 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Hybrid Graph Network for Complex Activity Detection in Video
Oct 30, 2023
Interpretation and understanding of video presents a challenging computer vision task in numerous fields - e.g. autonomous driving and sports analytics. Existing approaches to interpreting the actions taking place within a video clip are based upon Temporal Action Localisation (TAL), which typically identifies short-term actions. The emerging field of Complex Activity Detection (CompAD) extends this analysis to long-term activities, with a deeper understanding obtained by modelling the internal structure of a complex activity taking place within the video. We address the CompAD problem using a hybrid graph neural network which combines attention applied to a graph encoding the local (short-term) dynamic scene with a temporal graph modelling the overall long-duration activity. Our approach is as follows: i) Firstly, we propose a novel feature extraction technique which, for each video snippet, generates spatiotemporal `tubes' for the active elements (`agents') in the (local) scene by detecting individual objects, tracking them and then extracting 3D features from all the agent tubes as well as the overall scene. ii) Next, we construct a local scene graph where each node (representing either an agent tube or the scene) is connected to all other nodes. Attention is then applied to this graph to obtain an overall representation of the local dynamic scene. iii) Finally, all local scene graph representations are interconnected via a temporal graph, to estimate the complex activity class together with its start and end time. The proposed framework outperforms all previous state-of-the-art methods on all three datasets including ActivityNet-1.3, Thumos-14, and ROAD.
Large-Scale Application of Fault Injection into PyTorch Models -- an Extension to PyTorchFI for Validation Efficiency
Oct 30, 2023Transient or permanent faults in hardware can render the output of Neural Networks (NN) incorrect without user-specific traces of the error, i.e. silent data errors (SDE). On the other hand, modern NNs also possess an inherent redundancy that can tolerate specific faults. To establish a safety case, it is necessary to distinguish and quantify both types of corruptions. To study the effects of hardware (HW) faults on software (SW) in general and NN models in particular, several fault injection (FI) methods have been established in recent years. Current FI methods focus on the methodology of injecting faults but often fall short of accounting for large-scale FI tests, where many fault locations based on a particular fault model need to be analyzed in a short time. Results need to be concise, repeatable, and comparable. To address these requirements and enable fault injection as the default component in a machine learning development cycle, we introduce a novel fault injection framework called PyTorchALFI (Application Level Fault Injection for PyTorch) based on PyTorchFI. PyTorchALFI provides an efficient way to define randomly generated and reusable sets of faults to inject into PyTorch models, defines complex test scenarios, enhances data sets, and generates test KPIs while tightly coupling fault-free, faulty, and modified NN. In this paper, we provide details about the definition of test scenarios, software architecture, and several examples of how to use the new framework to apply iterative changes in fault location and number, compare different model modifications, and analyze test results.
Solving a Class of Cut-Generating Linear Programs via Machine Learning
Oct 30, 2023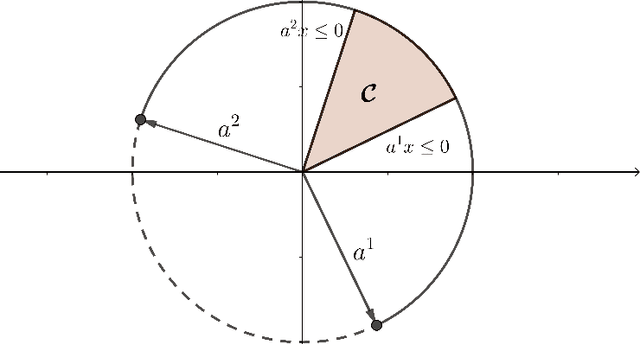
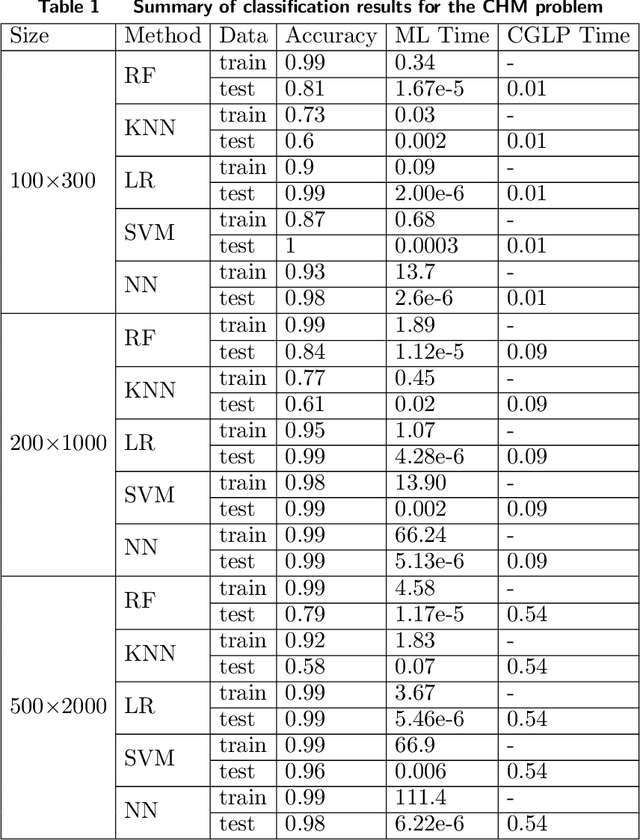
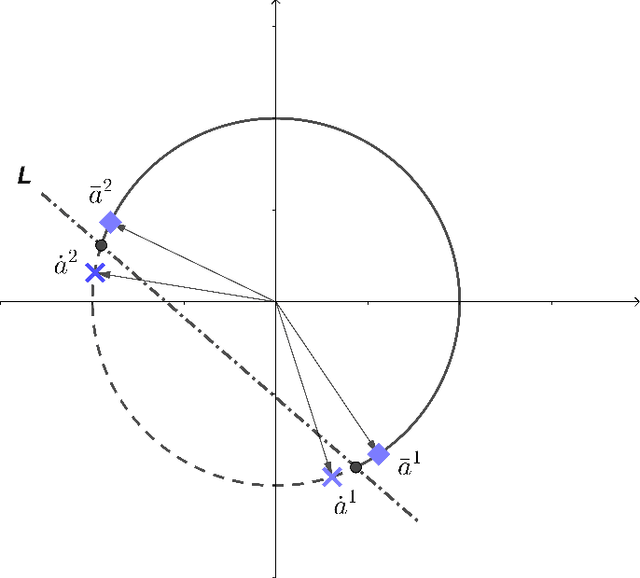
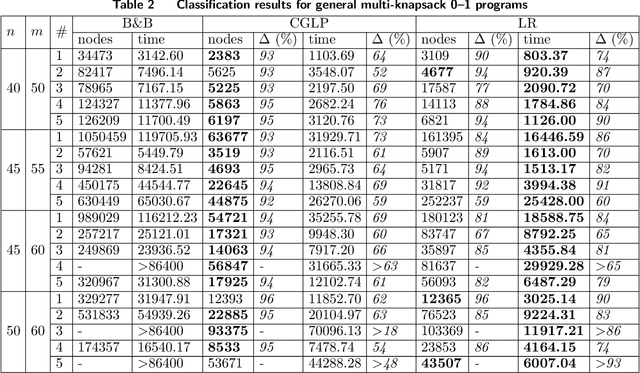
Cut-generating linear programs (CGLPs) play a key role as a separation oracle to produce valid inequalities for the feasible region of mixed-integer programs. When incorporated inside branch-and-bound, the cutting planes obtained from CGLPs help to tighten relaxations and improve dual bounds. However, running the CGLPs at the nodes of the branch-and-bound tree is computationally cumbersome due to the large number of node candidates and the lack of a priori knowledge on which nodes admit useful cutting planes. As a result, CGLPs are often avoided at default settings of branch-and-cut algorithms despite their potential impact on improving dual bounds. In this paper, we propose a novel framework based on machine learning to approximate the optimal value of a CGLP class that determines whether a cutting plane can be generated at a node of the branch-and-bound tree. Translating the CGLP as an indicator function of the objective function vector, we show that it can be approximated through conventional data classification techniques. We provide a systematic procedure to efficiently generate training data sets for the corresponding classification problem based on the CGLP structure. We conduct computational experiments on benchmark instances using classification methods such as logistic regression. These results suggest that the approximate CGLP obtained from classification can improve the solution time compared to that of conventional cutting plane methods. Our proposed framework can be efficiently applied to a large number of nodes in the branch-and-bound tree to identify the best candidates for adding a cut.
Bespoke Solvers for Generative Flow Models
Oct 29, 2023Diffusion or flow-based models are powerful generative paradigms that are notoriously hard to sample as samples are defined as solutions to high-dimensional Ordinary or Stochastic Differential Equations (ODEs/SDEs) which require a large Number of Function Evaluations (NFE) to approximate well. Existing methods to alleviate the costly sampling process include model distillation and designing dedicated ODE solvers. However, distillation is costly to train and sometimes can deteriorate quality, while dedicated solvers still require relatively large NFE to produce high quality samples. In this paper we introduce "Bespoke solvers", a novel framework for constructing custom ODE solvers tailored to the ODE of a given pre-trained flow model. Our approach optimizes an order consistent and parameter-efficient solver (e.g., with 80 learnable parameters), is trained for roughly 1% of the GPU time required for training the pre-trained model, and significantly improves approximation and generation quality compared to dedicated solvers. For example, a Bespoke solver for a CIFAR10 model produces samples with Fr\'echet Inception Distance (FID) of 2.73 with 10 NFE, and gets to 1% of the Ground Truth (GT) FID (2.59) for this model with only 20 NFE. On the more challenging ImageNet-64$\times$64, Bespoke samples at 2.2 FID with 10 NFE, and gets within 2% of GT FID (1.71) with 20 NFE.
Blacksmith: Fast Adversarial Training of Vision Transformers via a Mixture of Single-step and Multi-step Methods
Oct 29, 2023Despite the remarkable success achieved by deep learning algorithms in various domains, such as computer vision, they remain vulnerable to adversarial perturbations. Adversarial Training (AT) stands out as one of the most effective solutions to address this issue; however, single-step AT can lead to Catastrophic Overfitting (CO). This scenario occurs when the adversarially trained network suddenly loses robustness against multi-step attacks like Projected Gradient Descent (PGD). Although several approaches have been proposed to address this problem in Convolutional Neural Networks (CNNs), we found out that they do not perform well when applied to Vision Transformers (ViTs). In this paper, we propose Blacksmith, a novel training strategy to overcome the CO problem, specifically in ViTs. Our approach utilizes either of PGD-2 or Fast Gradient Sign Method (FGSM) randomly in a mini-batch during the adversarial training of the neural network. This will increase the diversity of our training attacks, which could potentially mitigate the CO issue. To manage the increased training time resulting from this combination, we craft the PGD-2 attack based on only the first half of the layers, while FGSM is applied end-to-end. Through our experiments, we demonstrate that our novel method effectively prevents CO, achieves PGD-2 level performance, and outperforms other existing techniques including N-FGSM, which is the state-of-the-art method in fast training for CNNs.
Video Frame Interpolation with Many-to-many Splatting and Spatial Selective Refinement
Oct 29, 2023In this work, we first propose a fully differentiable Many-to-Many (M2M) splatting framework to interpolate frames efficiently. Given a frame pair, we estimate multiple bidirectional flows to directly forward warp the pixels to the desired time step before fusing overlapping pixels. In doing so, each source pixel renders multiple target pixels and each target pixel can be synthesized from a larger area of visual context, establishing a many-to-many splatting scheme with robustness to undesirable artifacts. For each input frame pair, M2M has a minuscule computational overhead when interpolating an arbitrary number of in-between frames, hence achieving fast multi-frame interpolation. However, directly warping and fusing pixels in the intensity domain is sensitive to the quality of motion estimation and may suffer from less effective representation capacity. To improve interpolation accuracy, we further extend an M2M++ framework by introducing a flexible Spatial Selective Refinement (SSR) component, which allows for trading computational efficiency for interpolation quality and vice versa. Instead of refining the entire interpolated frame, SSR only processes difficult regions selected under the guidance of an estimated error map, thereby avoiding redundant computation. Evaluation on multiple benchmark datasets shows that our method is able to improve the efficiency while maintaining competitive video interpolation quality, and it can be adjusted to use more or less compute as needed.
Graph Attention-based Deep Reinforcement Learning for solving the Chinese Postman Problem with Load-dependent costs
Oct 24, 2023Recently, Deep reinforcement learning (DRL) models have shown promising results in solving routing problems. However, most DRL solvers are commonly proposed to solve node routing problems, such as the Traveling Salesman Problem (TSP). Meanwhile, there has been limited research on applying neural methods to arc routing problems, such as the Chinese Postman Problem (CPP), since they often feature irregular and complex solution spaces compared to TSP. To fill these gaps, this paper proposes a novel DRL framework to address the CPP with load-dependent costs (CPP-LC) (Corberan et al., 2018), which is a complex arc routing problem with load constraints. The novelty of our method is two-fold. First, we formulate the CPP-LC as a Markov Decision Process (MDP) sequential model. Subsequently, we introduce an autoregressive model based on DRL, namely Arc-DRL, consisting of an encoder and decoder to address the CPP-LC challenge effectively. Such a framework allows the DRL model to work efficiently and scalably to arc routing problems. Furthermore, we propose a new bio-inspired meta-heuristic solution based on Evolutionary Algorithm (EA) for CPP-LC. Extensive experiments show that Arc-DRL outperforms existing meta-heuristic methods such as Iterative Local Search (ILS) and Variable Neighborhood Search (VNS) proposed by (Corberan et al., 2018) on large benchmark datasets for CPP-LC regarding both solution quality and running time; while the EA gives the best solution quality with much more running time. We release our C++ implementations for metaheuristics such as EA, ILS and VNS along with the code for data generation and our generated data at https://github.com/HySonLab/Chinese_Postman_Problem
Can You Follow Me? Testing Situational Understanding in ChatGPT
Oct 24, 2023Understanding sentence meanings and updating information states appropriately across time -- what we call "situational understanding" (SU) -- is a critical ability for human-like AI agents. SU is essential in particular for chat models, such as ChatGPT, to enable consistent, coherent, and effective dialogue between humans and AI. Previous works have identified certain SU limitations in non-chatbot Large Language models (LLMs), but the extent and causes of these limitations are not well understood, and capabilities of current chat-based models in this domain have not been explored. In this work we tackle these questions, proposing a novel synthetic environment for SU testing which allows us to do controlled and systematic testing of SU in chat-oriented models, through assessment of models' ability to track and enumerate environment states. Our environment also allows for close analysis of dynamics of model performance, to better understand underlying causes for performance patterns. We apply our test to ChatGPT, the state-of-the-art chatbot, and find that despite the fundamental simplicity of the task, the model's performance reflects an inability to retain correct environment states across time. Our follow-up analyses suggest that performance degradation is largely because ChatGPT has non-persistent in-context memory (although it can access the full dialogue history) and it is susceptible to hallucinated updates -- including updates that artificially inflate accuracies. Our findings suggest overall that ChatGPT is not currently equipped for robust tracking of situation states, and that trust in the impressive dialogue performance of ChatGPT comes with risks. We release the codebase for reproducing our test environment, as well as all prompts and API responses from ChatGPT, at https://github.com/yangalan123/SituationalTesting.
Do We Really Need Contrastive Learning for Graph Representation?
Oct 23, 2023In recent years, contrastive learning has emerged as a dominant self-supervised paradigm, attracting numerous research interests in the field of graph learning. Graph contrastive learning (GCL) aims to embed augmented anchor samples close to each other while pushing the embeddings of other samples (negative samples) apart. However, existing GCL methods require large and diverse negative samples to ensure the quality of embeddings, and recent studies typically leverage samples excluding the anchor and positive samples as negative samples, potentially introducing false negative samples (negatives that share the same class as the anchor). Additionally, this practice can result in heavy computational burden and high time complexity of $O(N^2)$, which is particularly unaffordable for large graphs. To address these deficiencies, we leverage rank learning and propose a simple yet effective model, GraphRank. Specifically, we first generate two graph views through corruption. Then, we compute the similarity of pairwise nodes (anchor node and positive node) in both views, an arbitrary node in the latter view is selected as a negative node, and its similarity with the anchor node is computed. Based on this, we introduce rank-based learning to measure similarity scores which successfully relieve the false negative provlem and decreases the time complexity from $O(N^2)$ to $O(N)$. Moreover, we conducted extensive experiments across multiple graph tasks, demonstrating that GraphRank performs favorably against other cutting-edge GCL methods in various tasks.
Irregular Traffic Time Series Forecasting Based on Asynchronous Spatio-Temporal Graph Convolutional Network
Sep 01, 2023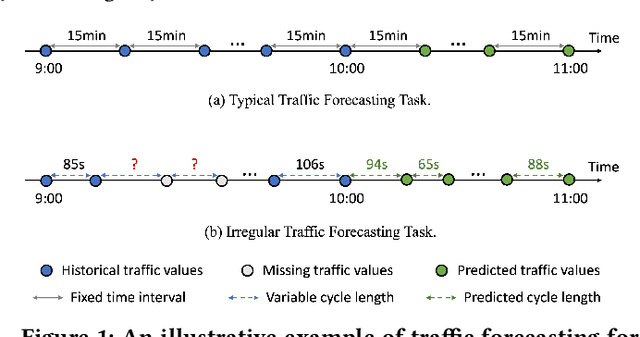
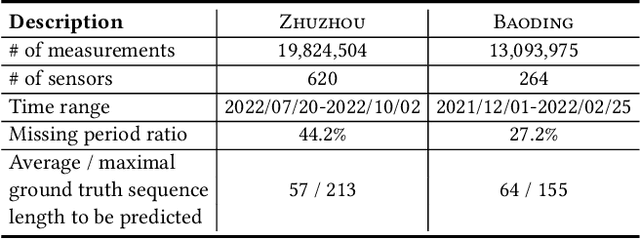
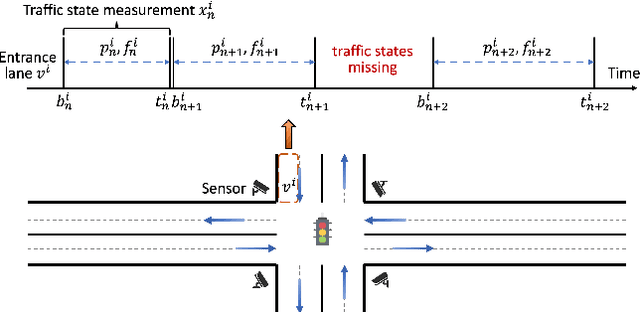
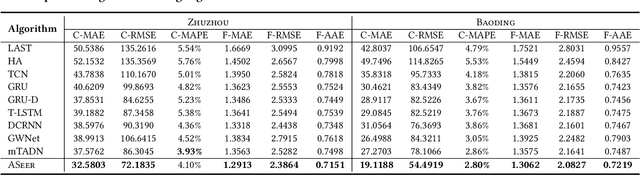
Accurate traffic forecasting at intersections governed by intelligent traffic signals is critical for the advancement of an effective intelligent traffic signal control system. However, due to the irregular traffic time series produced by intelligent intersections, the traffic forecasting task becomes much more intractable and imposes three major new challenges: 1) asynchronous spatial dependency, 2) irregular temporal dependency among traffic data, and 3) variable-length sequence to be predicted, which severely impede the performance of current traffic forecasting methods. To this end, we propose an Asynchronous Spatio-tEmporal graph convolutional nEtwoRk (ASeer) to predict the traffic states of the lanes entering intelligent intersections in a future time window. Specifically, by linking lanes via a traffic diffusion graph, we first propose an Asynchronous Graph Diffusion Network to model the asynchronous spatial dependency between the time-misaligned traffic state measurements of lanes. After that, to capture the temporal dependency within irregular traffic state sequence, a learnable personalized time encoding is devised to embed the continuous time for each lane. Then we propose a Transformable Time-aware Convolution Network that learns meta-filters to derive time-aware convolution filters with transformable filter sizes for efficient temporal convolution on the irregular sequence. Furthermore, a Semi-Autoregressive Prediction Network consisting of a state evolution unit and a semiautoregressive predictor is designed to effectively and efficiently predict variable-length traffic state sequences. Extensive experiments on two real-world datasets demonstrate the effectiveness of ASeer in six metrics.