this work, we present IPSDM, our model based on fine-tuning the BERT family of models to specifically detect phishing and spam email. We demonstrate our fine-tuned version, IPSDM, is able to better classify emails in both unbalanced and balanced datasets. This work serves as an important first step towards employing LLMs to improve the security of our information systems.
Rethinking Decision Transformer via Hierarchical Reinforcement Learning
Nov 01, 2023Decision Transformer (DT) is an innovative algorithm leveraging recent advances of the transformer architecture in reinforcement learning (RL). However, a notable limitation of DT is its reliance on recalling trajectories from datasets, losing the capability to seamlessly stitch sub-optimal trajectories together. In this work we introduce a general sequence modeling framework for studying sequential decision making through the lens of Hierarchical RL. At the time of making decisions, a high-level policy first proposes an ideal prompt for the current state, a low-level policy subsequently generates an action conditioned on the given prompt. We show DT emerges as a special case of this framework with certain choices of high-level and low-level policies, and discuss the potential failure of these choices. Inspired by these observations, we study how to jointly optimize the high-level and low-level policies to enable the stitching ability, which further leads to the development of new offline RL algorithms. Our empirical results clearly show that the proposed algorithms significantly surpass DT on several control and navigation benchmarks. We hope our contributions can inspire the integration of transformer architectures within the field of RL.
Semantic Hearing: Programming Acoustic Scenes with Binaural Hearables
Nov 01, 2023Imagine being able to listen to the birds chirping in a park without hearing the chatter from other hikers, or being able to block out traffic noise on a busy street while still being able to hear emergency sirens and car honks. We introduce semantic hearing, a novel capability for hearable devices that enables them to, in real-time, focus on, or ignore, specific sounds from real-world environments, while also preserving the spatial cues. To achieve this, we make two technical contributions: 1) we present the first neural network that can achieve binaural target sound extraction in the presence of interfering sounds and background noise, and 2) we design a training methodology that allows our system to generalize to real-world use. Results show that our system can operate with 20 sound classes and that our transformer-based network has a runtime of 6.56 ms on a connected smartphone. In-the-wild evaluation with participants in previously unseen indoor and outdoor scenarios shows that our proof-of-concept system can extract the target sounds and generalize to preserve the spatial cues in its binaural output. Project page with code: https://semantichearing.cs.washington.edu
Generating HSR Bogie Vibration Signals via Pulse Voltage-Guided Conditional Diffusion Model
Nov 01, 2023Generative Adversarial Networks (GANs) for producing realistic signals, have substantially improved fault diagnosis algorithms in various Internet of Things (IoT) systems. However, challenges such as training instability and dynamical inaccuracy limit their utility in high-speed rail (HSR) bogie fault diagnosis. To address these challenges, we introduce the Pulse Voltage-Guided Conditional Diffusion Model (VGCDM). Unlike traditional implicit GANs, VGCDM adopts a sequential U-Net architecture, facilitating multi-phase denoising diffusion for generation, which bolsters training stability and mitigate convergence issues. VGCDM also incorporates control pulse voltage by cross-attention mechanism to ensure the alignment of vibration with voltage signals, enhancing the Conditional Diffusion Model's progressive controlablity. Consequently, solely straightforward sampling of control voltages, ensuring the efficient transformation from Gaussian Noise to vibration signals. This adaptability remains robust even in scenarios with time-varying speeds. To validate the effectiveness, we conducted two case studies using SQ dataset and high-simulation HSR bogie dataset. The results of our experiments unequivocally confirm that VGCDM outperforms other generative models, achieving the best RSME, PSNR, and FSCS, showing its superiority in conditional HSR bogie vibration signal generation. For access, our code is available at https://github.com/xuanliu2000/VGCDM.