 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
People Make Better Edits: Measuring the Efficacy of LLM-Generated Counterfactually Augmented Data for Harmful Language Detection
Nov 02, 2023
NLP models are used in a variety of critical social computing tasks, such as detecting sexist, racist, or otherwise hateful content. Therefore, it is imperative that these models are robust to spurious features. Past work has attempted to tackle such spurious features using training data augmentation, including Counterfactually Augmented Data (CADs). CADs introduce minimal changes to existing training data points and flip their labels; training on them may reduce model dependency on spurious features. However, manually generating CADs can be time-consuming and expensive. Hence in this work, we assess if this task can be automated using generative NLP models. We automatically generate CADs using Polyjuice, ChatGPT, and Flan-T5, and evaluate their usefulness in improving model robustness compared to manually-generated CADs. By testing both model performance on multiple out-of-domain test sets and individual data point efficacy, our results show that while manual CADs are still the most effective, CADs generated by ChatGPT come a close second. One key reason for the lower performance of automated methods is that the changes they introduce are often insufficient to flip the original label.
DRNet: A Decision-Making Method for Autonomous Lane Changingwith Deep Reinforcement Learning
Nov 02, 2023Machine learning techniques have outperformed numerous rule-based methods for decision-making in autonomous vehicles. Despite recent efforts, lane changing remains a major challenge, due to the complex driving scenarios and changeable social behaviors of surrounding vehicles. To help improve the state of the art, we propose to leveraging the emerging \underline{D}eep \underline{R}einforcement learning (DRL) approach for la\underline{NE} changing at the \underline{T}actical level. To this end, we present "DRNet", a novel and highly efficient DRL-based framework that enables a DRL agent to learn to drive by executing reasonable lane changing on simulated highways with an arbitrary number of lanes, and considering driving style of surrounding vehicles to make better decisions. Furthermore, to achieve a safe policy for decision-making, DRNet incorporates ideas from safety verification, the most important component of autonomous driving, to ensure that only safe actions are chosen at any time. The setting of our state representation and reward function enables the trained agent to take appropriate actions in a real-world-like simulator. Our DRL agent has the ability to learn the desired task without causing collisions and outperforms DDQN and other baseline models.
CADSim: Robust and Scalable in-the-wild 3D Reconstruction for Controllable Sensor Simulation
Nov 02, 2023Realistic simulation is key to enabling safe and scalable development of % self-driving vehicles. A core component is simulating the sensors so that the entire autonomy system can be tested in simulation. Sensor simulation involves modeling traffic participants, such as vehicles, with high quality appearance and articulated geometry, and rendering them in real time. The self-driving industry has typically employed artists to build these assets. However, this is expensive, slow, and may not reflect reality. Instead, reconstructing assets automatically from sensor data collected in the wild would provide a better path to generating a diverse and large set with good real-world coverage. Nevertheless, current reconstruction approaches struggle on in-the-wild sensor data, due to its sparsity and noise. To tackle these issues, we present CADSim, which combines part-aware object-class priors via a small set of CAD models with differentiable rendering to automatically reconstruct vehicle geometry, including articulated wheels, with high-quality appearance. Our experiments show our method recovers more accurate shapes from sparse data compared to existing approaches. Importantly, it also trains and renders efficiently. We demonstrate our reconstructed vehicles in several applications, including accurate testing of autonomy perception systems.
Identification of Mixtures of Discrete Product Distributions in Near-Optimal Sample and Time Complexity
Sep 25, 2023We consider the problem of identifying, from statistics, a distribution of discrete random variables $X_1,\ldots,X_n$ that is a mixture of $k$ product distributions. The best previous sample complexity for $n \in O(k)$ was $(1/\zeta)^{O(k^2 \log k)}$ (under a mild separation assumption parameterized by $\zeta$). The best known lower bound was $\exp(\Omega(k))$. It is known that $n\geq 2k-1$ is necessary and sufficient for identification. We show, for any $n\geq 2k-1$, how to achieve sample complexity and run-time complexity $(1/\zeta)^{O(k)}$. We also extend the known lower bound of $e^{\Omega(k)}$ to match our upper bound across a broad range of $\zeta$. Our results are obtained by combining (a) a classic method for robust tensor decomposition, (b) a novel way of bounding the condition number of key matrices called Hadamard extensions, by studying their action only on flattened rank-1 tensors.
Predicting Ground Reaction Force from Inertial Sensors
Nov 04, 2023The study of ground reaction forces (GRF) is used to characterize the mechanical loading experienced by individuals in movements such as running, which is clinically applicable to identify athletes at risk for stress-related injuries. Our aim in this paper is to determine if data collected with inertial measurement units (IMUs), that can be worn by athletes during outdoor runs, can be used to predict GRF with sufficient accuracy to allow the analysis of its derived biomechanical variables (e.g., contact time and loading rate). In this paper, we consider lightweight approaches in contrast to state-of-the-art prediction using LSTM neural networks. Specifically, we compare use of LSTMs to k-Nearest Neighbors (KNN) regression as well as propose a novel solution, SVD Embedding Regression (SER), using linear regression between singular value decomposition embeddings of IMUs data (input) and GRF data (output). We evaluate the accuracy of these techniques when using training data collected from different athletes, from the same athlete, or both, and we explore the use of acceleration and angular velocity data from sensors at different locations (sacrum and shanks). Our results illustrate that simple machine learning methods such as SER and KNN can be similarly accurate or more accurate than LSTM neural networks, with much faster training times and hyperparameter optimization; in particular, SER and KNN are more accurate when personal training data are available, and KNN comes with benefit of providing provenance of prediction. Notably, the use of personal data reduces prediction errors of all methods for most biomechanical variables.
The equivalence of dynamic and strategic stability under regularized learning in games
Nov 04, 2023In this paper, we examine the long-run behavior of regularized, no-regret learning in finite games. A well-known result in the field states that the empirical frequencies of no-regret play converge to the game's set of coarse correlated equilibria; however, our understanding of how the players' actual strategies evolve over time is much more limited - and, in many cases, non-existent. This issue is exacerbated further by a series of recent results showing that only strict Nash equilibria are stable and attracting under regularized learning, thus making the relation between learning and pointwise solution concepts particularly elusive. In lieu of this, we take a more general approach and instead seek to characterize the \emph{setwise} rationality properties of the players' day-to-day play. To that end, we focus on one of the most stringent criteria of setwise strategic stability, namely that any unilateral deviation from the set in question incurs a cost to the deviator - a property known as closedness under better replies (club). In so doing, we obtain a far-reaching equivalence between strategic and dynamic stability: a product of pure strategies is closed under better replies if and only if its span is stable and attracting under regularized learning. In addition, we estimate the rate of convergence to such sets, and we show that methods based on entropic regularization (like the exponential weights algorithm) converge at a geometric rate, while projection-based methods converge within a finite number of iterations, even with bandit, payoff-based feedback.
EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision
Nov 03, 2023We present EmerNeRF, a simple yet powerful approach for learning spatial-temporal representations of dynamic driving scenes. Grounded in neural fields, EmerNeRF simultaneously captures scene geometry, appearance, motion, and semantics via self-bootstrapping. EmerNeRF hinges upon two core components: First, it stratifies scenes into static and dynamic fields. This decomposition emerges purely from self-supervision, enabling our model to learn from general, in-the-wild data sources. Second, EmerNeRF parameterizes an induced flow field from the dynamic field and uses this flow field to further aggregate multi-frame features, amplifying the rendering precision of dynamic objects. Coupling these three fields (static, dynamic, and flow) enables EmerNeRF to represent highly-dynamic scenes self-sufficiently, without relying on ground truth object annotations or pre-trained models for dynamic object segmentation or optical flow estimation. Our method achieves state-of-the-art performance in sensor simulation, significantly outperforming previous methods when reconstructing static (+2.93 PSNR) and dynamic (+3.70 PSNR) scenes. In addition, to bolster EmerNeRF's semantic generalization, we lift 2D visual foundation model features into 4D space-time and address a general positional bias in modern Transformers, significantly boosting 3D perception performance (e.g., 37.50% relative improvement in occupancy prediction accuracy on average). Finally, we construct a diverse and challenging 120-sequence dataset to benchmark neural fields under extreme and highly-dynamic settings.
Quantitative Evaluation of a Multi-Modal Camera Setup for Fusing Event Data with RGB Images
Nov 03, 2023Event-based cameras, also called silicon retinas, potentially revolutionize computer vision by detecting and reporting significant changes in intensity asynchronous events, offering extended dynamic range, low latency, and low power consumption, enabling a wide range of applications from autonomous driving to longtime surveillance. As an emerging technology, there is a notable scarcity of publicly available datasets for event-based systems that also feature frame-based cameras, in order to exploit the benefits of both technologies. This work quantitatively evaluates a multi-modal camera setup for fusing high-resolution DVS data with RGB image data by static camera alignment. The proposed setup, which is intended for semi-automatic DVS data labeling, combines two recently released Prophesee EVK4 DVS cameras and one global shutter XIMEA MQ022CG-CM RGB camera. After alignment, state-of-the-art object detection or segmentation networks label the image data by mapping boundary boxes or labeled pixels directly to the aligned events. To facilitate this process, various time-based synchronization methods for DVS data are analyzed, and calibration accuracy, camera alignment, and lens impact are evaluated. Experimental results demonstrate the benefits of the proposed system: the best synchronization method yields an image calibration error of less than 0.90px and a pixel cross-correlation deviation of1.6px, while a lens with 8mm focal length enables detection of objects with size 30cm at a distance of 350m against homogeneous background.
DICE: Diverse Diffusion Model with Scoring for Trajectory Prediction
Oct 23, 2023Road user trajectory prediction in dynamic environments is a challenging but crucial task for various applications, such as autonomous driving. One of the main challenges in this domain is the multimodal nature of future trajectories stemming from the unknown yet diverse intentions of the agents. Diffusion models have shown to be very effective in capturing such stochasticity in prediction tasks. However, these models involve many computationally expensive denoising steps and sampling operations that make them a less desirable option for real-time safety-critical applications. To this end, we present a novel framework that leverages diffusion models for predicting future trajectories in a computationally efficient manner. To minimize the computational bottlenecks in iterative sampling, we employ an efficient sampling mechanism that allows us to maximize the number of sampled trajectories for improved accuracy while maintaining inference time in real time. Moreover, we propose a scoring mechanism to select the most plausible trajectories by assigning relative ranks. We show the effectiveness of our approach by conducting empirical evaluations on common pedestrian (UCY/ETH) and autonomous driving (nuScenes) benchmark datasets on which our model achieves state-of-the-art performance on several subsets and metrics.
Efficient Data Learning for Open Information Extraction with Pre-trained Language Models
Oct 23, 2023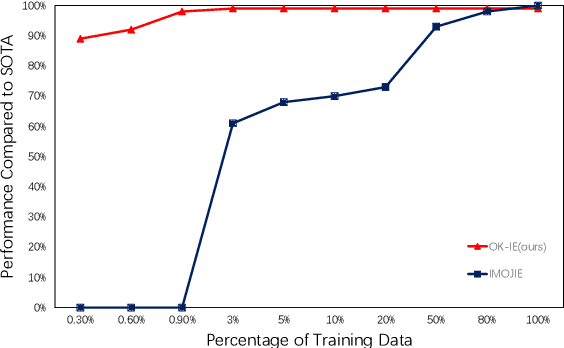
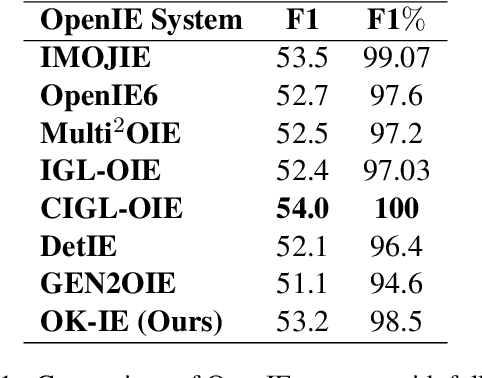

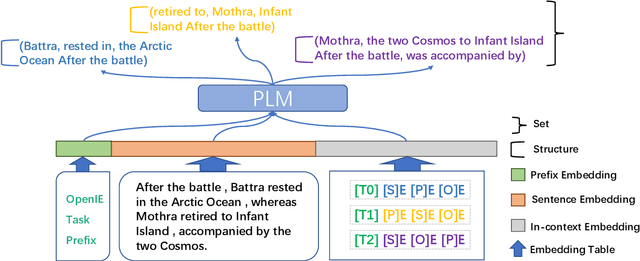
Open Information Extraction (OpenIE) is a fundamental yet challenging task in Natural Language Processing, which involves extracting all triples (subject, predicate, object) from a given sentence. While labeling-based methods have their merits, generation-based techniques offer unique advantages, such as the ability to generate tokens not present in the original sentence. However, these generation-based methods often require a significant amount of training data to learn the task form of OpenIE and substantial training time to overcome slow model convergence due to the order penalty. In this paper, we introduce a novel framework, OK-IE, that ingeniously transforms the task form of OpenIE into the pre-training task form of the T5 model, thereby reducing the need for extensive training data. Furthermore, we introduce an innovative concept of Anchor to control the sequence of model outputs, effectively eliminating the impact of order penalty on model convergence and significantly reducing training time. Experimental results indicate that, compared to previous SOTA methods, OK-IE requires only 1/100 of the training data (900 instances) and 1/120 of the training time (3 minutes) to achieve comparable results.