 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Generic Anomaly Detection and Understanding: Large-scale Visual-linguistic Model (GPT-4V) Takes the Lead
Nov 05, 2023
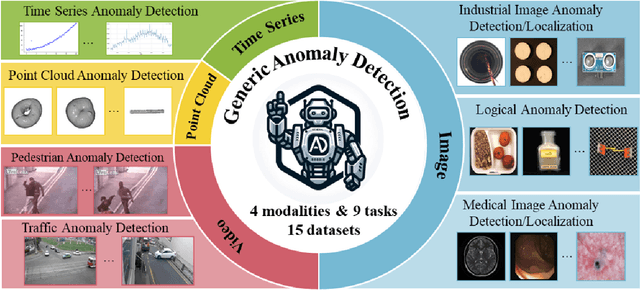
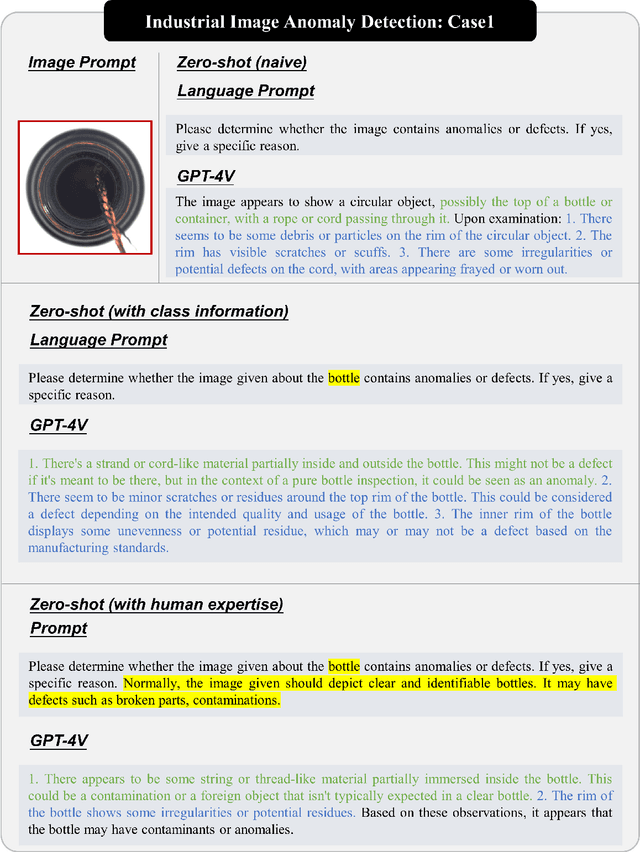

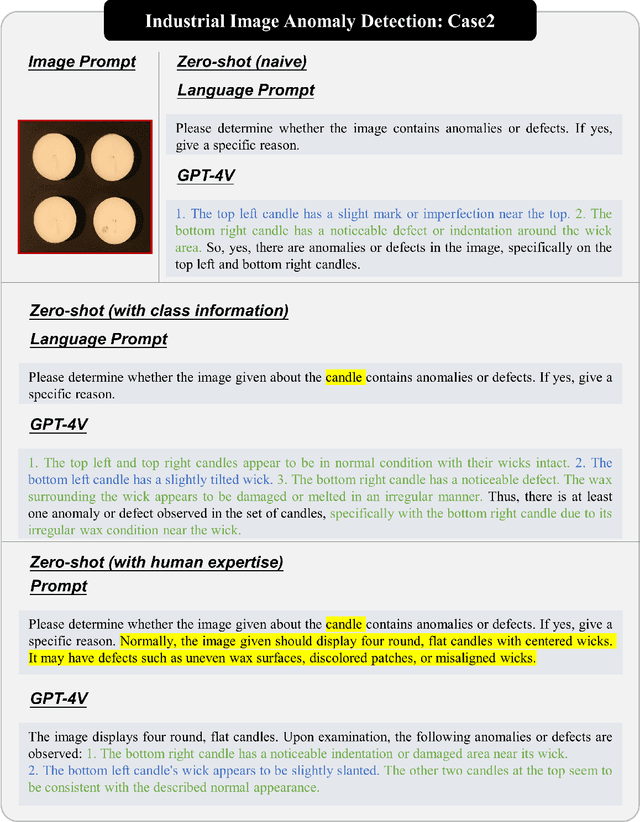
Anomaly detection is a crucial task across different domains and data types. However, existing anomaly detection models are often designed for specific domains and modalities. This study explores the use of GPT-4V(ision), a powerful visual-linguistic model, to address anomaly detection tasks in a generic manner. We investigate the application of GPT-4V in multi-modality, multi-domain anomaly detection tasks, including image, video, point cloud, and time series data, across multiple application areas, such as industrial, medical, logical, video, 3D anomaly detection, and localization tasks. To enhance GPT-4V's performance, we incorporate different kinds of additional cues such as class information, human expertise, and reference images as prompts.Based on our experiments, GPT-4V proves to be highly effective in detecting and explaining global and fine-grained semantic patterns in zero/one-shot anomaly detection. This enables accurate differentiation between normal and abnormal instances. Although we conducted extensive evaluations in this study, there is still room for future evaluation to further exploit GPT-4V's generic anomaly detection capacity from different aspects. These include exploring quantitative metrics, expanding evaluation benchmarks, incorporating multi-round interactions, and incorporating human feedback loops. Nevertheless, GPT-4V exhibits promising performance in generic anomaly detection and understanding, thus opening up a new avenue for anomaly detection.
MuSHRoom: Multi-Sensor Hybrid Room Dataset for Joint 3D Reconstruction and Novel View Synthesis
Nov 05, 2023Metaverse technologies demand accurate, real-time, and immersive modeling on consumer-grade hardware for both non-human perception (e.g., drone/robot/autonomous car navigation) and immersive technologies like AR/VR, requiring both structural accuracy and photorealism. However, there exists a knowledge gap in how to apply geometric reconstruction and photorealism modeling (novel view synthesis) in a unified framework. To address this gap and promote the development of robust and immersive modeling and rendering with consumer-grade devices, first, we propose a real-world Multi-Sensor Hybrid Room Dataset (MuSHRoom). Our dataset presents exciting challenges and requires state-of-the-art methods to be cost-effective, robust to noisy data and devices, and can jointly learn 3D reconstruction and novel view synthesis, instead of treating them as separate tasks, making them ideal for real-world applications. Second, we benchmark several famous pipelines on our dataset for joint 3D mesh reconstruction and novel view synthesis. Finally, in order to further improve the overall performance, we propose a new method that achieves a good trade-off between the two tasks. Our dataset and benchmark show great potential in promoting the improvements for fusing 3D reconstruction and high-quality rendering in a robust and computationally efficient end-to-end fashion.
On the Opportunities of Green Computing: A Survey
Nov 06, 2023
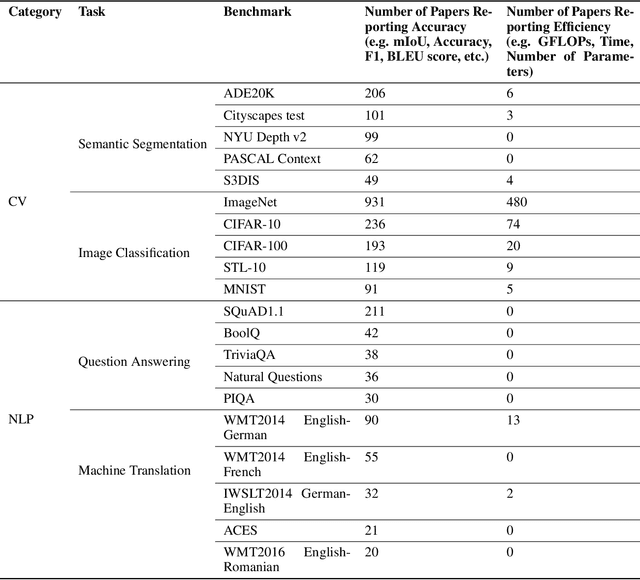
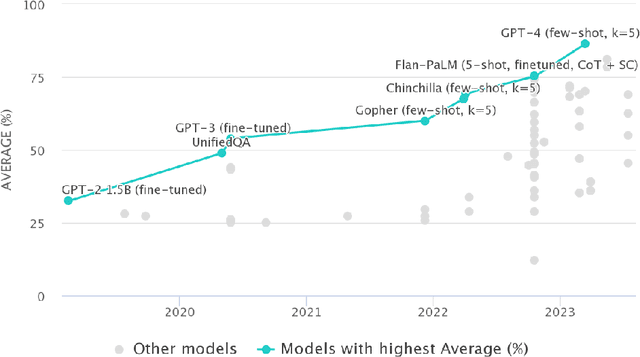
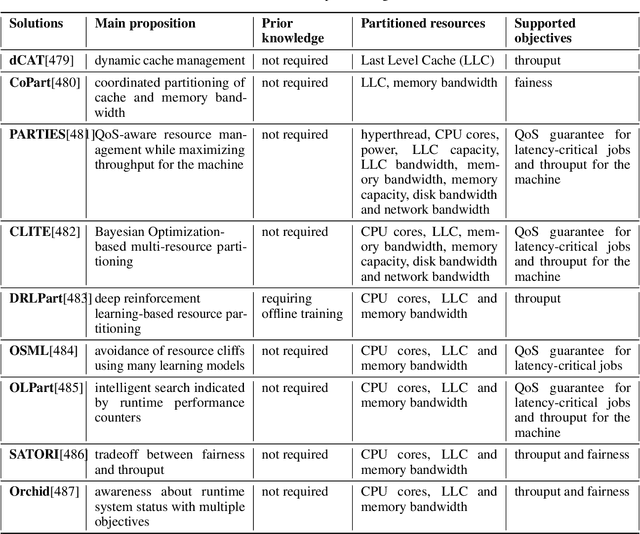
Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
LitSumm: Large language models for literature summarisation of non-coding RNAs
Nov 06, 2023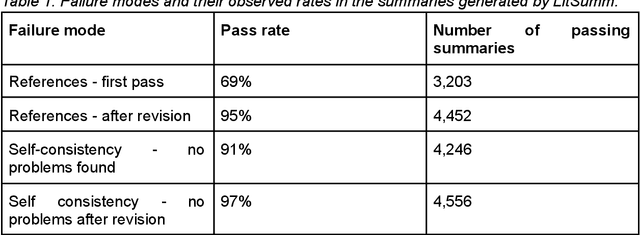

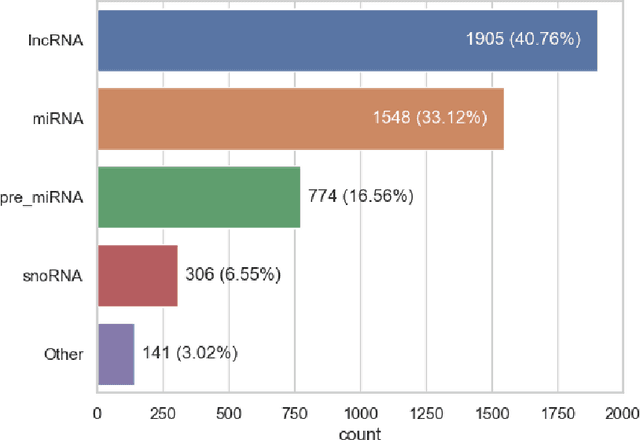
Motivation: Curation of literature in life sciences is a growing challenge. The continued increase in the rate of publication, coupled with the relatively fixed number of curators worldwide presents a major challenge to developers of biomedical knowledgebases. Very few knowledgebases have resources to scale to the whole relevant literature and all have to prioritise their efforts. Results: In this work, we take a first step to alleviating the lack of curator time in RNA science by generating summaries of literature for non-coding RNAs using large language models (LLMs). We demonstrate that high-quality, factually accurate summaries with accurate references can be automatically generated from the literature using a commercial LLM and a chain of prompts and checks. Manual assessment was carried out for a subset of summaries, with the majority being rated extremely high quality. We also applied the most commonly used automated evaluation approaches, finding that they do not correlate with human assessment. Finally, we apply our tool to a selection of over 4,600 ncRNAs and make the generated summaries available via the RNAcentral resource. We conclude that automated literature summarization is feasible with the current generation of LLMs, provided careful prompting and automated checking are applied. Availability: Code used to produce these summaries can be found here: https://github.com/RNAcentral/litscan-summarization and the dataset of contexts and summaries can be found here: https://huggingface.co/datasets/RNAcentral/litsumm-v1. Summaries are also displayed on the RNA report pages in RNAcentral (https://rnacentral.org/)
Distributed Matrix-Based Sampling for Graph Neural Network Training
Nov 06, 2023The primary contribution of this paper is new methods for reducing communication in the sampling step for distributed GNN training. Here, we propose a matrix-based bulk sampling approach that expresses sampling as a sparse matrix multiplication (SpGEMM) and samples multiple minibatches at once. When the input graph topology does not fit on a single device, our method distributes the graph and use communication-avoiding SpGEMM algorithms to scale GNN minibatch sampling, enabling GNN training on much larger graphs than those that can fit into a single device memory. When the input graph topology (but not the embeddings) fits in the memory of one GPU, our approach (1) performs sampling without communication, (2) amortizes the overheads of sampling a minibatch, and (3) can represent multiple sampling algorithms by simply using different matrix constructions. In addition to new methods for sampling, we show that judiciously replicating feature data with a simple all-to-all exchange can outperform current methods for the feature extraction step in distributed GNN training. We provide experimental results on the largest Open Graph Benchmark (OGB) datasets on $128$ GPUs, and show that our pipeline is $2.5\times$ faster Quiver (a distributed extension to PyTorch-Geometric) on a $3$-layer GraphSAGE network. On datasets outside of OGB, we show a $8.46\times$ speedup on $128$ GPUs in-per epoch time. Finally, we show scaling when the graph is distributed across GPUs and scaling for both node-wise and layer-wise sampling algorithms
Proactive Robot Control for Collaborative Manipulation Using Human Intent
Nov 06, 2023Collaborative manipulation task often requires negotiation using explicit or implicit communication. An important example is determining where to move when the goal destination is not uniquely specified, and who should lead the motion. This work is motivated by the ability of humans to communicate the desired destination of motion through back-and-forth force exchanges. Inherent to these exchanges is also the ability to dynamically assign a role to each participant, either taking the initiative or deferring to the partner's lead. In this paper, we propose a hierarchical robot control framework that emulates human behavior in communicating a motion destination to a human collaborator and in responding to their actions. At the top level, the controller consists of a set of finite-state machines corresponding to different levels of commitment of the robot to its desired goal configuration. The control architecture is loosely based on the human strategy observed in the human-human experiments, and the key component is a real-time intent recognizer that helps the robot respond to human actions. We describe the details of the control framework, and feature engineering and training process of the intent recognition. The proposed controller was implemented on a UR10e robot (Universal Robots) and evaluated through human studies. The experiments show that the robot correctly recognizes and responds to human input, communicates its intent clearly, and resolves conflict. We report success rates and draw comparisons with human-human experiments to demonstrate the effectiveness of the approach.
Generative Fractional Diffusion Models
Oct 26, 2023We generalize the continuous time framework for score-based generative models from an underlying Brownian motion (BM) to an approximation of fractional Brownian motion (FBM). We derive a continuous reparameterization trick and the reverse time model by representing FBM as a stochastic integral over a family of Ornstein-Uhlenbeck processes to define generative fractional diffusion models (GFDM) with driving noise converging to a non-Markovian process of infinite quadratic variation. The Hurst index $H\in(0,1)$ of FBM enables control of the roughness of the distribution transforming path. To the best of our knowledge, this is the first attempt to build a generative model upon a stochastic process with infinite quadratic variation.
DynPoint: Dynamic Neural Point For View Synthesis
Oct 29, 2023The introduction of neural radiance fields has greatly improved the effectiveness of view synthesis for monocular videos. However, existing algorithms face difficulties when dealing with uncontrolled or lengthy scenarios, and require extensive training time specific to each new scenario. To tackle these limitations, we propose DynPoint, an algorithm designed to facilitate the rapid synthesis of novel views for unconstrained monocular videos. Rather than encoding the entirety of the scenario information into a latent representation, DynPoint concentrates on predicting the explicit 3D correspondence between neighboring frames to realize information aggregation. Specifically, this correspondence prediction is achieved through the estimation of consistent depth and scene flow information across frames. Subsequently, the acquired correspondence is utilized to aggregate information from multiple reference frames to a target frame, by constructing hierarchical neural point clouds. The resulting framework enables swift and accurate view synthesis for desired views of target frames. The experimental results obtained demonstrate the considerable acceleration of training time achieved - typically an order of magnitude - by our proposed method while yielding comparable outcomes compared to prior approaches. Furthermore, our method exhibits strong robustness in handling long-duration videos without learning a canonical representation of video content.
Blendshapes GHUM: Real-time Monocular Facial Blendshape Prediction
Sep 11, 2023
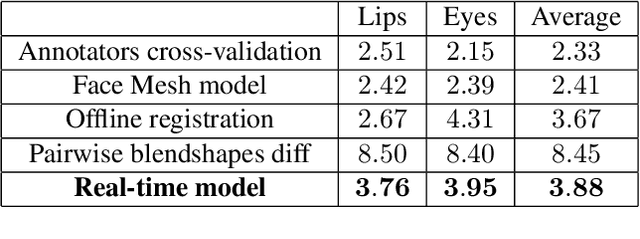
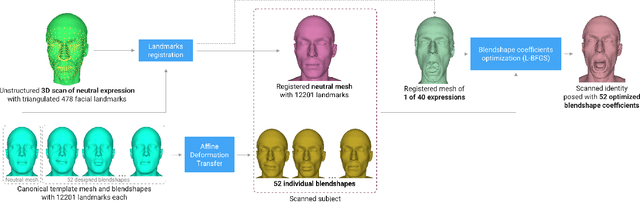
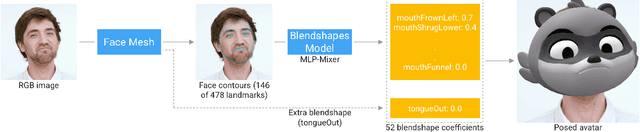
We present Blendshapes GHUM, an on-device ML pipeline that predicts 52 facial blendshape coefficients at 30+ FPS on modern mobile phones, from a single monocular RGB image and enables facial motion capture applications like virtual avatars. Our main contributions are: i) an annotation-free offline method for obtaining blendshape coefficients from real-world human scans, ii) a lightweight real-time model that predicts blendshape coefficients based on facial landmarks.
Leveraging Large Language Models for Collective Decision-Making
Nov 03, 2023In various work contexts, such as meeting scheduling, collaborating, and project planning, collective decision-making is essential but often challenging due to diverse individual preferences, varying work focuses, and power dynamics among members. To address this, we propose a system leveraging Large Language Models (LLMs) to facilitate group decision-making by managing conversations and balancing preferences among individuals. Our system extracts individual preferences and suggests options that satisfy a significant portion of the members. We apply this system to corporate meeting scheduling. We create synthetic employee profiles and simulate conversations at scale, leveraging LLMs to evaluate the system. Our results indicate efficient coordination with reduced interactions between members and the LLM-based system. The system also effectively refines proposed options over time, ensuring their quality and equity. Finally, we conduct a survey study involving human participants to assess our system's ability to aggregate preferences and reasoning. Our findings show that the system exhibits strong performance in both dimensions.