 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Arbitrarily Scalable Environment Generators via Neural Cellular Automata
Oct 28, 2023
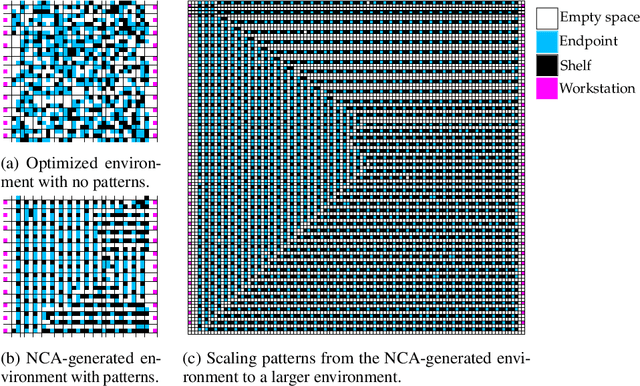

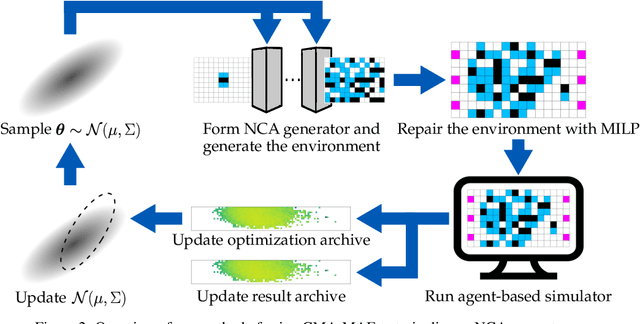
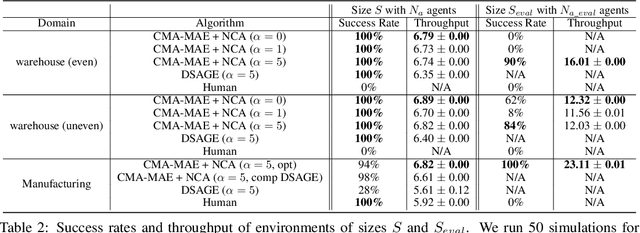
We study the problem of generating arbitrarily large environments to improve the throughput of multi-robot systems. Prior work proposes Quality Diversity (QD) algorithms as an effective method for optimizing the environments of automated warehouses. However, these approaches optimize only relatively small environments, falling short when it comes to replicating real-world warehouse sizes. The challenge arises from the exponential increase in the search space as the environment size increases. Additionally, the previous methods have only been tested with up to 350 robots in simulations, while practical warehouses could host thousands of robots. In this paper, instead of optimizing environments, we propose to optimize Neural Cellular Automata (NCA) environment generators via QD algorithms. We train a collection of NCA generators with QD algorithms in small environments and then generate arbitrarily large environments from the generators at test time. We show that NCA environment generators maintain consistent, regularized patterns regardless of environment size, significantly enhancing the scalability of multi-robot systems in two different domains with up to 2,350 robots. Additionally, we demonstrate that our method scales a single-agent reinforcement learning policy to arbitrarily large environments with similar patterns. We include the source code at \url{https://github.com/lunjohnzhang/warehouse_env_gen_nca_public}.
Customizing 360-Degree Panoramas through Text-to-Image Diffusion Models
Oct 28, 2023Personalized text-to-image (T2I) synthesis based on diffusion models has attracted significant attention in recent research. However, existing methods primarily concentrate on customizing subjects or styles, neglecting the exploration of global geometry. In this study, we propose an approach that focuses on the customization of 360-degree panoramas, which inherently possess global geometric properties, using a T2I diffusion model. To achieve this, we curate a paired image-text dataset specifically designed for the task and subsequently employ it to fine-tune a pre-trained T2I diffusion model with LoRA. Nevertheless, the fine-tuned model alone does not ensure the continuity between the leftmost and rightmost sides of the synthesized images, a crucial characteristic of 360-degree panoramas. To address this issue, we propose a method called StitchDiffusion. Specifically, we perform pre-denoising operations twice at each time step of the denoising process on the stitch block consisting of the leftmost and rightmost image regions. Furthermore, a global cropping is adopted to synthesize seamless 360-degree panoramas. Experimental results demonstrate the effectiveness of our customized model combined with the proposed StitchDiffusion in generating high-quality 360-degree panoramic images. Moreover, our customized model exhibits exceptional generalization ability in producing scenes unseen in the fine-tuning dataset. Code is available at https://github.com/littlewhitesea/StitchDiffusion.
Learning Efficient Surrogate Dynamic Models with Graph Spline Networks
Oct 25, 2023While complex simulations of physical systems have been widely used in engineering and scientific computing, lowering their often prohibitive computational requirements has only recently been tackled by deep learning approaches. In this paper, we present GraphSplineNets, a novel deep-learning method to speed up the forecasting of physical systems by reducing the grid size and number of iteration steps of deep surrogate models. Our method uses two differentiable orthogonal spline collocation methods to efficiently predict response at any location in time and space. Additionally, we introduce an adaptive collocation strategy in space to prioritize sampling from the most important regions. GraphSplineNets improve the accuracy-speedup tradeoff in forecasting various dynamical systems with increasing complexity, including the heat equation, damped wave propagation, Navier-Stokes equations, and real-world ocean currents in both regular and irregular domains.
Pilot-Based Uplink Power Control in Single-UE Massive MIMO Systems With 1-Bit ADCs
Oct 25, 2023We propose uplink power control (PC) methods for massive multiple-input multiple-output systems with 1-bit analog-to-digital converters, which are specifically tailored to address the non-monotonic data detection performance with respect to the transmit power of the user equipment (UE). Considering a single UE, we design a multi-amplitude pilot sequence to capture the aforementioned non-monotonicity, which is utilized at the base station to derive UE transmit power adjustments via single-shot or differential power control (DPC) techniques. Both methods enable closed-loop uplink PC using different feedback approaches. The single-shot method employs one-time multi-bit feedback, while the DPC method relies on continuous adjustments with 1-bit feedback. Numerical results demonstrate the superiority of the proposed schemes over conventional closed-loop uplink PC techniques.
A Unique Training Strategy to Enhance Language Models Capabilities for Health Mention Detection from Social Media Content
Oct 29, 2023An ever-increasing amount of social media content requires advanced AI-based computer programs capable of extracting useful information. Specifically, the extraction of health-related content from social media is useful for the development of diverse types of applications including disease spread, mortality rate prediction, and finding the impact of diverse types of drugs on diverse types of diseases. Language models are competent in extracting the syntactic and semantics of text. However, they face a hard time extracting similar patterns from social media texts. The primary reason for this shortfall lies in the non-standardized writing style commonly employed by social media users. Following the need for an optimal language model competent in extracting useful patterns from social media text, the key goal of this paper is to train language models in such a way that they learn to derive generalized patterns. The key goal is achieved through the incorporation of random weighted perturbation and contrastive learning strategies. On top of a unique training strategy, a meta predictor is proposed that reaps the benefits of 5 different language models for discriminating posts of social media text into non-health and health-related classes. Comprehensive experimentation across 3 public benchmark datasets reveals that the proposed training strategy improves the performance of the language models up to 3.87%, in terms of F1-score, as compared to their performance with traditional training. Furthermore, the proposed meta predictor outperforms existing health mention classification predictors across all 3 benchmark datasets.
Space-Time Shift Keying Aided OTFS Modulation for Orthogonal Multiple Access
Sep 07, 2023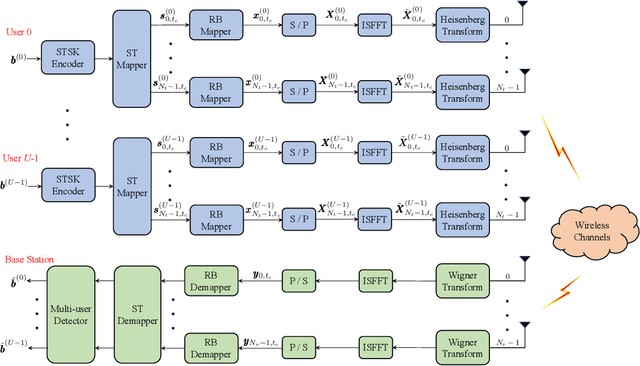
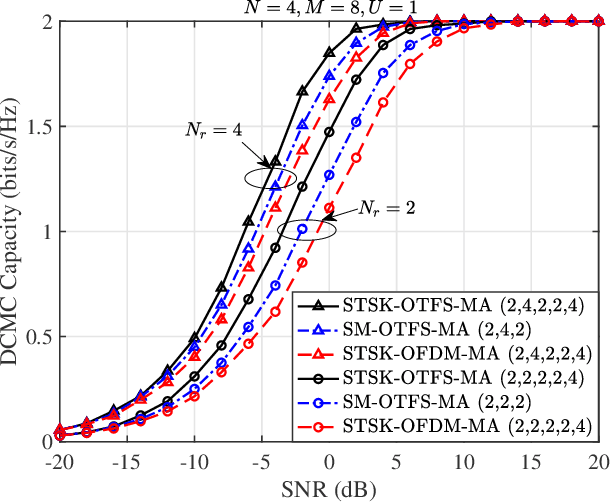
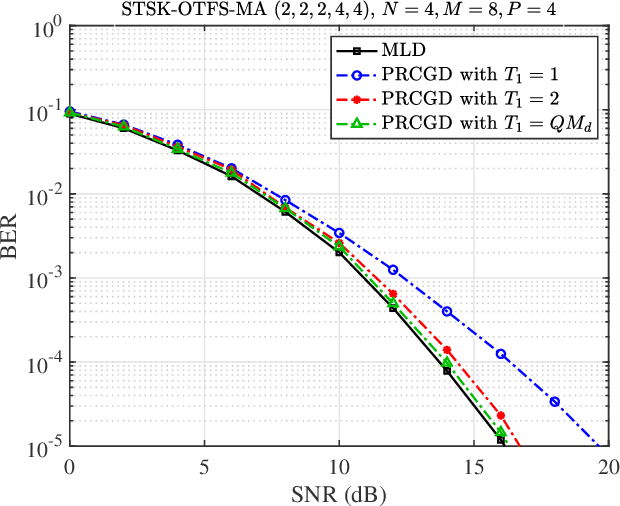
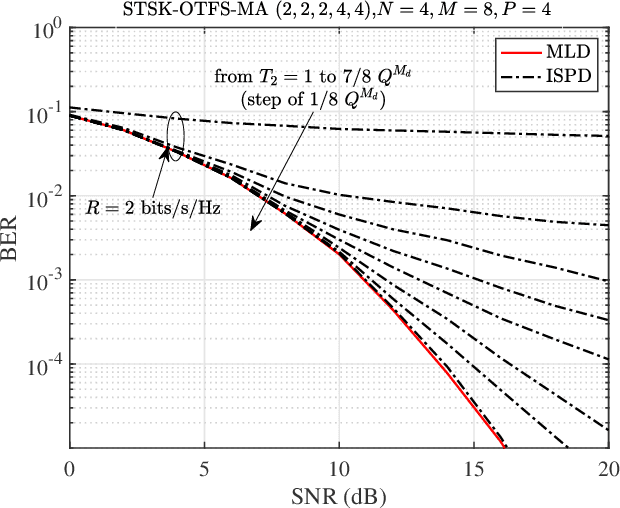
Space-time shift keying-aided orthogonal time frequency space modulation-based multiple access (STSK-OTFS-MA) is proposed for reliable uplink transmission in high-Doppler scenarios. As a beneficial feature of our STSK-OTFS-MA system, extra information bits are mapped onto the indices of the active dispersion matrices, which allows the system to enjoy the joint benefits of both STSK and OTFS signalling. Due to the fact that both the time-, space- and DD-domain degrees of freedom are jointly exploited, our STSK-OTFS-MA achieves increased diversity and coding gains. To mitigate the potentially excessive detection complexity, the sparse structure of the equivalent transmitted symbol vector is exploited, resulting in a pair of low-complexity near-maximum likelihood (ML) multiuser detection algorithms. Explicitly, we conceive a progressive residual check-based greedy detector (PRCGD) and an iterative reduced-space check-based detector (IRCD). Then, we derive both the unconditional single-user pairwise error probability (SU-UPEP) and a tight bit error ratio (BER) union-bound for our single-user STSK-OTFS-MA system employing the ML detector. Furthermore, the discrete-input continuous-output memoryless channel (DCMC) capacity of the proposed system is derived. The optimal dispersion matrices (DMs) are designed based on the maximum attainable diversity and coding gain metrics. Finally, it is demonstrated that our STSK-OTFS-MA system achieves both a lower BER and a higher DCMC capacity than its conventional spatial modulation (SM) {and its orthogonal frequency-division multiplexing (OFDM) counterparts. As a benefit, the proposed system strikes a compelling BER vs. system complexity as well as BER vs. detection complexity trade-offs.
Do Graph Neural Networks Dream of Landau Damping? Insights from Kinetic Simulations of a Plasma Sheet Model
Oct 26, 2023
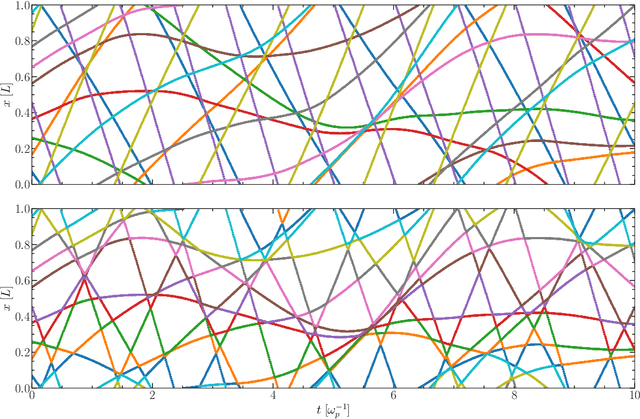
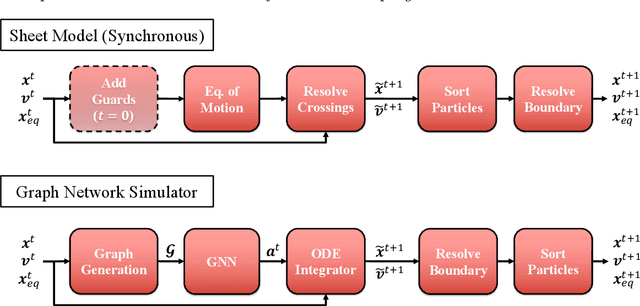

We explore the possibility of fully replacing a plasma physics kinetic simulator with a graph neural network-based simulator. We focus on this class of surrogate models given the similarity between their message-passing update mechanism and the traditional physics solver update, and the possibility of enforcing known physical priors into the graph construction and update. We show that our model learns the kinetic plasma dynamics of the one-dimensional plasma model, a predecessor of contemporary kinetic plasma simulation codes, and recovers a wide range of well-known kinetic plasma processes, including plasma thermalization, electrostatic fluctuations about thermal equilibrium, and the drag on a fast sheet and Landau damping. We compare the performance against the original plasma model in terms of run-time, conservation laws, and temporal evolution of key physical quantities. The limitations of the model are presented and possible directions for higher-dimensional surrogate models for kinetic plasmas are discussed.
Lightweight High-Speed and High-Force Gripper for Assembly
Oct 26, 2023This paper presents a novel industrial robotic gripper with a high grasping speed (maximum: 1396 mm/s), high tip force (maximum: 80 N) for grasping, large motion range, and lightweight design (0.3 kg). To realize these features, the high-speed section of the quick-return mechanism and load-sensitive continuously variable transmission mechanism are installed in the gripper. The gripper is also equipped with a self-centering function. The high grasping speed and self-centering function improve the cycle time in robotic operations. In addition, the high tip force is advantageous for stably grasping and assembling heavy objects. Moreover, the design of the gripper reduce the gripper's proportion of the manipulator's payload, thus increasing the weight of the object that can be grasped. The gripper performance was validated through kinematic and static analyses as well as experimental evaluations. This paper also presents the analysis of the self-centering function of the developed gripper.
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations
Oct 26, 2023Imitation learning from a large set of human demonstrations has proved to be an effective paradigm for building capable robot agents. However, the demonstrations can be extremely costly and time-consuming to collect. We introduce MimicGen, a system for automatically synthesizing large-scale, rich datasets from only a small number of human demonstrations by adapting them to new contexts. We use MimicGen to generate over 50K demonstrations across 18 tasks with diverse scene configurations, object instances, and robot arms from just ~200 human demonstrations. We show that robot agents can be effectively trained on this generated dataset by imitation learning to achieve strong performance in long-horizon and high-precision tasks, such as multi-part assembly and coffee preparation, across broad initial state distributions. We further demonstrate that the effectiveness and utility of MimicGen data compare favorably to collecting additional human demonstrations, making it a powerful and economical approach towards scaling up robot learning. Datasets, simulation environments, videos, and more at https://mimicgen.github.io .
Automatic Logical Forms improve fidelity in Table-to-Text generation
Oct 26, 2023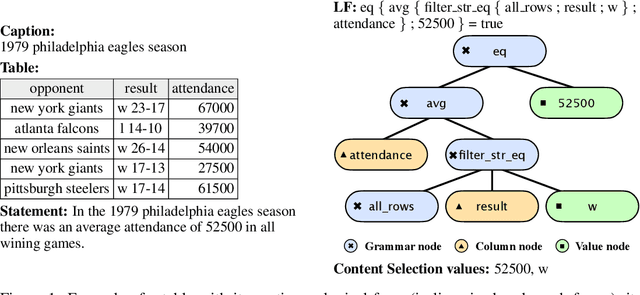


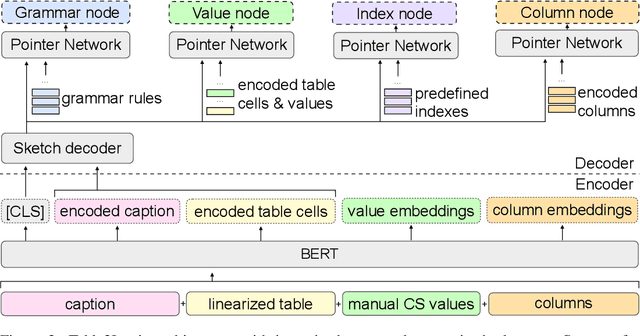
Table-to-text systems generate natural language statements from structured data like tables. While end-to-end techniques suffer from low factual correctness (fidelity), a previous study reported gains when using manual logical forms (LF) that represent the selected content and the semantics of the target text. Given the manual step, it was not clear whether automatic LFs would be effective, or whether the improvement came from content selection alone. We present TlT which, given a table and a selection of the content, first produces LFs and then the textual statement. We show for the first time that automatic LFs improve quality, with an increase in fidelity of 30 points over a comparable system not using LFs. Our experiments allow to quantify the remaining challenges for high factual correctness, with automatic selection of content coming first, followed by better Logic-to-Text generation and, to a lesser extent, better Table-to-Logic parsing.