 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TESTA: Temporal-Spatial Token Aggregation for Long-form Video-Language Understanding
Oct 29, 2023
Large-scale video-language pre-training has made remarkable strides in advancing video-language understanding tasks. However, the heavy computational burden of video encoding remains a formidable efficiency bottleneck, particularly for long-form videos. These videos contain massive visual tokens due to their inherent 3D properties and spatiotemporal redundancy, making it challenging to capture complex temporal and spatial relationships. To tackle this issue, we propose an efficient method called TEmporal-Spatial Token Aggregation (TESTA). TESTA condenses video semantics by adaptively aggregating similar frames, as well as similar patches within each frame. TESTA can reduce the number of visual tokens by 75% and thus accelerate video encoding. Building upon TESTA, we introduce a pre-trained video-language model equipped with a divided space-time token aggregation module in each video encoder block. We evaluate our model on five datasets for paragraph-to-video retrieval and long-form VideoQA tasks. Experimental results show that TESTA improves computing efficiency by 1.7 times, and achieves significant performance gains from its scalability in processing longer input frames, e.g., +13.7 R@1 on QuerYD and +6.5 R@1 on Condensed Movie.
The Power of Explainability in Forecast-Informed Deep Learning Models for Flood Mitigation
Oct 29, 2023Floods can cause horrific harm to life and property. However, they can be mitigated or even avoided by the effective use of hydraulic structures such as dams, gates, and pumps. By pre-releasing water via these structures in advance of extreme weather events, water levels are sufficiently lowered to prevent floods. In this work, we propose FIDLAR, a Forecast Informed Deep Learning Architecture, achieving flood management in watersheds with hydraulic structures in an optimal manner by balancing out flood mitigation and unnecessary wastage of water via pre-releases. We perform experiments with FIDLAR using data from the South Florida Water Management District, which manages a coastal area that is highly prone to frequent storms and floods. Results show that FIDLAR performs better than the current state-of-the-art with several orders of magnitude speedup and with provably better pre-release schedules. The dramatic speedups make it possible for FIDLAR to be used for real-time flood management. The main contribution of this paper is the effective use of tools for model explainability, allowing us to understand the contribution of the various environmental factors towards its decisions.
Backward and Forward Inference in Interacting Independent-Cascade Processes: A Scalable and Convergent Message-Passing Approach
Oct 29, 2023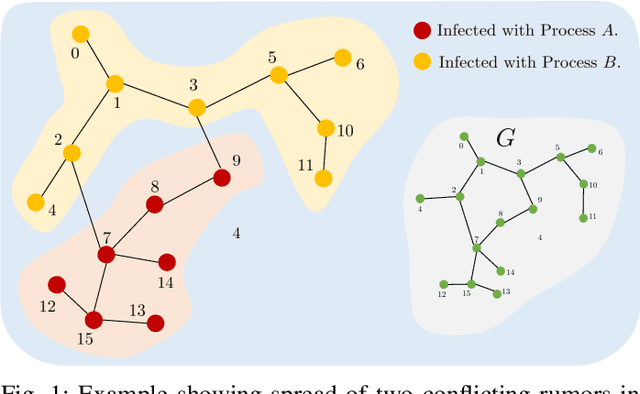
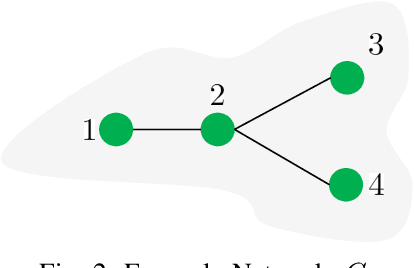
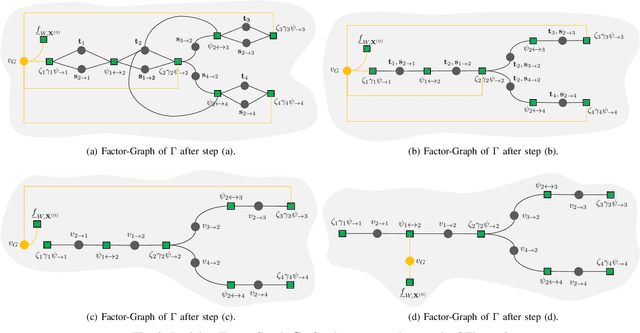
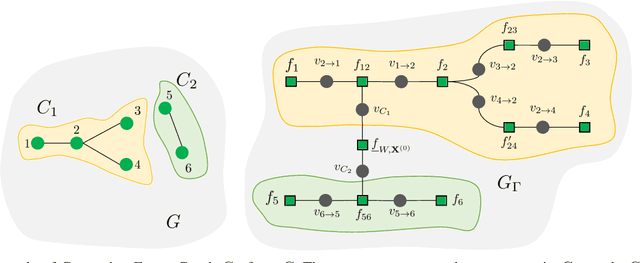
We study the problems of estimating the past and future evolutions of two diffusion processes that spread concurrently on a network. Specifically, given a known network $G=(V, \overrightarrow{E})$ and a (possibly noisy) snapshot $\mathcal{O}_n$ of its state taken at (a possibly unknown) time $W$, we wish to determine the posterior distributions of the initial state of the network and the infection times of its nodes. These distributions are useful in finding source nodes of epidemics and rumors -- $\textit{backward inference}$ -- , and estimating the spread of a fixed set of source nodes -- $\textit{forward inference}$. To model the interaction between the two processes, we study an extension of the independent-cascade (IC) model where, when a node gets infected with either process, its susceptibility to the other one changes. First, we derive the exact joint probability of the initial state of the network and the observation-snapshot $\mathcal{O}_n$. Then, using the machinery of factor-graphs, factor-graph transformations, and the generalized distributive-law, we derive a Belief-Propagation (BP) based algorithm that is scalable to large networks and can converge on graphs of arbitrary topology (at a likely expense in approximation accuracy).
Topological, or Non-topological? A Deep Learning Based Prediction
Oct 29, 2023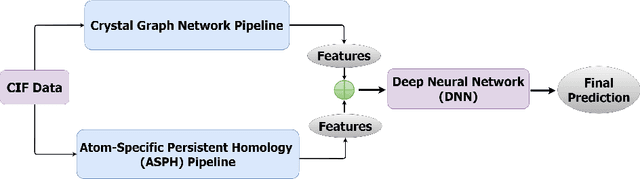
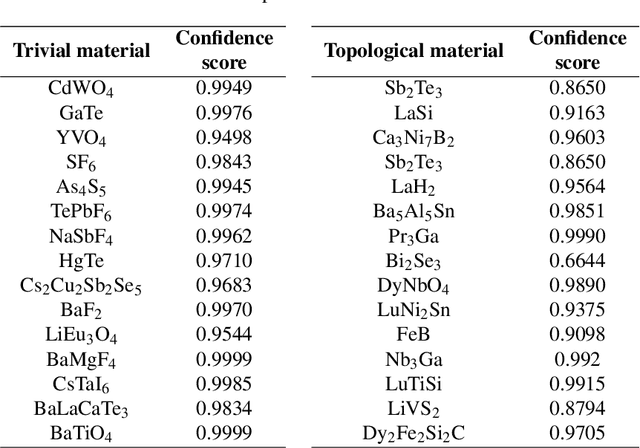
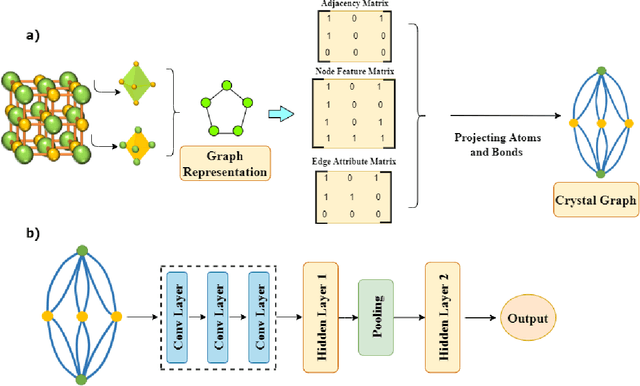
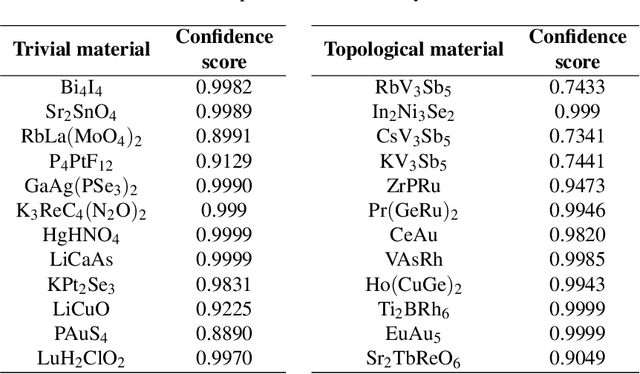
Prediction and discovery of new materials with desired properties are at the forefront of quantum science and technology research. A major bottleneck in this field is the computational resources and time complexity related to finding new materials from ab initio calculations. In this work, an effective and robust deep learning-based model is proposed by incorporating persistent homology and graph neural network which offers an accuracy of 91.4% and an F1 score of 88.5% in classifying topological vs. non-topological materials, outperforming the other state-of-the-art classifier models. The incorporation of the graph neural network encodes the underlying relation between the atoms into the model based on their own crystalline structures and thus proved to be an effective method to represent and process non-euclidean data like molecules with a relatively shallow network. The persistent homology pipeline in the suggested neural network is capable of integrating the atom-specific topological information into the deep learning model, increasing robustness, and gain in performance. It is believed that the presented work will be an efficacious tool for predicting the topological class and therefore enable the high-throughput search for novel materials in this field.
Learning Recurrent Models with Temporally Local Rules
Oct 20, 2023Fitting generative models to sequential data typically involves two recursive computations through time, one forward and one backward. The latter could be a computation of the loss gradient (as in backpropagation through time), or an inference algorithm (as in the RTS/Kalman smoother). The backward pass in particular is computationally expensive (since it is inherently serial and cannot exploit GPUs), and difficult to map onto biological processes. Work-arounds have been proposed; here we explore a very different one: requiring the generative model to learn the joint distribution over current and previous states, rather than merely the transition probabilities. We show on toy datasets that different architectures employing this principle can learn aspects of the data typically requiring the backward pass.
Optimizing Retrieval-augmented Reader Models via Token Elimination
Oct 20, 2023Fusion-in-Decoder (FiD) is an effective retrieval-augmented language model applied across a variety of open-domain tasks, such as question answering, fact checking, etc. In FiD, supporting passages are first retrieved and then processed using a generative model (Reader), which can cause a significant bottleneck in decoding time, particularly with long outputs. In this work, we analyze the contribution and necessity of all the retrieved passages to the performance of reader models, and propose eliminating some of the retrieved information, at the token level, that might not contribute essential information to the answer generation process. We demonstrate that our method can reduce run-time by up to 62.2%, with only a 2% reduction in performance, and in some cases, even improve the performance results.
A Better Match for Drivers and Riders: Reinforcement Learning at Lyft
Oct 20, 2023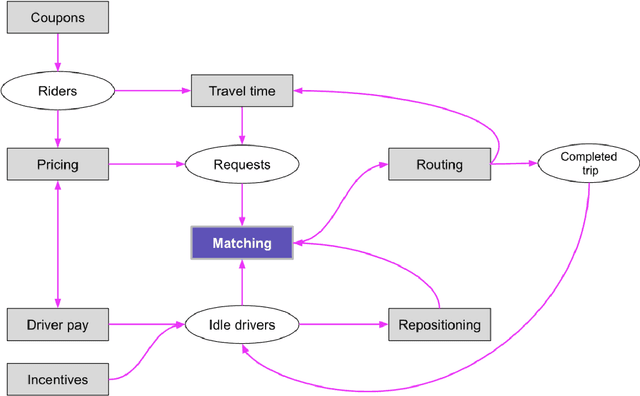
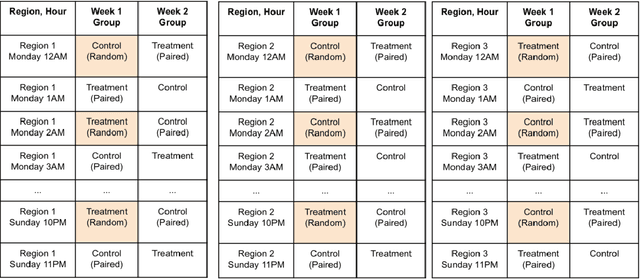
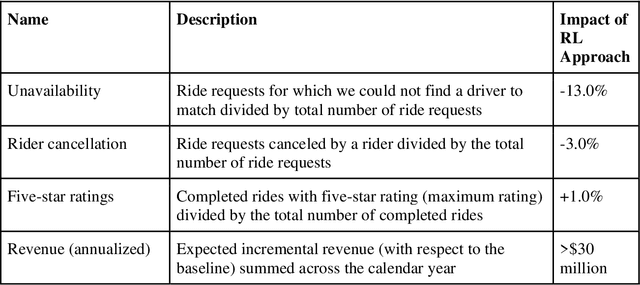
To better match drivers to riders in our ridesharing application, we revised Lyft's core matching algorithm. We use a novel online reinforcement learning approach that estimates the future earnings of drivers in real time and use this information to find more efficient matches. This change was the first documented implementation of a ridesharing matching algorithm that can learn and improve in real time. We evaluated the new approach during weeks of switchback experimentation in most Lyft markets, and estimated how it benefited drivers, riders, and the platform. In particular, it enabled our drivers to serve millions of additional riders each year, leading to more than $30 million per year in incremental revenue. Lyft rolled out the algorithm globally in 2021.
Time Does Tell: Self-Supervised Time-Tuning of Dense Image Representations
Aug 22, 2023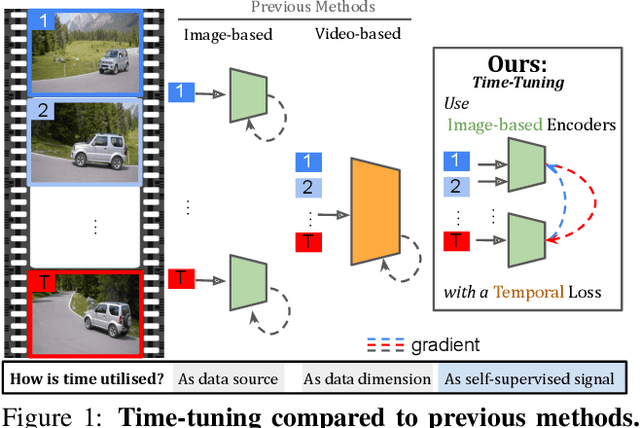

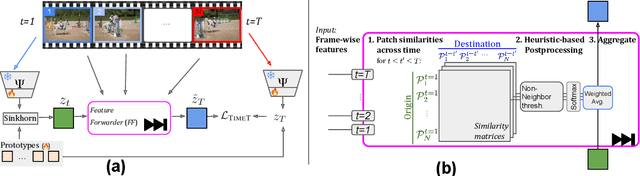
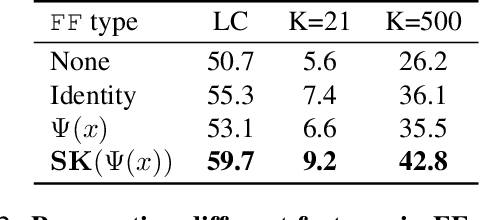
Spatially dense self-supervised learning is a rapidly growing problem domain with promising applications for unsupervised segmentation and pretraining for dense downstream tasks. Despite the abundance of temporal data in the form of videos, this information-rich source has been largely overlooked. Our paper aims to address this gap by proposing a novel approach that incorporates temporal consistency in dense self-supervised learning. While methods designed solely for images face difficulties in achieving even the same performance on videos, our method improves not only the representation quality for videos-but also images. Our approach, which we call time-tuning, starts from image-pretrained models and fine-tunes them with a novel self-supervised temporal-alignment clustering loss on unlabeled videos. This effectively facilitates the transfer of high-level information from videos to image representations. Time-tuning improves the state-of-the-art by 8-10% for unsupervised semantic segmentation on videos and matches it for images. We believe this method paves the way for further self-supervised scaling by leveraging the abundant availability of videos. The implementation can be found here : https://github.com/SMSD75/Timetuning
The Generative AI Paradox: "What It Can Create, It May Not Understand"
Oct 31, 2023

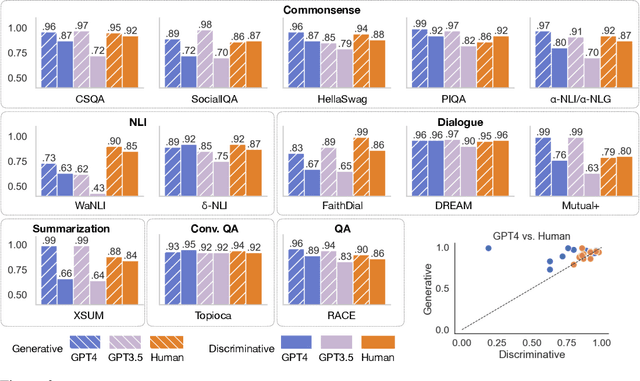
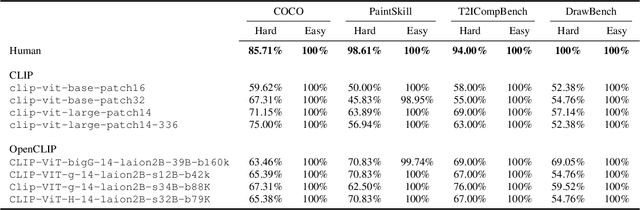
The recent wave of generative AI has sparked unprecedented global attention, with both excitement and concern over potentially superhuman levels of artificial intelligence: models now take only seconds to produce outputs that would challenge or exceed the capabilities even of expert humans. At the same time, models still show basic errors in understanding that would not be expected even in non-expert humans. This presents us with an apparent paradox: how do we reconcile seemingly superhuman capabilities with the persistence of errors that few humans would make? In this work, we posit that this tension reflects a divergence in the configuration of intelligence in today's generative models relative to intelligence in humans. Specifically, we propose and test the Generative AI Paradox hypothesis: generative models, having been trained directly to reproduce expert-like outputs, acquire generative capabilities that are not contingent upon -- and can therefore exceed -- their ability to understand those same types of outputs. This contrasts with humans, for whom basic understanding almost always precedes the ability to generate expert-level outputs. We test this hypothesis through controlled experiments analyzing generation vs. understanding in generative models, across both language and image modalities. Our results show that although models can outperform humans in generation, they consistently fall short of human capabilities in measures of understanding, as well as weaker correlation between generation and understanding performance, and more brittleness to adversarial inputs. Our findings support the hypothesis that models' generative capability may not be contingent upon understanding capability, and call for caution in interpreting artificial intelligence by analogy to human intelligence.
Leveraging Word Guessing Games to Assess the Intelligence of Large Language Models
Oct 31, 2023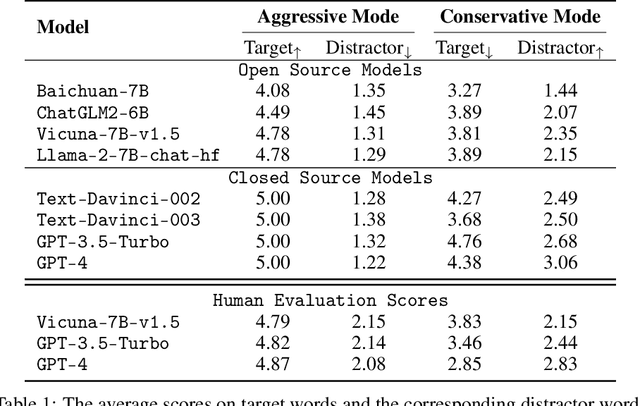
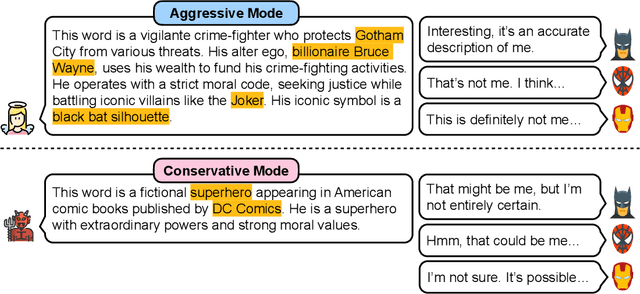

The automatic evaluation of LLM-based agent intelligence is critical in developing advanced LLM-based agents. Although considerable effort has been devoted to developing human-annotated evaluation datasets, such as AlpacaEval, existing techniques are costly, time-consuming, and lack adaptability. In this paper, inspired by the popular language game ``Who is Spy'', we propose to use the word guessing game to assess the intelligence performance of LLMs. Given a word, the LLM is asked to describe the word and determine its identity (spy or not) based on its and other players' descriptions. Ideally, an advanced agent should possess the ability to accurately describe a given word using an aggressive description while concurrently maximizing confusion in the conservative description, enhancing its participation in the game. To this end, we first develop DEEP to evaluate LLMs' expression and disguising abilities. DEEP requires LLM to describe a word in aggressive and conservative modes. We then introduce SpyGame, an interactive multi-agent framework designed to assess LLMs' intelligence through participation in a competitive language-based board game. Incorporating multi-agent interaction, SpyGame requires the target LLM to possess linguistic skills and strategic thinking, providing a more comprehensive evaluation of LLMs' human-like cognitive abilities and adaptability in complex communication situations. The proposed evaluation framework is very easy to implement. We collected words from multiple sources, domains, and languages and used the proposed evaluation framework to conduct experiments. Extensive experiments demonstrate that the proposed DEEP and SpyGame effectively evaluate the capabilities of various LLMs, capturing their ability to adapt to novel situations and engage in strategic communication.