 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Fairness ROAD: Robust Optimization for Adversarial Debiasing
Oct 27, 2023
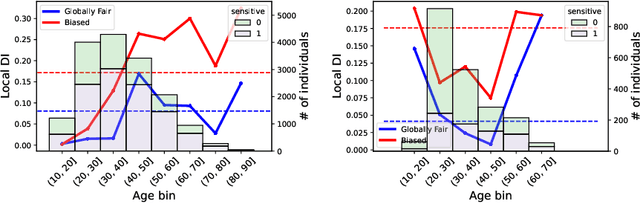
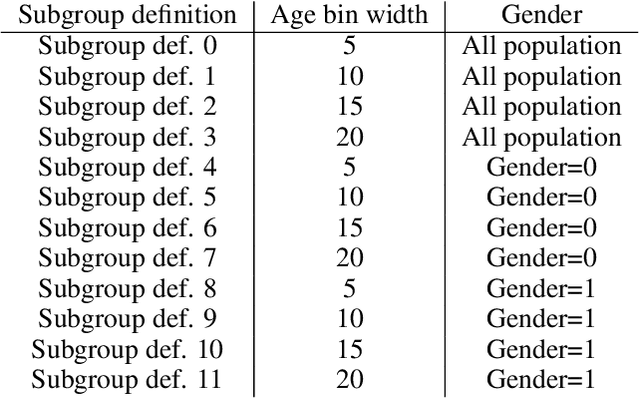
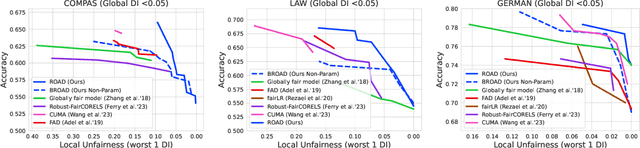
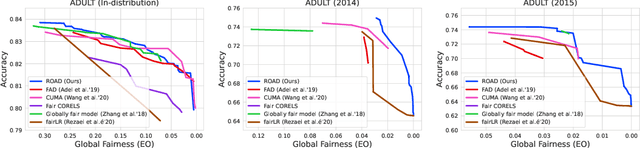
In the field of algorithmic fairness, significant attention has been put on group fairness criteria, such as Demographic Parity and Equalized Odds. Nevertheless, these objectives, measured as global averages, have raised concerns about persistent local disparities between sensitive groups. In this work, we address the problem of local fairness, which ensures that the predictor is unbiased not only in terms of expectations over the whole population, but also within any subregion of the feature space, unknown at training time. To enforce this objective, we introduce ROAD, a novel approach that leverages the Distributionally Robust Optimization (DRO) framework within a fair adversarial learning objective, where an adversary tries to infer the sensitive attribute from the predictions. Using an instance-level re-weighting strategy, ROAD is designed to prioritize inputs that are likely to be locally unfair, i.e. where the adversary faces the least difficulty in reconstructing the sensitive attribute. Numerical experiments demonstrate the effectiveness of our method: it achieves Pareto dominance with respect to local fairness and accuracy for a given global fairness level across three standard datasets, and also enhances fairness generalization under distribution shift.
$α$-Mutual Information: A Tunable Privacy Measure for Privacy Protection in Data Sharing
Oct 27, 2023This paper adopts Arimoto's $\alpha$-Mutual Information as a tunable privacy measure, in a privacy-preserving data release setting that aims to prevent disclosing private data to adversaries. By fine-tuning the privacy metric, we demonstrate that our approach yields superior models that effectively thwart attackers across various performance dimensions. We formulate a general distortion-based mechanism that manipulates the original data to offer privacy protection. The distortion metrics are determined according to the data structure of a specific experiment. We confront the problem expressed in the formulation by employing a general adversarial deep learning framework that consists of a releaser and an adversary, trained with opposite goals. This study conducts empirical experiments on images and time-series data to verify the functionality of $\alpha$-Mutual Information. We evaluate the privacy-utility trade-off of customized models and compare them to mutual information as the baseline measure. Finally, we analyze the consequence of an attacker's access to side information about private data and witness that adapting the privacy measure results in a more refined model than the state-of-the-art in terms of resiliency against side information.
A Scalable Framework for Table of Contents Extraction from Complex ESG Annual Reports
Oct 27, 2023Table of contents (ToC) extraction centres on structuring documents in a hierarchical manner. In this paper, we propose a new dataset, ESGDoc, comprising 1,093 ESG annual reports from 563 companies spanning from 2001 to 2022. These reports pose significant challenges due to their diverse structures and extensive length. To address these challenges, we propose a new framework for Toc extraction, consisting of three steps: (1) Constructing an initial tree of text blocks based on reading order and font sizes; (2) Modelling each tree node (or text block) independently by considering its contextual information captured in node-centric subtree; (3) Modifying the original tree by taking appropriate action on each tree node (Keep, Delete, or Move). This construction-modelling-modification (CMM) process offers several benefits. It eliminates the need for pairwise modelling of section headings as in previous approaches, making document segmentation practically feasible. By incorporating structured information, each section heading can leverage both local and long-distance context relevant to itself. Experimental results show that our approach outperforms the previous state-of-the-art baseline with a fraction of running time. Our framework proves its scalability by effectively handling documents of any length.
Optimal Best Arm Identification with Fixed Confidence in Restless Bandits
Oct 20, 2023We study best arm identification in a restless multi-armed bandit setting with finitely many arms. The discrete-time data generated by each arm forms a homogeneous Markov chain taking values in a common, finite state space. The state transitions in each arm are captured by an ergodic transition probability matrix (TPM) that is a member of a single-parameter exponential family of TPMs. The real-valued parameters of the arm TPMs are unknown and belong to a given space. Given a function $f$ defined on the common state space of the arms, the goal is to identify the best arm -- the arm with the largest average value of $f$ evaluated under the arm's stationary distribution -- with the fewest number of samples, subject to an upper bound on the decision's error probability (i.e., the fixed-confidence regime). A lower bound on the growth rate of the expected stopping time is established in the asymptote of a vanishing error probability. Furthermore, a policy for best arm identification is proposed, and its expected stopping time is proved to have an asymptotic growth rate that matches the lower bound. It is demonstrated that tracking the long-term behavior of a certain Markov decision process and its state-action visitation proportions are the key ingredients in analyzing the converse and achievability bounds. It is shown that under every policy, the state-action visitation proportions satisfy a specific approximate flow conservation constraint and that these proportions match the optimal proportions dictated by the lower bound under any asymptotically optimal policy. The prior studies on best arm identification in restless bandits focus on independent observations from the arms, rested Markov arms, and restless Markov arms with known arm TPMs. In contrast, this work is the first to study best arm identification in restless bandits with unknown arm TPMs.
BayOTIDE: Bayesian Online Multivariate Time series Imputation with functional decomposition
Aug 28, 2023
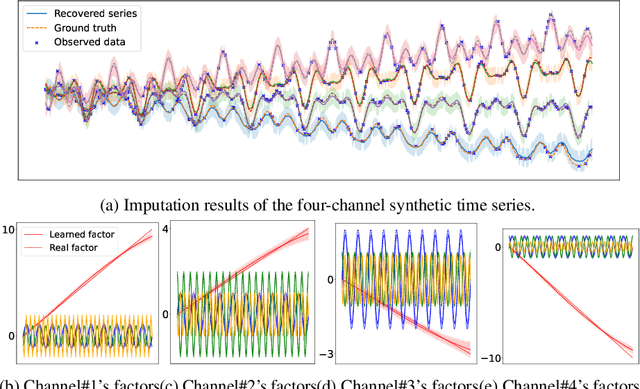
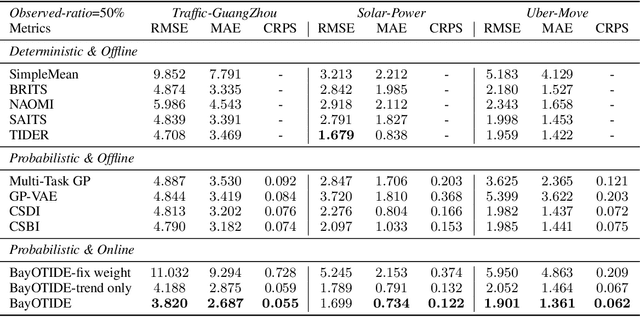
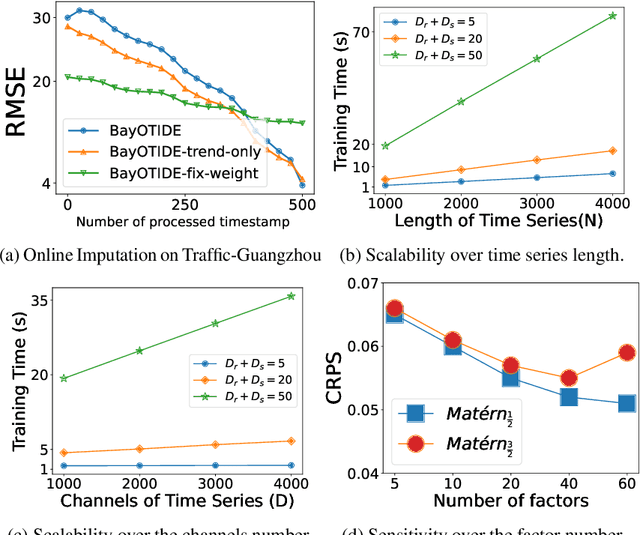
In real-world scenarios like traffic and energy, massive time-series data with missing values and noises are widely observed, even sampled irregularly. While many imputation methods have been proposed, most of them work with a local horizon, which means models are trained by splitting the long sequence into batches of fit-sized patches. This local horizon can make models ignore global trends or periodic patterns. More importantly, almost all methods assume the observations are sampled at regular time stamps, and fail to handle complex irregular sampled time series arising from different applications. Thirdly, most existing methods are learned in an offline manner. Thus, it is not suitable for many applications with fast-arriving streaming data. To overcome these limitations, we propose \ours: Bayesian Online Multivariate Time series Imputation with functional decomposition. We treat the multivariate time series as the weighted combination of groups of low-rank temporal factors with different patterns. We apply a group of Gaussian Processes (GPs) with different kernels as functional priors to fit the factors. For computational efficiency, we further convert the GPs into a state-space prior by constructing an equivalent stochastic differential equation (SDE), and developing a scalable algorithm for online inference. The proposed method can not only handle imputation over arbitrary time stamps, but also offer uncertainty quantification and interpretability for the downstream application. We evaluate our method on both synthetic and real-world datasets.
Parallel compressive super-resolution imaging with wide field-of-view based on physics enhanced network
Oct 20, 2023Achieving both high-performance and wide field-of-view (FOV) super-resolution imaging has been attracting increasing attention in recent years. However, such goal suffers from long reconstruction time and huge storage space. Parallel compressive imaging (PCI) provides an efficient solution, but the super-resolution quality and imaging speed are strongly dependent on precise optical transfer function (OTF), modulation masks and reconstruction algorithm. In this work, we propose a wide FOV parallel compressive super-resolution imaging approach based on physics enhanced network. By training the network with the prior OTF of an arbitrary 128x128-pixel region and fine-tuning the network with other OTFs within rest regions of FOV, we realize both mask optimization and super-resolution imaging with up to 1020x1500 wide FOV. Numerical simulations and practical experiments demonstrate the effectiveness and superiority of the proposed approach. We achieve high-quality reconstruction with 4x4 times super-resolution enhancement using only three designed masks to reach real-time imaging speed. The proposed approach promotes the technology of rapid imaging for super-resolution and wide FOV, ranging from infrared to Terahertz.
NP-SBFL: Bridging the Gap Between Spectrum-Based Fault Localization and Faulty Neural Pathways Diagnosis
Oct 29, 2023Deep learning has revolutionized various real-world applications, but the quality of Deep Neural Networks (DNNs) remains a concern. DNNs are complex and have millions of parameters, making it difficult to determine their contributions to fulfilling a task. Moreover, the behavior of a DNN is highly influenced by the data used during training, making it challenging to collect enough data to exercise all potential DNN behavior under all possible scenarios. This paper proposes a novel NP-SBFL method that adapts spectrum-based fault localization (SBFL) to locate faulty neural pathways. Our method identifies critical neurons using the layer-wise relevance propagation (LRP) technique and determines which critical neurons are faulty. We propose a multi-stage gradient ascent (MGA), an extension of gradient ascent, to effectively activate a sequence of neurons one at a time while maintaining the activation of previous neurons. We evaluated the effectiveness of our method on two commonly used datasets, MNIST and CIFAR-10, two baselines DeepFault and NP-SBFL-GA, and three suspicious neuron measures, Tarantula, Ochiai, and Barinel. The empirical results showed that NP-SBFL-MGA is statistically more effective than the baselines at identifying suspicious paths and synthesizing adversarial inputs. Particularly, Tarantula on NP-SBFL-MGA had the highest fault detection rate at 96.75%, surpassing DeepFault on Ochiai (89.90%) and NP-SBFL-GA on Ochiai (60.61%). Our approach also yielded comparable results to the baselines in synthesizing naturalness inputs, and we found a positive correlation between the coverage of critical paths and the number of failed tests in DNN fault localization.
A Co-training Approach for Noisy Time Series Learning
Aug 24, 2023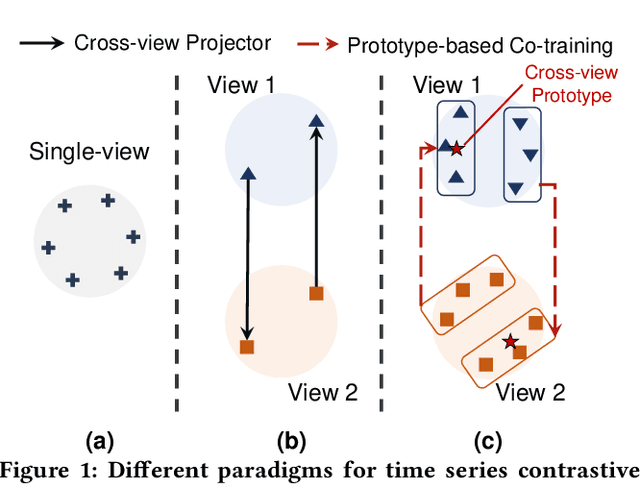
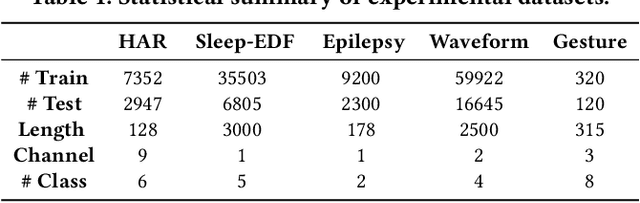
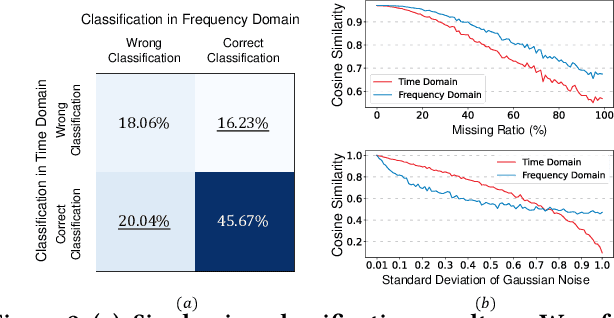
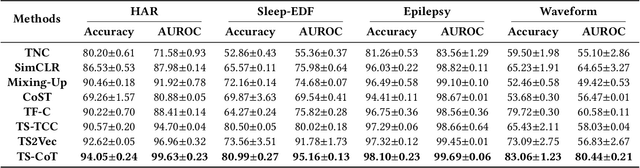
In this work, we focus on robust time series representation learning. Our assumption is that real-world time series is noisy and complementary information from different views of the same time series plays an important role while analyzing noisy input. Based on this, we create two views for the input time series through two different encoders. We conduct co-training based contrastive learning iteratively to learn the encoders. Our experiments demonstrate that this co-training approach leads to a significant improvement in performance. Especially, by leveraging the complementary information from different views, our proposed TS-CoT method can mitigate the impact of data noise and corruption. Empirical evaluations on four time series benchmarks in unsupervised and semi-supervised settings reveal that TS-CoT outperforms existing methods. Furthermore, the representations learned by TS-CoT can transfer well to downstream tasks through fine-tuning.
Joint Localization and Communication Enhancement in Uplink Integrated Sensing and Communications System with Clock Asynchronism
Oct 28, 2023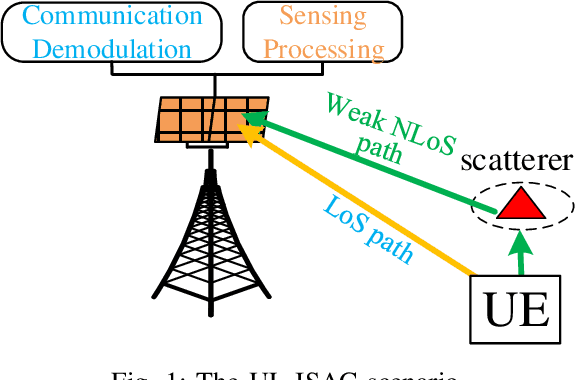
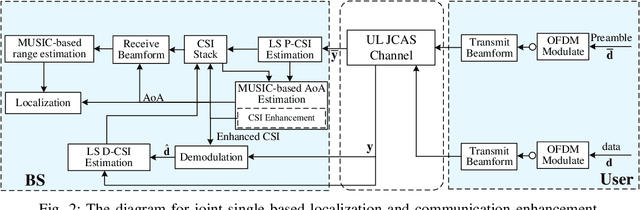
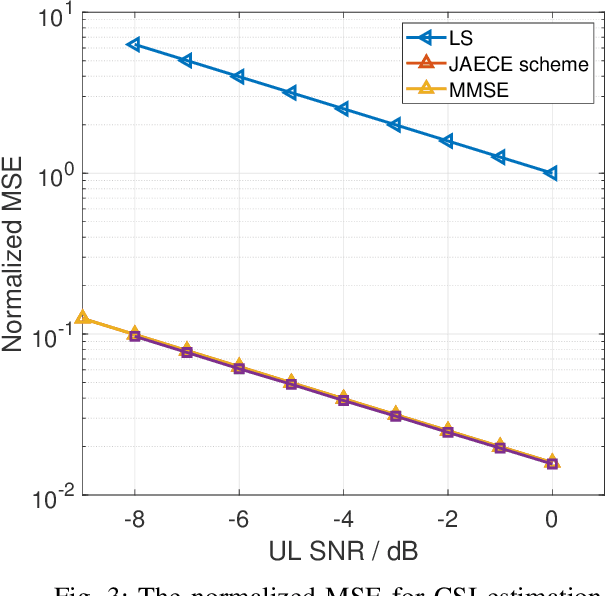
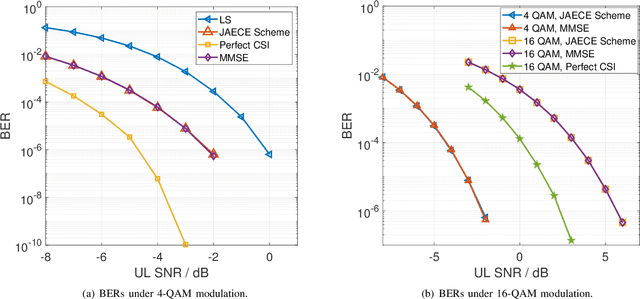
In this paper, we propose a joint single-base localization and communication enhancement scheme for the uplink (UL) integrated sensing and communications (ISAC) system with asynchronism, which can achieve accurate single-base localization of user equipment (UE) and significantly improve the communication reliability despite the existence of timing offset (TO) due to the clock asynchronism between UE and base station (BS). Our proposed scheme integrates the CSI enhancement into the multiple signal classification (MUSIC)-based AoA estimation and thus imposes no extra complexity on the ISAC system. We further exploit a MUSIC-based range estimation method and prove that it can suppress the time-varying TO-related phase terms. Exploiting the AoA and range estimation of UE, we can estimate the location of UE. Finally, we propose a joint CSI and data signals-based localization scheme that can coherently exploit the data and the CSI signals to improve the AoA and range estimation, which further enhances the single-base localization of UE. The extensive simulation results show that the enhanced CSI can achieve equivalent bit error rate performance to the minimum mean square error (MMSE) CSI estimator. The proposed joint CSI and data signals-based localization scheme can achieve decimeter-level localization accuracy despite the existing clock asynchronism and improve the localization mean square error (MSE) by about 8 dB compared with the maximum likelihood (ML)-based benchmark method.
Self-Supervised Multi-Modality Learning for Multi-Label Skin Lesion Classification
Oct 28, 2023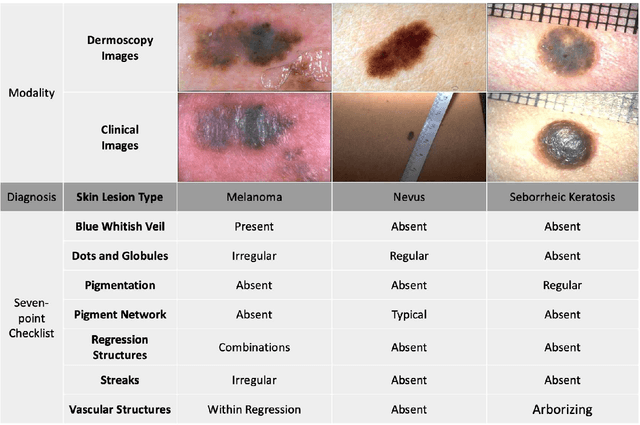
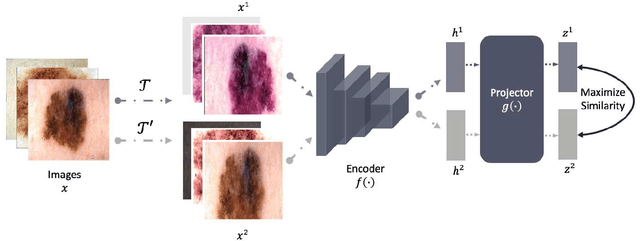
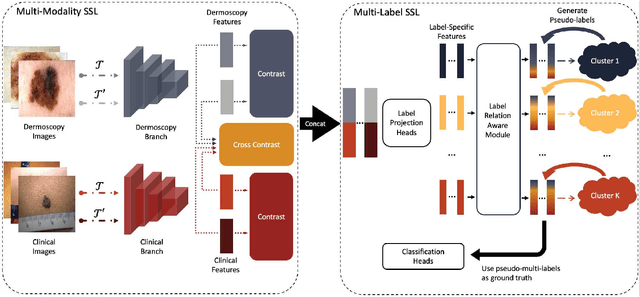
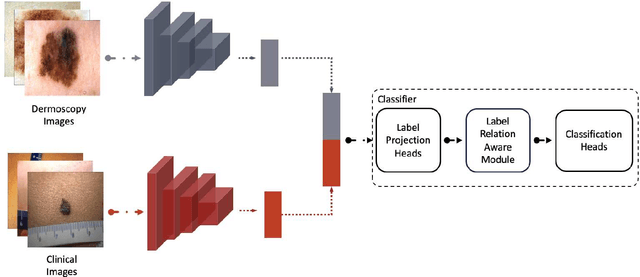
The clinical diagnosis of skin lesion involves the analysis of dermoscopic and clinical modalities. Dermoscopic images provide a detailed view of the surface structures whereas clinical images offer a complementary macroscopic information. The visual diagnosis of melanoma is also based on seven-point checklist which involves identifying different visual attributes. Recently, supervised learning approaches such as convolutional neural networks (CNNs) have shown great performances using both dermoscopic and clinical modalities (Multi-modality). The seven different visual attributes in the checklist are also used to further improve the the diagnosis. The performances of these approaches, however, are still reliant on the availability of large-scaled labeled data. The acquisition of annotated dataset is an expensive and time-consuming task, more so with annotating multi-attributes. To overcome this limitation, we propose a self-supervised learning (SSL) algorithm for multi-modality skin lesion classification. Our algorithm enables the multi-modality learning by maximizing the similarities between paired dermoscopic and clinical images from different views. In addition, we generate surrogate pseudo-multi-labels that represent seven attributes via clustering analysis. We also propose a label-relation-aware module to refine each pseudo-label embedding and capture the interrelationships between pseudo-multi-labels. We validated the effectiveness of our algorithm using well-benchmarked seven-point skin lesion dataset. Our results show that our algorithm achieved better performances than other state-of-the-art SSL counterparts.