 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Vicinal Risk Minimization for Few-Shot Cross-lingual Transfer in Abusive Language Detection
Nov 03, 2023
Cross-lingual transfer learning from high-resource to medium and low-resource languages has shown encouraging results. However, the scarcity of resources in target languages remains a challenge. In this work, we resort to data augmentation and continual pre-training for domain adaptation to improve cross-lingual abusive language detection. For data augmentation, we analyze two existing techniques based on vicinal risk minimization and propose MIXAG, a novel data augmentation method which interpolates pairs of instances based on the angle of their representations. Our experiments involve seven languages typologically distinct from English and three different domains. The results reveal that the data augmentation strategies can enhance few-shot cross-lingual abusive language detection. Specifically, we observe that consistently in all target languages, MIXAG improves significantly in multidomain and multilingual environments. Finally, we show through an error analysis how the domain adaptation can favour the class of abusive texts (reducing false negatives), but at the same time, declines the precision of the abusive language detection model.
Maximum Likelihood Estimation of Flexible Survival Densities with Importance Sampling
Nov 03, 2023Survival analysis is a widely-used technique for analyzing time-to-event data in the presence of censoring. In recent years, numerous survival analysis methods have emerged which scale to large datasets and relax traditional assumptions such as proportional hazards. These models, while being performant, are very sensitive to model hyperparameters including: (1) number of bins and bin size for discrete models and (2) number of cluster assignments for mixture-based models. Each of these choices requires extensive tuning by practitioners to achieve optimal performance. In addition, we demonstrate in empirical studies that: (1) optimal bin size may drastically differ based on the metric of interest (e.g., concordance vs brier score), and (2) mixture models may suffer from mode collapse and numerical instability. We propose a survival analysis approach which eliminates the need to tune hyperparameters such as mixture assignments and bin sizes, reducing the burden on practitioners. We show that the proposed approach matches or outperforms baselines on several real-world datasets.
Solving MaxSAT with Matrix Multiplication
Nov 01, 2023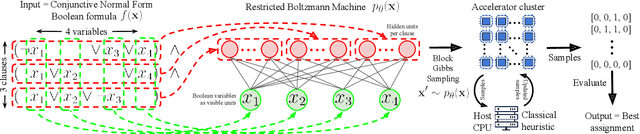
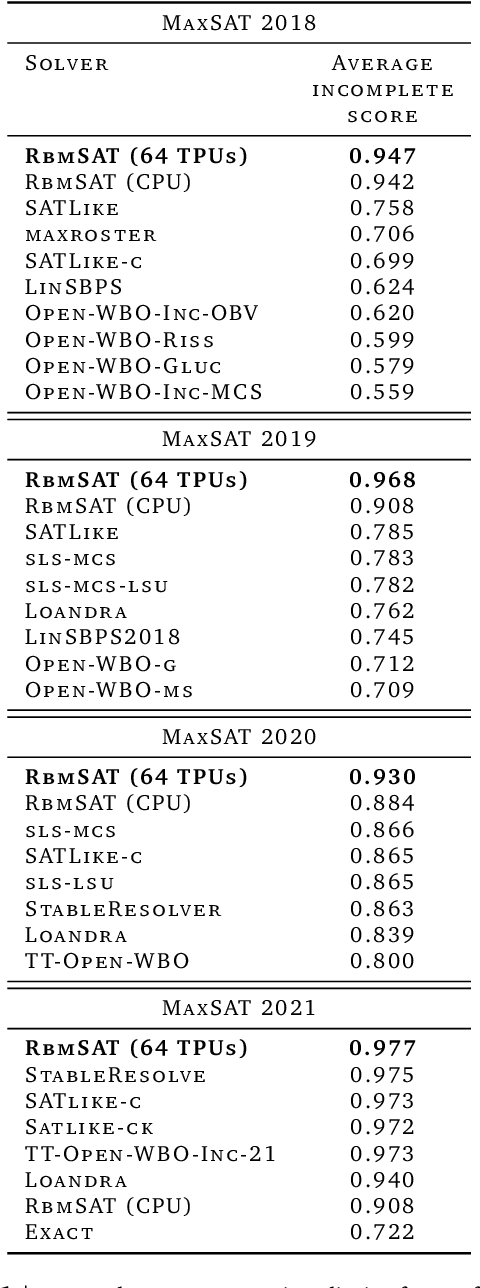
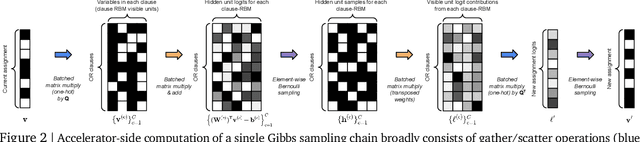
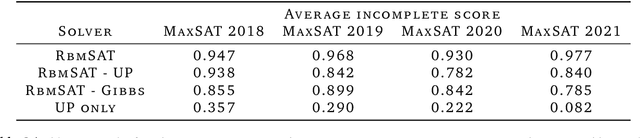
We propose an incomplete algorithm for Maximum Satisfiability (MaxSAT) specifically designed to run on neural network accelerators such as GPUs and TPUs. Given a MaxSAT problem instance in conjunctive normal form, our procedure constructs a Restricted Boltzmann Machine (RBM) with an equilibrium distribution wherein the probability of a Boolean assignment is exponential in the number of clauses it satisfies. Block Gibbs sampling is used to stochastically search the space of assignments with parallel Markov chains. Since matrix multiplication is the main computational primitive for block Gibbs sampling in an RBM, our approach leads to an elegantly simple algorithm (40 lines of JAX) well-suited for neural network accelerators. Theoretical results about RBMs guarantee that the required number of visible and hidden units of the RBM scale only linearly with the number of variables and constant-sized clauses in the MaxSAT instance, ensuring that the computational cost of a Gibbs step scales reasonably with the instance size. Search throughput can be increased by batching parallel chains within a single accelerator as well as by distributing them across multiple accelerators. As a further enhancement, a heuristic based on unit propagation running on CPU is periodically applied to the sampled assignments. Our approach, which we term RbmSAT, is a new design point in the algorithm-hardware co-design space for MaxSAT. We present timed results on a subset of problem instances from the annual MaxSAT Evaluation's Incomplete Unweighted Track for the years 2018 to 2021. When allotted the same running time and CPU compute budget (but no TPUs), RbmSAT outperforms other participating solvers on problems drawn from three out of the four years' competitions. Given the same running time on a TPU cluster for which RbmSAT is uniquely designed, it outperforms all solvers on problems drawn from all four years.
A quantum-classical performance separation in nonconvex optimization
Nov 01, 2023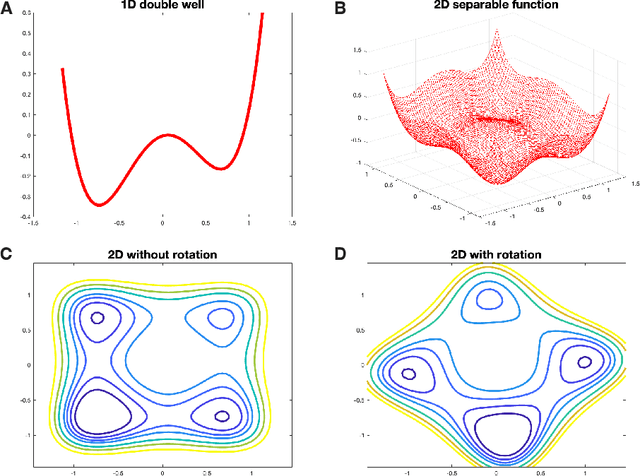
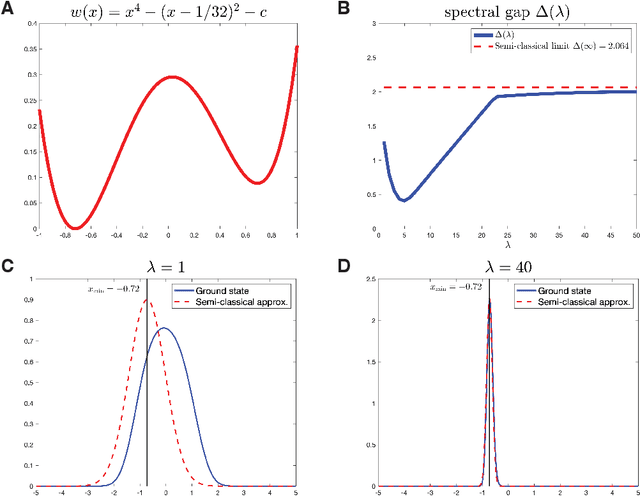
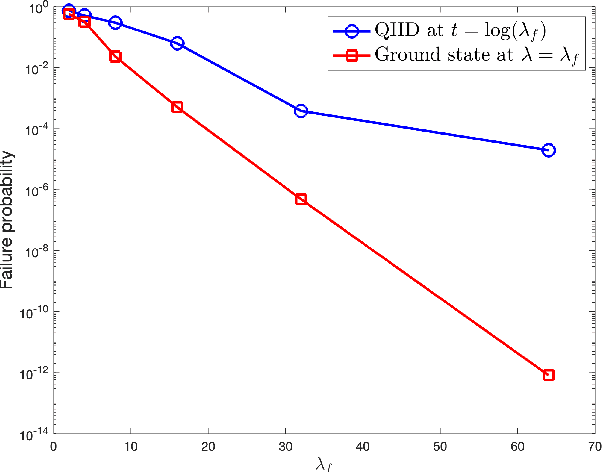
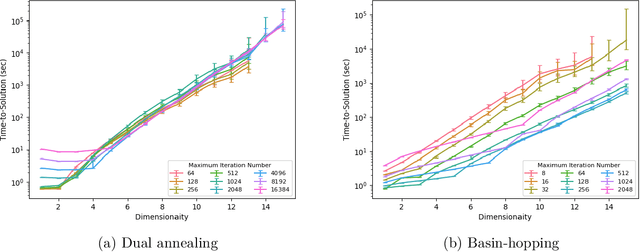
In this paper, we identify a family of nonconvex continuous optimization instances, each $d$-dimensional instance with $2^d$ local minima, to demonstrate a quantum-classical performance separation. Specifically, we prove that the recently proposed Quantum Hamiltonian Descent (QHD) algorithm [Leng et al., arXiv:2303.01471] is able to solve any $d$-dimensional instance from this family using $\widetilde{\mathcal{O}}(d^3)$ quantum queries to the function value and $\widetilde{\mathcal{O}}(d^4)$ additional 1-qubit and 2-qubit elementary quantum gates. On the other side, a comprehensive empirical study suggests that representative state-of-the-art classical optimization algorithms/solvers (including Gurobi) would require a super-polynomial time to solve such optimization instances.
Muscle volume quantification: guiding transformers with anatomical priors
Oct 31, 2023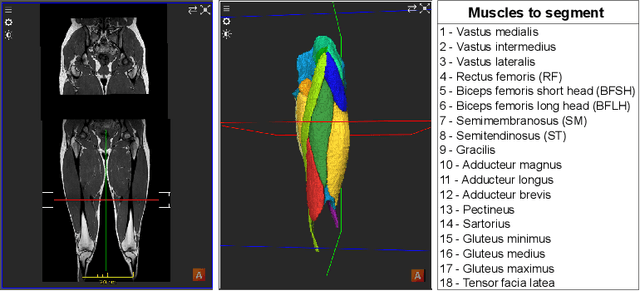
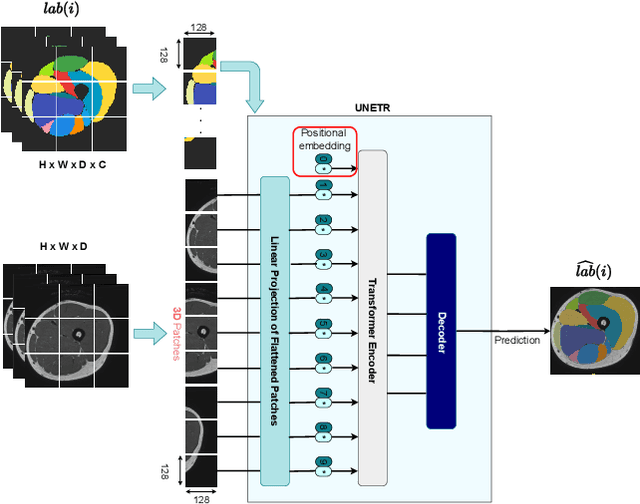
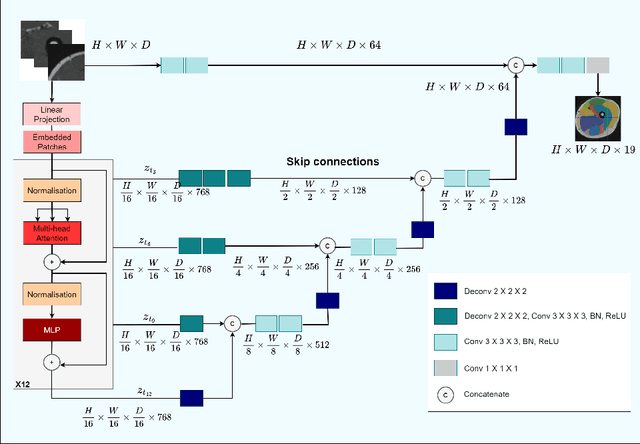
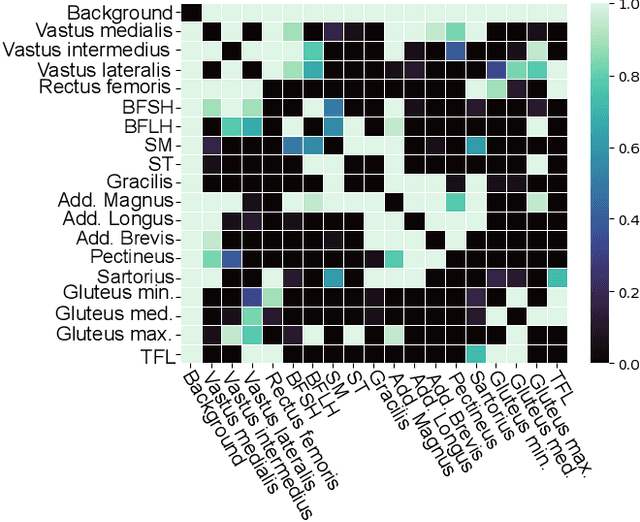
Muscle volume is a useful quantitative biomarker in sports, but also for the follow-up of degenerative musculo-skelletal diseases. In addition to volume, other shape biomarkers can be extracted by segmenting the muscles of interest from medical images. Manual segmentation is still today the gold standard for such measurements despite being very time-consuming. We propose a method for automatic segmentation of 18 muscles of the lower limb on 3D Magnetic Resonance Images to assist such morphometric analysis. By their nature, the tissue of different muscles is undistinguishable when observed in MR Images. Thus, muscle segmentation algorithms cannot rely on appearance but only on contour cues. However, such contours are hard to detect and their thickness varies across subjects. To cope with the above challenges, we propose a segmentation approach based on a hybrid architecture, combining convolutional and visual transformer blocks. We investigate for the first time the behaviour of such hybrid architectures in the context of muscle segmentation for shape analysis. Considering the consistent anatomical muscle configuration, we rely on transformer blocks to capture the longrange relations between the muscles. To further exploit the anatomical priors, a second contribution of this work consists in adding a regularisation loss based on an adjacency matrix of plausible muscle neighbourhoods estimated from the training data. Our experimental results on a unique database of elite athletes show it is possible to train complex hybrid models from a relatively small database of large volumes, while the anatomical prior regularisation favours better predictions.
Relation Extraction from News Articles (RENA): A Tool for Epidemic Surveillance
Oct 31, 2023Relation Extraction from News Articles (RENA) is a browser-based tool designed to extract key entities and their semantic relationships in English language news articles related to infectious diseases. Constructed using the React framework, this system presents users with an elegant and user-friendly interface. It enables users to input a news article and select from a choice of two models to generate a comprehensive list of relations within the provided text. As a result, RENA allows real-time parsing of news articles to extract key information for epidemic surveillance, contributing to EPIWATCH, an open-source intelligence-based epidemic warning system.
Generative Structural Design Integrating BIM and Diffusion Model
Nov 07, 2023Intelligent structural design using AI can effectively reduce time overhead and increase efficiency. It has potential to become the new design paradigm in the future to assist and even replace engineers, and so it has become a research hotspot in the academic community. However, current methods have some limitations to be addressed, whether in terms of application scope, visual quality of generated results, or evaluation metrics of results. This study proposes a comprehensive solution. Firstly, we introduce building information modeling (BIM) into intelligent structural design and establishes a structural design pipeline integrating BIM and generative AI, which is a powerful supplement to the previous frameworks that only considered CAD drawings. In order to improve the perceptual quality and details of generations, this study makes 3 contributions. Firstly, in terms of generation framework, inspired by the process of human drawing, a novel 2-stage generation framework is proposed to replace the traditional end-to-end framework to reduce the generation difficulty for AI models. Secondly, in terms of generative AI tools adopted, diffusion models (DMs) are introduced to replace widely used generative adversarial network (GAN)-based models, and a novel physics-based conditional diffusion model (PCDM) is proposed to consider different design prerequisites. Thirdly, in terms of neural networks, an attention block (AB) consisting of a self-attention block (SAB) and a parallel cross-attention block (PCAB) is designed to facilitate cross-domain data fusion. The quantitative and qualitative results demonstrate the powerful generation and representation capabilities of PCDM. Necessary ablation studies are conducted to examine the validity of the methods. This study also shows that DMs have the potential to replace GANs and become the new benchmark for generative problems in civil engineering.
Memory AMP for Generalized MIMO: Coding Principle and Information-Theoretic Optimality
Nov 07, 2023To support complex communication scenarios in next-generation wireless communications, this paper focuses on a generalized MIMO (GMIMO) with practical assumptions, such as massive antennas, practical channel coding, arbitrary input distributions, and general right-unitarily-invariant channel matrices (covering Rayleigh fading, certain ill-conditioned and correlated channel matrices). The orthogonal/vector approximate message passing (OAMP/VAMP) receiver has been proved to be information-theoretically optimal in GMIMO, but it is limited to high-complexity LMMSE. To solve this problem, a low-complexity memory approximate message passing (MAMP) receiver has recently been shown to be Bayes optimal but limited to uncoded systems. Therefore, how to design a low-complexity and information-theoretically optimal receiver for GMIMO is still an open issue. To address this issue, this paper proposes an information-theoretically optimal MAMP receiver and investigates its achievable rate analysis and optimal coding principle. Specifically, due to the long-memory linear detection, state evolution (SE) for MAMP is intricately multidimensional and cannot be used directly to analyze its achievable rate. To avoid this difficulty, a simplified single-input single-output variational SE (VSE) for MAMP is developed by leveraging the SE fixed-point consistent property of MAMP and OAMP/VAMP. The achievable rate of MAMP is calculated using the VSE, and the optimal coding principle is established to maximize the achievable rate. On this basis, the information-theoretic optimality of MAMP is proved rigorously. Numerical results show that the finite-length performances of MAMP with practical optimized LDPC codes are 0.5-2.7 dB away from the associated constrained capacities. It is worth noting that MAMP can achieve the same performances as OAMP/VAMP with 0.4% of the time consumption for large-scale systems.
Watermarks in the Sand: Impossibility of Strong Watermarking for Generative Models
Nov 07, 2023Watermarking generative models consists of planting a statistical signal (watermark) in a model's output so that it can be later verified that the output was generated by the given model. A strong watermarking scheme satisfies the property that a computationally bounded attacker cannot erase the watermark without causing significant quality degradation. In this paper, we study the (im)possibility of strong watermarking schemes. We prove that, under well-specified and natural assumptions, strong watermarking is impossible to achieve. This holds even in the private detection algorithm setting, where the watermark insertion and detection algorithms share a secret key, unknown to the attacker. To prove this result, we introduce a generic efficient watermark attack; the attacker is not required to know the private key of the scheme or even which scheme is used. Our attack is based on two assumptions: (1) The attacker has access to a "quality oracle" that can evaluate whether a candidate output is a high-quality response to a prompt, and (2) The attacker has access to a "perturbation oracle" which can modify an output with a nontrivial probability of maintaining quality, and which induces an efficiently mixing random walk on high-quality outputs. We argue that both assumptions can be satisfied in practice by an attacker with weaker computational capabilities than the watermarked model itself, to which the attacker has only black-box access. Furthermore, our assumptions will likely only be easier to satisfy over time as models grow in capabilities and modalities. We demonstrate the feasibility of our attack by instantiating it to attack three existing watermarking schemes for large language models: Kirchenbauer et al. (2023), Kuditipudi et al. (2023), and Zhao et al. (2023). The same attack successfully removes the watermarks planted by all three schemes, with only minor quality degradation.
On-device Real-time Custom Hand Gesture Recognition
Sep 19, 2023Most existing hand gesture recognition (HGR) systems are limited to a predefined set of gestures. However, users and developers often want to recognize new, unseen gestures. This is challenging due to the vast diversity of all plausible hand shapes, e.g. it is impossible for developers to include all hand gestures in a predefined list. In this paper, we present a user-friendly framework that lets users easily customize and deploy their own gesture recognition pipeline. Our framework provides a pre-trained single-hand embedding model that can be fine-tuned for custom gesture recognition. Users can perform gestures in front of a webcam to collect a small amount of images per gesture. We also offer a low-code solution to train and deploy the custom gesture recognition model. This makes it easy for users with limited ML expertise to use our framework. We further provide a no-code web front-end for users without any ML expertise. This makes it even easier to build and test the end-to-end pipeline. The resulting custom HGR is then ready to be run on-device for real-time scenarios. This can be done by calling a simple function in our open-sourced model inference API, MediaPipe Tasks. This entire process only takes a few minutes.