 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Network Reconstruction of the Left Atrium using Sparse Catheter Paths
Nov 04, 2023
Catheter based radiofrequency ablation for pulmonary vein isolation has become the first line of treatment for atrial fibrillation in recent years. This requires a rather accurate map of the left atrial sub-endocardial surface including the ostia of the pulmonary veins, which requires dense sampling of the surface and takes more than 10 minutes. The focus of this work is to provide left atrial visualization early in the procedure to ease procedure complexity and enable further workflows, such as using catheters that have difficulty sampling the surface. We propose a dense encoder-decoder network with a novel regularization term to reconstruct the shape of the left atrium from partial data which is derived from simple catheter maneuvers. To train the network, we acquire a large dataset of 3D atria shapes and generate corresponding catheter trajectories. Once trained, we show that the suggested network can sufficiently approximate the atrium shape based on a given trajectory. We compare several network solutions for the 3D atrium reconstruction. We demonstrate that the solution proposed produces realistic visualization using partial acquisition within a 3-minute time interval. Synthetic and human clinical cases are shown.
An Efficient Detection and Control System for Underwater Docking using Machine Learning and Realistic Simulation: A Comprehensive Approach
Nov 06, 2023
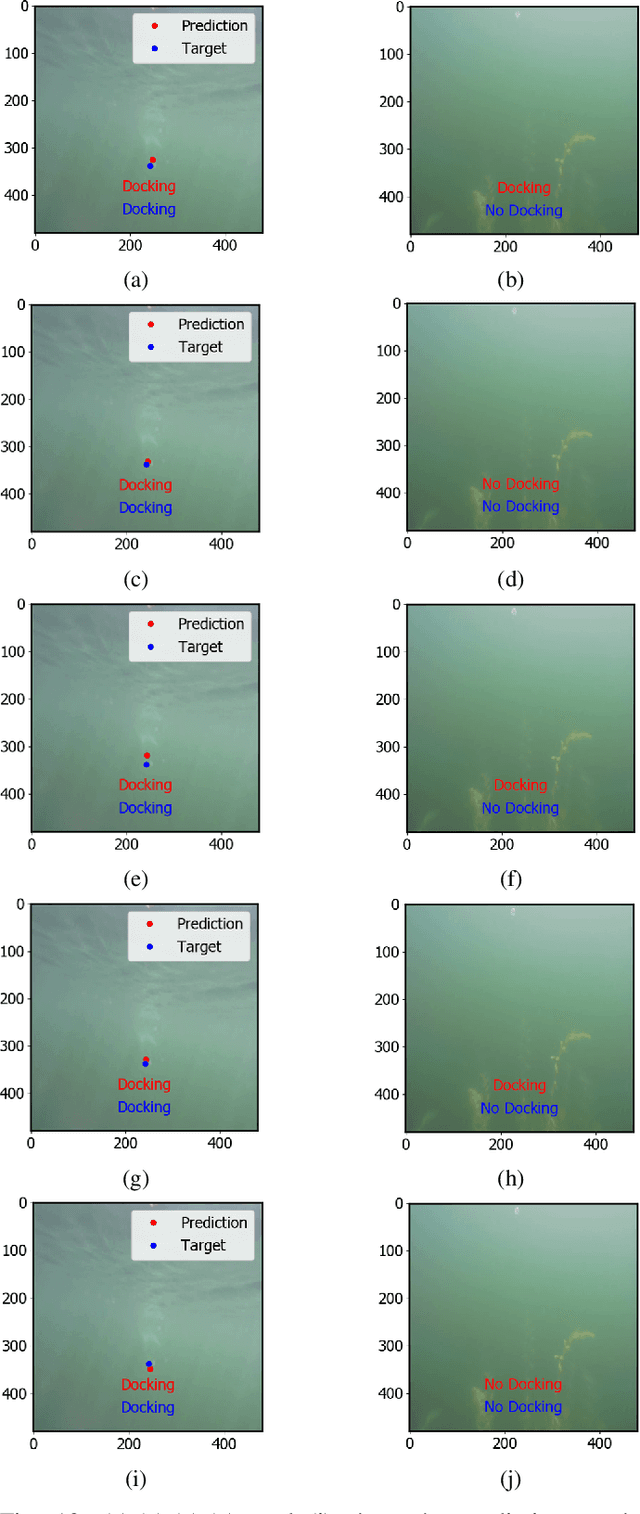


Underwater docking is critical to enable the persistent operation of Autonomous Underwater Vehicles (AUVs). For this, the AUV must be capable of detecting and localizing the docking station, which is complex due to the highly dynamic undersea environment. Image-based solutions offer a high acquisition rate and versatile alternative to adapt to this environment; however, the underwater environment presents challenges such as low visibility, high turbidity, and distortion. In addition to this, field experiments to validate underwater docking capabilities can be costly and dangerous due to the specialized equipment and safety considerations required to conduct the experiments. This work compares different deep-learning architectures to perform underwater docking detection and classification. The architecture with the best performance is then compressed using knowledge distillation under the teacher-student paradigm to reduce the network's memory footprint, allowing real-time implementation. To reduce the simulation-to-reality gap, a Generative Adversarial Network (GAN) is used to do image-to-image translation, converting the Gazebo simulation image into a realistic underwater-looking image. The obtained image is then processed using an underwater image formation model to simulate image attenuation over distance under different water types. The proposed method is finally evaluated according to the AUV docking success rate and compared with classical vision methods. The simulation results show an improvement of 20% in the high turbidity scenarios regardless of the underwater currents. Furthermore, we show the performance of the proposed approach by showing experimental results on the off-the-shelf AUV Iver3.
Leveraging Word Guessing Games to Assess the Intelligence of Large Language Models
Nov 06, 2023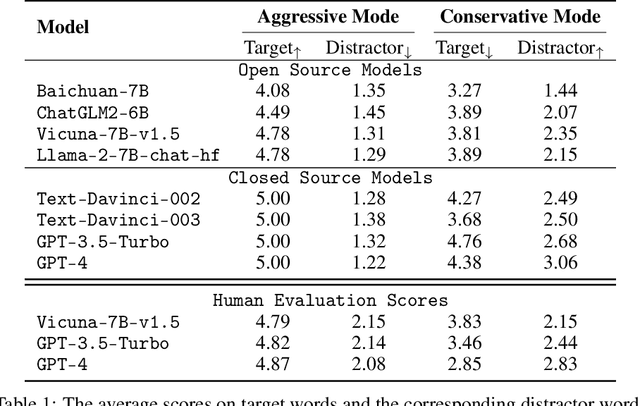
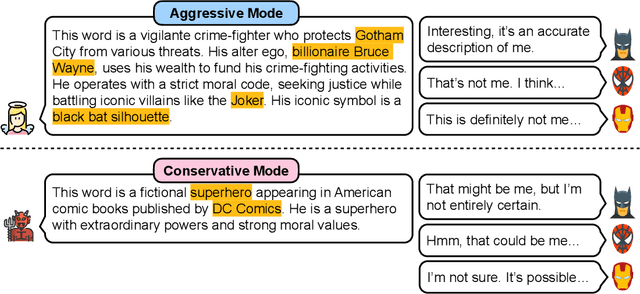

The automatic evaluation of LLM-based agent intelligence is critical in developing advanced LLM-based agents. Although considerable effort has been devoted to developing human-annotated evaluation datasets, such as AlpacaEval, existing techniques are costly, time-consuming, and lack adaptability. In this paper, inspired by the popular language game ``Who is Spy'', we propose to use the word guessing game to assess the intelligence performance of LLMs. Given a word, the LLM is asked to describe the word and determine its identity (spy or not) based on its and other players' descriptions. Ideally, an advanced agent should possess the ability to accurately describe a given word using an aggressive description while concurrently maximizing confusion in the conservative description, enhancing its participation in the game. To this end, we first develop DEEP to evaluate LLMs' expression and disguising abilities. DEEP requires LLM to describe a word in aggressive and conservative modes. We then introduce SpyGame, an interactive multi-agent framework designed to assess LLMs' intelligence through participation in a competitive language-based board game. Incorporating multi-agent interaction, SpyGame requires the target LLM to possess linguistic skills and strategic thinking, providing a more comprehensive evaluation of LLMs' human-like cognitive abilities and adaptability in complex communication situations. The proposed evaluation framework is very easy to implement. We collected words from multiple sources, domains, and languages and used the proposed evaluation framework to conduct experiments. Extensive experiments demonstrate that the proposed DEEP and SpyGame effectively evaluate the capabilities of various LLMs, capturing their ability to adapt to novel situations and engage in strategic communication.
Asynchronous Local Computations in Distributed Bayesian Learning
Nov 06, 2023Due to the expanding scope of machine learning (ML) to the fields of sensor networking, cooperative robotics and many other multi-agent systems, distributed deployment of inference algorithms has received a lot of attention. These algorithms involve collaboratively learning unknown parameters from dispersed data collected by multiple agents. There are two competing aspects in such algorithms, namely, intra-agent computation and inter-agent communication. Traditionally, algorithms are designed to perform both synchronously. However, certain circumstances need frugal use of communication channels as they are either unreliable, time-consuming, or resource-expensive. In this paper, we propose gossip-based asynchronous communication to leverage fast computations and reduce communication overhead simultaneously. We analyze the effects of multiple (local) intra-agent computations by the active agents between successive inter-agent communications. For local computations, Bayesian sampling via unadjusted Langevin algorithm (ULA) MCMC is utilized. The communication is assumed to be over a connected graph (e.g., as in decentralized learning), however, the results can be extended to coordinated communication where there is a central server (e.g., federated learning). We theoretically quantify the convergence rates in the process. To demonstrate the efficacy of the proposed algorithm, we present simulations on a toy problem as well as on real world data sets to train ML models to perform classification tasks. We observe faster initial convergence and improved performance accuracy, especially in the low data range. We achieve on average 78% and over 90% classification accuracy respectively on the Gamma Telescope and mHealth data sets from the UCI ML repository.
GLaMM: Pixel Grounding Large Multimodal Model
Nov 06, 2023Large Multimodal Models (LMMs) extend Large Language Models to the vision domain. Initial efforts towards LMMs used holistic images and text prompts to generate ungrounded textual responses. Very recently, region-level LMMs have been used to generate visually grounded responses. However, they are limited to only referring a single object category at a time, require users to specify the regions in inputs, or cannot offer dense pixel-wise object grounding. In this work, we present Grounding LMM (GLaMM), the first model that can generate natural language responses seamlessly intertwined with corresponding object segmentation masks. GLaMM not only grounds objects appearing in the conversations but is flexible enough to accept both textual and optional visual prompts (region of interest) as input. This empowers users to interact with the model at various levels of granularity, both in textual and visual domains. Due to the lack of standard benchmarks for the novel setting of generating visually grounded detailed conversations, we introduce a comprehensive evaluation protocol with our curated grounded conversations. Our proposed Grounded Conversation Generation (GCG) task requires densely grounded concepts in natural scenes at a large-scale. To this end, we propose a densely annotated Grounding-anything Dataset (GranD) using our proposed automated annotation pipeline that encompasses 7.5M unique concepts grounded in a total of 810M regions available with segmentation masks. Besides GCG, GLaMM also performs effectively on several downstream tasks e.g., referring expression segmentation, image and region-level captioning and vision-language conversations. Project Page: https://mbzuai-oryx.github.io/groundingLMM.
On-device Real-time Custom Hand Gesture Recognition
Sep 19, 2023Most existing hand gesture recognition (HGR) systems are limited to a predefined set of gestures. However, users and developers often want to recognize new, unseen gestures. This is challenging due to the vast diversity of all plausible hand shapes, e.g. it is impossible for developers to include all hand gestures in a predefined list. In this paper, we present a user-friendly framework that lets users easily customize and deploy their own gesture recognition pipeline. Our framework provides a pre-trained single-hand embedding model that can be fine-tuned for custom gesture recognition. Users can perform gestures in front of a webcam to collect a small amount of images per gesture. We also offer a low-code solution to train and deploy the custom gesture recognition model. This makes it easy for users with limited ML expertise to use our framework. We further provide a no-code web front-end for users without any ML expertise. This makes it even easier to build and test the end-to-end pipeline. The resulting custom HGR is then ready to be run on-device for real-time scenarios. This can be done by calling a simple function in our open-sourced model inference API, MediaPipe Tasks. This entire process only takes a few minutes.
Elucidating the solution space of extended reverse-time SDE for diffusion models
Sep 26, 2023



Diffusion models (DMs) demonstrate potent image generation capabilities in various generative modeling tasks. Nevertheless, their primary limitation lies in slow sampling speed, requiring hundreds or thousands of sequential function evaluations through large neural networks to generate high-quality images. Sampling from DMs can be seen alternatively as solving corresponding stochastic differential equations (SDEs) or ordinary differential equations (ODEs). In this work, we formulate the sampling process as an extended reverse-time SDE (ER SDE), unifying prior explorations into ODEs and SDEs. Leveraging the semi-linear structure of ER SDE solutions, we offer exact solutions and arbitrarily high-order approximate solutions for VP SDE and VE SDE, respectively. Based on the solution space of the ER SDE, we yield mathematical insights elucidating the superior performance of ODE solvers over SDE solvers in terms of fast sampling. Additionally, we unveil that VP SDE solvers stand on par with their VE SDE counterparts. Finally, we devise fast and training-free samplers, ER-SDE-Solvers, achieving state-of-the-art performance across all stochastic samplers. Experimental results demonstrate achieving 3.45 FID in 20 function evaluations and 2.24 FID in 50 function evaluations on the ImageNet $64\times64$ dataset.
Improving Generalization Capability of Deep Learning-Based Nuclei Instance Segmentation by Non-deterministic Train Time and Deterministic Test Time Stain Normalization
Sep 12, 2023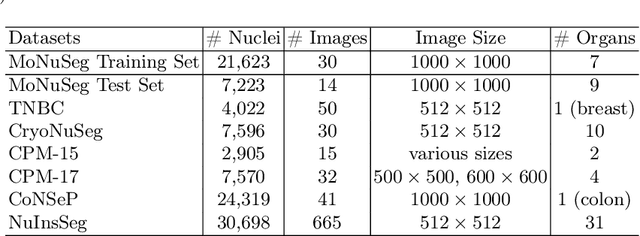
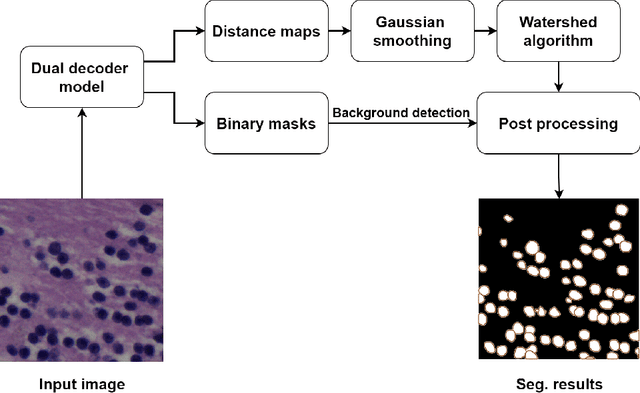
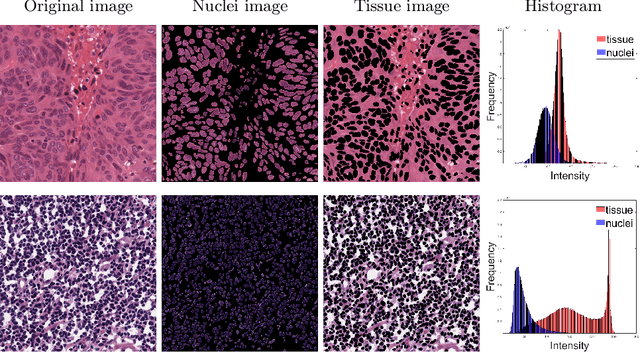

With the advent of digital pathology and microscopic systems that can scan and save whole slide histological images automatically, there is a growing trend to use computerized methods to analyze acquired images. Among different histopathological image analysis tasks, nuclei instance segmentation plays a fundamental role in a wide range of clinical and research applications. While many semi- and fully-automatic computerized methods have been proposed for nuclei instance segmentation, deep learning (DL)-based approaches have been shown to deliver the best performances. However, the performance of such approaches usually degrades when tested on unseen datasets. In this work, we propose a novel approach to improve the generalization capability of a DL-based automatic segmentation approach. Besides utilizing one of the state-of-the-art DL-based models as a baseline, our method incorporates non-deterministic train time and deterministic test time stain normalization. We trained the model with one single training set and evaluated its segmentation performance on seven test datasets. Our results show that the proposed method provides up to 5.77%, 5.36%, and 5.27% better performance in segmenting nuclei based on Dice score, aggregated Jaccard index, and panoptic quality score, respectively, compared to the baseline segmentation model.
Balancing Computational Efficiency and Forecast Error in Machine Learning-based Time-Series Forecasting: Insights from Live Experiments on Meteorological Nowcasting
Sep 26, 2023
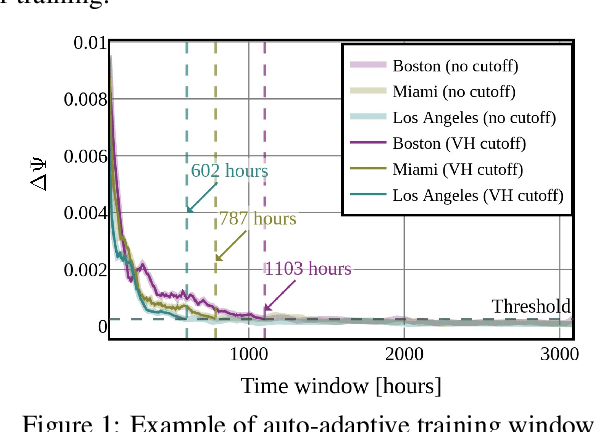
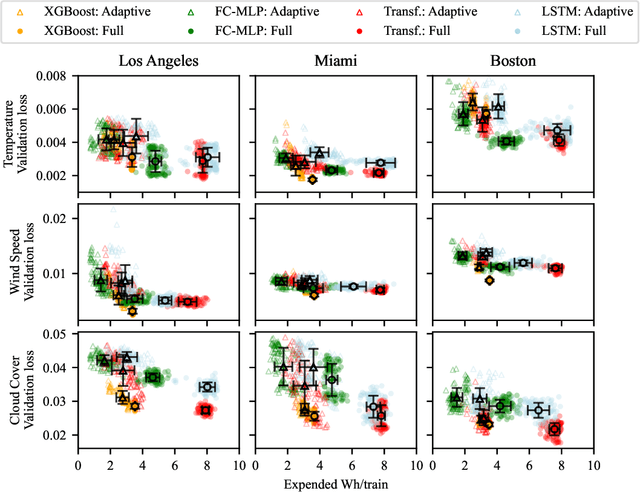
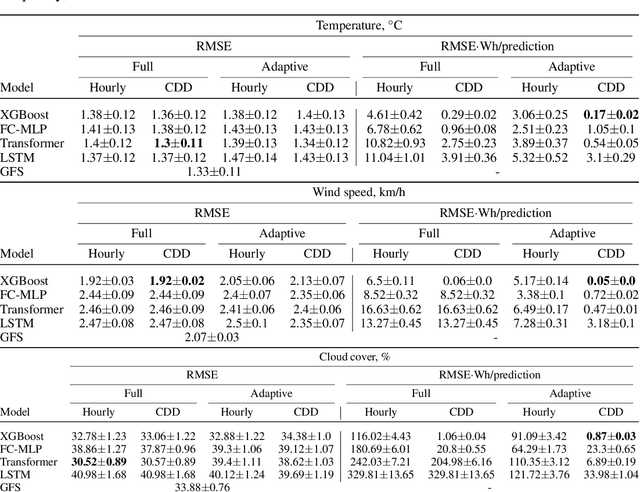
Machine learning for time-series forecasting remains a key area of research. Despite successful application of many machine learning techniques, relating computational efficiency to forecast error remains an under-explored domain. This paper addresses this topic through a series of real-time experiments to quantify the relationship between computational cost and forecast error using meteorological nowcasting as an example use-case. We employ a variety of popular regression techniques (XGBoost, FC-MLP, Transformer, and LSTM) for multi-horizon, short-term forecasting of three variables (temperature, wind speed, and cloud cover) for multiple locations. During a 5-day live experiment, 4000 data sources were streamed for training and inferencing 144 models per hour. These models were parameterized to explore forecast error for two computational cost minimization methods: a novel auto-adaptive data reduction technique (Variance Horizon) and a performance-based concept drift-detection mechanism. Forecast error of all model variations were benchmarked in real-time against a state-of-the-art numerical weather prediction model. Performance was assessed using classical and novel evaluation metrics. Results indicate that using the Variance Horizon reduced computational usage by more than 50\%, while increasing between 0-15\% in error. Meanwhile, performance-based retraining reduced computational usage by up to 90\% while \emph{also} improving forecast error by up to 10\%. Finally, the combination of both the Variance Horizon and performance-based retraining outperformed other model configurations by up to 99.7\% when considering error normalized to computational usage.
A Real-Time Multi-Task Learning System for Joint Detection of Face, Facial Landmark and Head Pose
Sep 21, 2023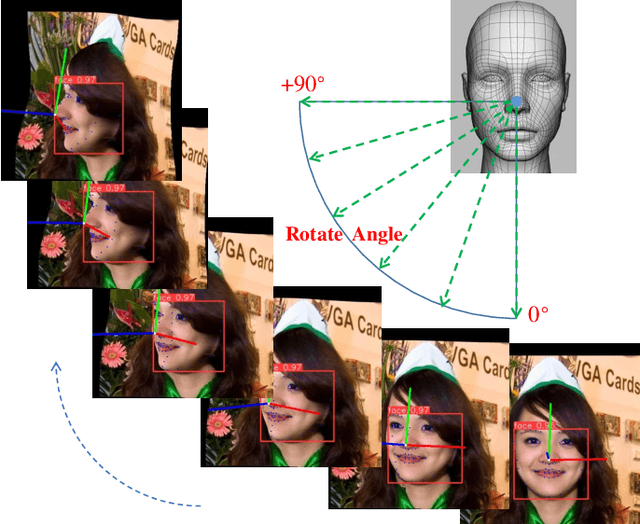
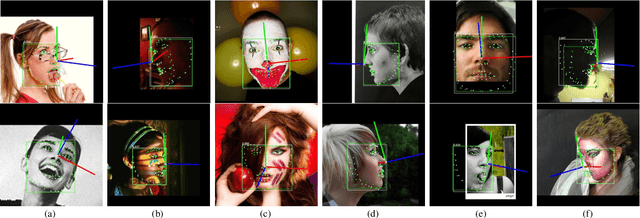

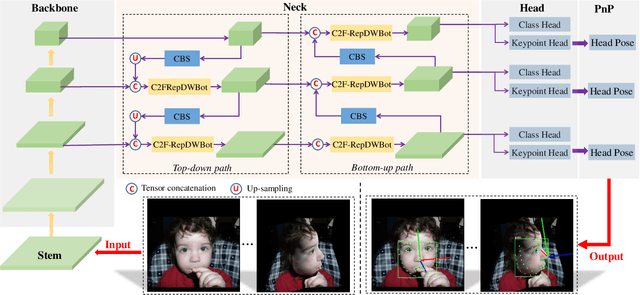
Extreme head postures pose a common challenge across a spectrum of facial analysis tasks, including face detection, facial landmark detection (FLD), and head pose estimation (HPE). These tasks are interdependent, where accurate FLD relies on robust face detection, and HPE is intricately associated with these key points. This paper focuses on the integration of these tasks, particularly when addressing the complexities posed by large-angle face poses. The primary contribution of this study is the proposal of a real-time multi-task detection system capable of simultaneously performing joint detection of faces, facial landmarks, and head poses. This system builds upon the widely adopted YOLOv8 detection framework. It extends the original object detection head by incorporating additional landmark regression head, enabling efficient localization of crucial facial landmarks. Furthermore, we conduct optimizations and enhancements on various modules within the original YOLOv8 framework. To validate the effectiveness and real-time performance of our proposed model, we conduct extensive experiments on 300W-LP and AFLW2000-3D datasets. The results obtained verify the capability of our model to tackle large-angle face pose challenges while delivering real-time performance across these interconnected tasks.