 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
From Learning to Analytics: Improving Model Efficacy with Goal-Directed Client Selection
Mar 30, 2024
Federated learning (FL) is an appealing paradigm for learning a global model among distributed clients while preserving data privacy. Driven by the demand for high-quality user experiences, evaluating the well-trained global model after the FL process is crucial. In this paper, we propose a closed-loop model analytics framework that allows for effective evaluation of the trained global model using clients' local data. To address the challenges posed by system and data heterogeneities in the FL process, we study a goal-directed client selection problem based on the model analytics framework by selecting a subset of clients for the model training. This problem is formulated as a stochastic multi-armed bandit (SMAB) problem. We first put forth a quick initial upper confidence bound (Quick-Init UCB) algorithm to solve this SMAB problem under the federated analytics (FA) framework. Then, we further propose a belief propagation-based UCB (BP-UCB) algorithm under the democratized analytics (DA) framework. Moreover, we derive two regret upper bounds for the proposed algorithms, which increase logarithmically over the time horizon. The numerical results demonstrate that the proposed algorithms achieve nearly optimal performance, with a gap of less than 1.44% and 3.12% under the FA and DA frameworks, respectively.
Small Language Models Learn Enhanced Reasoning Skills from Medical Textbooks
Mar 30, 2024While recent advancements in commercial large language models (LM) have shown promising results in medical tasks, their closed-source nature poses significant privacy and security concerns, hindering their widespread use in the medical field. Despite efforts to create open-source models, their limited parameters often result in insufficient multi-step reasoning capabilities required for solving complex medical problems. To address this, we introduce Meerkat-7B, a novel medical AI system with 7 billion parameters. Meerkat-7B was trained using our new synthetic dataset consisting of high-quality chain-of-thought reasoning paths sourced from 18 medical textbooks, along with diverse instruction-following datasets. Our system achieved remarkable accuracy across seven medical benchmarks, surpassing GPT-3.5 by 13.1%, as well as outperforming the previous best 7B models such as MediTron-7B and BioMistral-7B by 13.4% and 9.8%, respectively. Notably, it surpassed the passing threshold of the United States Medical Licensing Examination (USMLE) for the first time for a 7B-parameter model. Additionally, our system offered more detailed free-form responses to clinical queries compared to existing 7B and 13B models, approaching the performance level of GPT-3.5. This significantly narrows the performance gap with large LMs, showcasing its effectiveness in addressing complex medical challenges.
Accurate Cutting-point Estimation for Robotic Lychee Harvesting through Geometry-aware Learning
Mar 30, 2024Accurately identifying lychee-picking points in unstructured orchard environments and obtaining their coordinate locations is critical to the success of lychee-picking robots. However, traditional two-dimensional (2D) image-based object detection methods often struggle due to the complex geometric structures of branches, leaves and fruits, leading to incorrect determination of lychee picking points. In this study, we propose a Fcaf3d-lychee network model specifically designed for the accurate localisation of lychee picking points. Point cloud data of lychee picking points in natural environments are acquired using Microsoft's Azure Kinect DK time-of-flight (TOF) camera through multi-view stitching. We augment the Fully Convolutional Anchor-Free 3D Object Detection (Fcaf3d) model with a squeeze-and-excitation(SE) module, which exploits human visual attention mechanisms for improved feature extraction of lychee picking points. The trained network model is evaluated on a test set of lychee-picking locations and achieves an impressive F1 score of 88.57%, significantly outperforming existing models. Subsequent three-dimensional (3D) position detection of picking points in real lychee orchard environments yields high accuracy, even under varying degrees of occlusion. Localisation errors of lychee picking points are within 1.5 cm in all directions, demonstrating the robustness and generality of the model.
Memory-Scalable and Simplified Functional Map Learning
Mar 30, 2024Deep functional maps have emerged in recent years as a prominent learning-based framework for non-rigid shape matching problems. While early methods in this domain only focused on learning in the functional domain, the latest techniques have demonstrated that by promoting consistency between functional and pointwise maps leads to significant improvements in accuracy. Unfortunately, existing approaches rely heavily on the computation of large dense matrices arising from soft pointwise maps, which compromises their efficiency and scalability. To address this limitation, we introduce a novel memory-scalable and efficient functional map learning pipeline. By leveraging the specific structure of functional maps, we offer the possibility to achieve identical results without ever storing the pointwise map in memory. Furthermore, based on the same approach, we present a differentiable map refinement layer adapted from an existing axiomatic refinement algorithm. Unlike many functional map learning methods, which use this algorithm at a post-processing step, ours can be easily used at train time, enabling to enforce consistency between the refined and initial versions of the map. Our resulting approach is both simpler, more efficient and more numerically stable, by avoiding differentiation through a linear system, while achieving close to state-of-the-art results in challenging scenarios.
LITA: Language Instructed Temporal-Localization Assistant
Mar 27, 2024There has been tremendous progress in multimodal Large Language Models (LLMs). Recent works have extended these models to video input with promising instruction following capabilities. However, an important missing piece is temporal localization. These models cannot accurately answer the "When?" questions. We identify three key aspects that limit their temporal localization capabilities: (i) time representation, (ii) architecture, and (iii) data. We address these shortcomings by proposing Language Instructed Temporal-Localization Assistant (LITA) with the following features: (1) We introduce time tokens that encode timestamps relative to the video length to better represent time in videos. (2) We introduce SlowFast tokens in the architecture to capture temporal information at fine temporal resolution. (3) We emphasize temporal localization data for LITA. In addition to leveraging existing video datasets with timestamps, we propose a new task, Reasoning Temporal Localization (RTL), along with the dataset, ActivityNet-RTL, for learning and evaluating this task. Reasoning temporal localization requires both the reasoning and temporal localization of Video LLMs. LITA demonstrates strong performance on this challenging task, nearly doubling the temporal mean intersection-over-union (mIoU) of baselines. In addition, we show that our emphasis on temporal localization also substantially improves video-based text generation compared to existing Video LLMs, including a 36% relative improvement of Temporal Understanding. Code is available at: https://github.com/NVlabs/LITA
Enhancing Multiple Object Tracking Accuracy via Quantum Annealing
Mar 27, 2024Multiple object tracking (MOT), a key task in image recognition, presents a persistent challenge in balancing processing speed and tracking accuracy. This study introduces a novel approach that leverages quantum annealing (QA) to expedite computation speed, while enhancing tracking accuracy through the ensembling of object tracking processes. A method to improve the matching integration process is also proposed. By utilizing the sequential nature of MOT, this study further augments the tracking method via reverse annealing (RA). Experimental validation confirms the maintenance of high accuracy with an annealing time of a mere 3 $\mu$s per tracking process. The proposed method holds significant potential for real-time MOT applications, including traffic flow measurement for urban traffic light control, collision prediction for autonomous robots and vehicles, and management of products mass-produced in factories.
DD-VNB: A Depth-based Dual-Loop Framework for Real-time Visually Navigated Bronchoscopy
Mar 15, 2024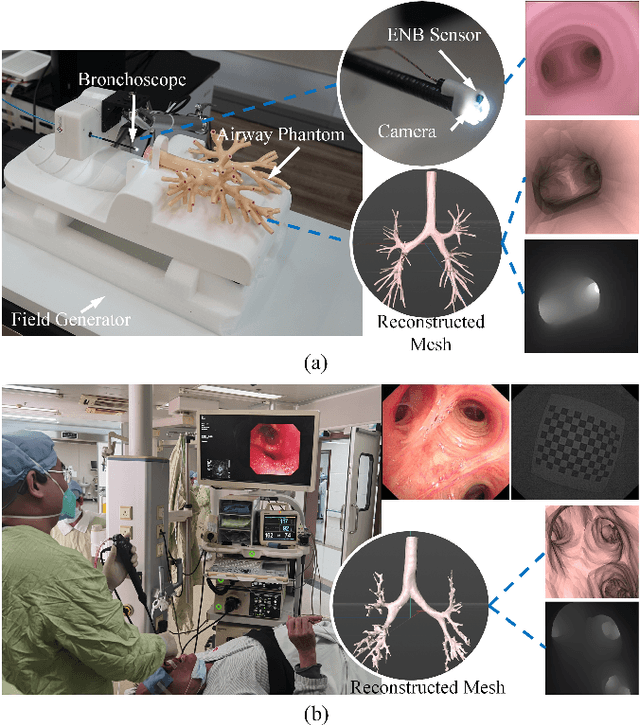
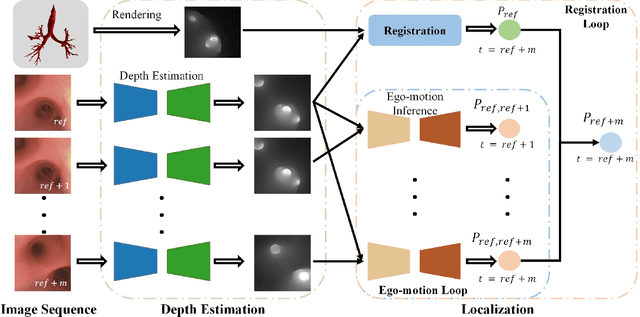
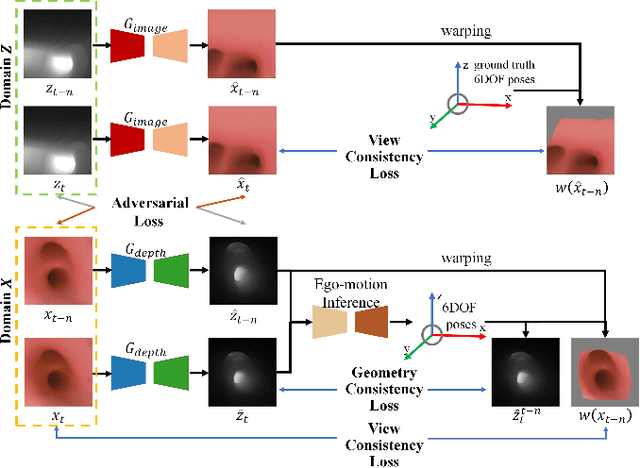
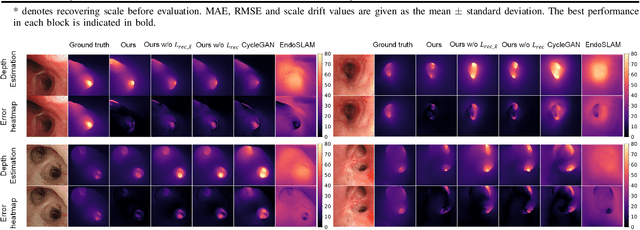
Real-time 6 DOF localization of bronchoscopes is crucial for enhancing intervention quality. However, current vision-based technologies struggle to balance between generalization to unseen data and computational speed. In this study, we propose a Depth-based Dual-Loop framework for real-time Visually Navigated Bronchoscopy (DD-VNB) that can generalize across patient cases without the need of re-training. The DD-VNB framework integrates two key modules: depth estimation and dual-loop localization. To address the domain gap among patients, we propose a knowledge-embedded depth estimation network that maps endoscope frames to depth, ensuring generalization by eliminating patient-specific textures. The network embeds view synthesis knowledge into a cycle adversarial architecture for scale-constrained monocular depth estimation. For real-time performance, our localization module embeds a fast ego-motion estimation network into the loop of depth registration. The ego-motion inference network estimates the pose change of the bronchoscope in high frequency while depth registration against the pre-operative 3D model provides absolute pose periodically. Specifically, the relative pose changes are fed into the registration process as the initial guess to boost its accuracy and speed. Experiments on phantom and in-vivo data from patients demonstrate the effectiveness of our framework: 1) monocular depth estimation outperforms SOTA, 2) localization achieves an accuracy of Absolute Tracking Error (ATE) of 4.7 $\pm$ 3.17 mm in phantom and 6.49 $\pm$ 3.88 mm in patient data, 3) with a frame-rate approaching video capture speed, 4) without the necessity of case-wise network retraining. The framework's superior speed and accuracy demonstrate its promising clinical potential for real-time bronchoscopic navigation.
Risk prediction of pathological gambling on social media
Mar 28, 2024This paper addresses the problem of risk prediction on social media data, specifically focusing on the classification of Reddit users as having a pathological gambling disorder. To tackle this problem, this paper focuses on incorporating temporal and emotional features into the model. The preprocessing phase involves dealing with the time irregularity of posts by padding sequences. Two baseline architectures are used for preliminary evaluation: BERT classifier on concatenated posts per user and GRU with LSTM on sequential data. Experimental results demonstrate that the sequential models outperform the concatenation-based model. The results of the experiments conclude that the incorporation of a time decay layer (TD) and passing the emotion classification layer (EmoBERTa) through LSTM improves the performance significantly. Experiments concluded that the addition of a self-attention layer didn't significantly improve the performance of the model, however provided easily interpretable attention scores. The developed architecture with the inclusion of EmoBERTa and TD layers achieved a high F1 score, beating existing benchmarks on pathological gambling dataset. Future work may involve the early prediction of risk factors associated with pathological gambling disorder and testing models on other datasets. Overall, this research highlights the significance of the sequential processing of posts including temporal and emotional features to boost the predictive power, as well as adding an attention layer for interpretability.
Resource Allocation in Large Language Model Integrated 6G Vehicular Networks
Mar 27, 2024In the upcoming 6G era, vehicular networks are shifting from simple Vehicle-to-Vehicle (V2V) communication to the more complex Vehicle-to-Everything (V2X) connectivity. At the forefront of this shift is the incorporation of Large Language Models (LLMs) into vehicles. Known for their sophisticated natural language processing abilities, LLMs change how users interact with their vehicles. This integration facilitates voice-driven commands and interactions, departing from the conventional manual control systems. However, integrating LLMs into vehicular systems presents notable challenges. The substantial computational demands and energy requirements of LLMs pose significant challenges, especially in the constrained environment of a vehicle. Additionally, the time-sensitive nature of tasks in vehicular networks adds another layer of complexity. In this paper, we consider an edge computing system where vehicles process the initial layers of LLM computations locally, and offload the remaining LLM computation tasks to the Roadside Units (RSUs), envisioning a vehicular ecosystem where LLM computations seamlessly interact with the ultra-low latency and high-bandwidth capabilities of 6G networks. To balance the trade-off between completion time and energy consumption, we formulate a multi-objective optimization problem to minimize the total cost of the vehicles and RSUs. The problem is then decomposed into two sub-problems, which are solved by sequential quadratic programming (SQP) method and fractional programming technique. The simulation results clearly indicate that the algorithm we have proposed is highly effective in reducing both the completion time and energy consumption of the system.
Utilizing acceleration measurements to improve TDOA based localization
Mar 28, 2024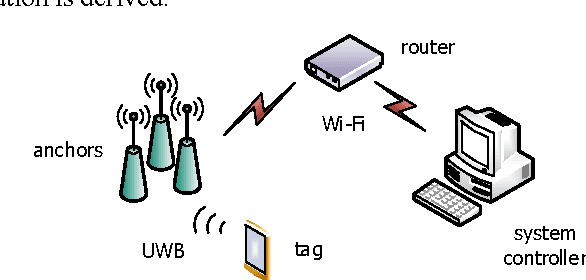
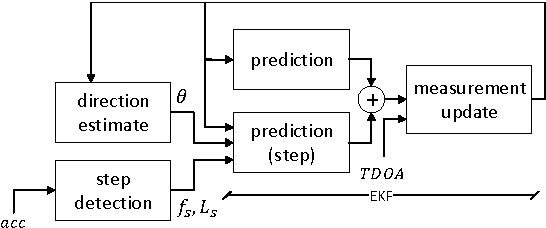
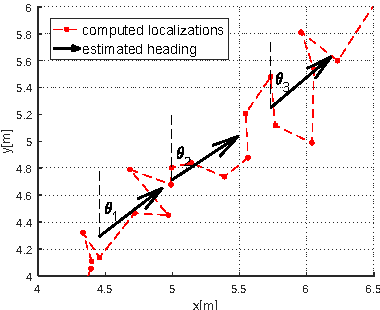
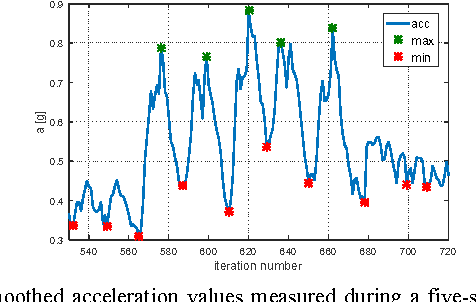
In this paper localization using UWB positioning system and an inertial unit containing a single accelerometer is considered. The main part of the paper describes a novel algorithm for person localization. The algorithm is based on modified Extended Kalman Filter and utilizes TDOA (Time Difference of Arrival) results obtained from UWB system and results of acceleration measurement performed by the localized tag device. The proposed algorithm has been experimentally investigated through simulation and experiments. The results are included in the paper.
* Originally presented at 2017 Signal Processing Symposium (SPSympo), Jachranka, Poland