 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distribution-Aware Continual Test Time Adaptation for Semantic Segmentation
Sep 24, 2023
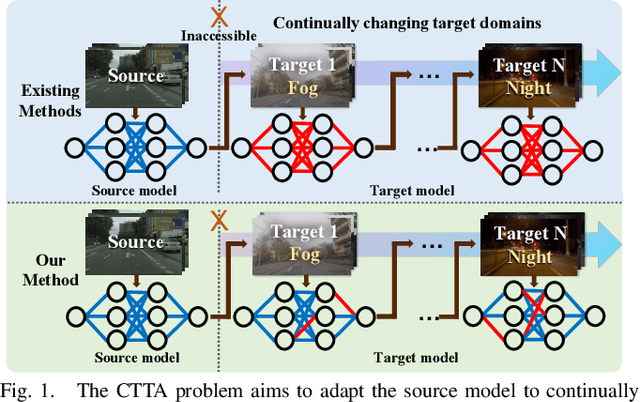
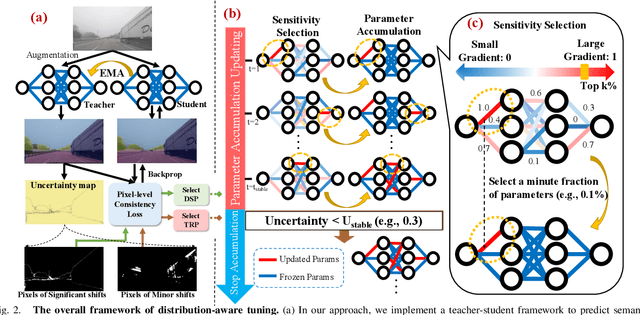
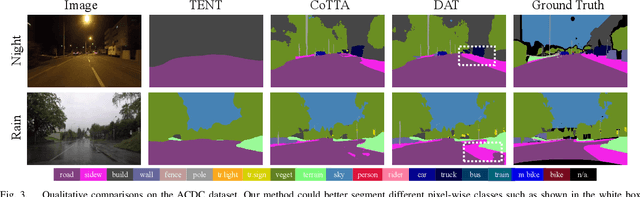

Since autonomous driving systems usually face dynamic and ever-changing environments, continual test-time adaptation (CTTA) has been proposed as a strategy for transferring deployed models to continually changing target domains. However, the pursuit of long-term adaptation often introduces catastrophic forgetting and error accumulation problems, which impede the practical implementation of CTTA in the real world. Recently, existing CTTA methods mainly focus on utilizing a majority of parameters to fit target domain knowledge through self-training. Unfortunately, these approaches often amplify the challenge of error accumulation due to noisy pseudo-labels, and pose practical limitations stemming from the heavy computational costs associated with entire model updates. In this paper, we propose a distribution-aware tuning (DAT) method to make the semantic segmentation CTTA efficient and practical in real-world applications. DAT adaptively selects and updates two small groups of trainable parameters based on data distribution during the continual adaptation process, including domain-specific parameters (DSP) and task-relevant parameters (TRP). Specifically, DSP exhibits sensitivity to outputs with substantial distribution shifts, effectively mitigating the problem of error accumulation. In contrast, TRP are allocated to positions that are responsive to outputs with minor distribution shifts, which are fine-tuned to avoid the catastrophic forgetting problem. In addition, since CTTA is a temporal task, we introduce the Parameter Accumulation Update (PAU) strategy to collect the updated DSP and TRP in target domain sequences. We conduct extensive experiments on two widely-used semantic segmentation CTTA benchmarks, achieving promising performance compared to previous state-of-the-art methods.
Deep Reinforcement Learning-based Intelligent Traffic Signal Controls with Optimized CO2 emissions
Oct 23, 2023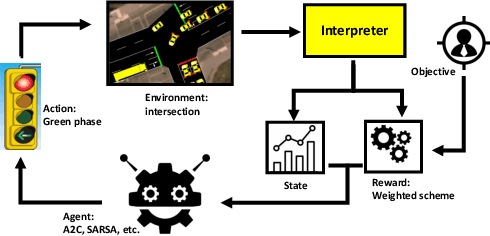
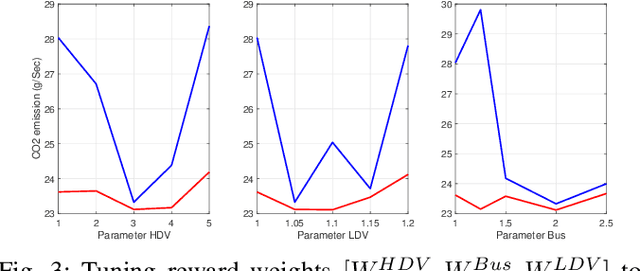
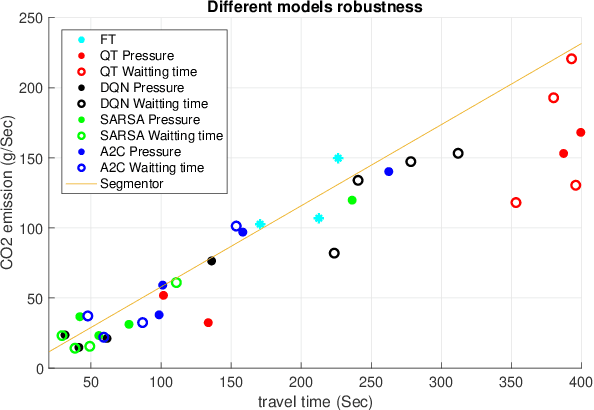
Nowadays, transportation networks face the challenge of sub-optimal control policies that can have adverse effects on human health, the environment, and contribute to traffic congestion. Increased levels of air pollution and extended commute times caused by traffic bottlenecks make intersection traffic signal controllers a crucial component of modern transportation infrastructure. Despite several adaptive traffic signal controllers in literature, limited research has been conducted on their comparative performance. Furthermore, despite carbon dioxide (CO2) emissions' significance as a global issue, the literature has paid limited attention to this area. In this report, we propose EcoLight, a reward shaping scheme for reinforcement learning algorithms that not only reduces CO2 emissions but also achieves competitive results in metrics such as travel time. We compare the performance of tabular Q-Learning, DQN, SARSA, and A2C algorithms using metrics such as travel time, CO2 emissions, waiting time, and stopped time. Our evaluation considers multiple scenarios that encompass a range of road users (trucks, buses, cars) with varying pollution levels.
Towards Streaming Speech-to-Avatar Synthesis
Oct 25, 2023
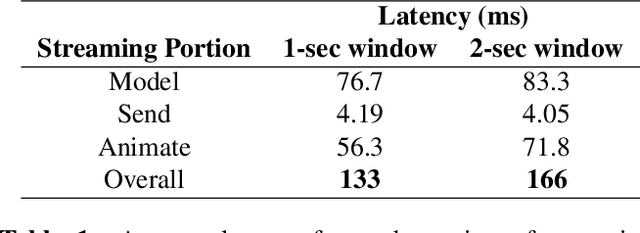
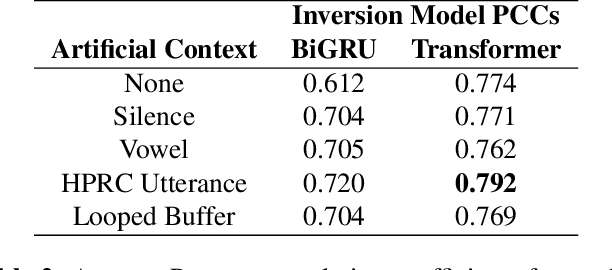

Streaming speech-to-avatar synthesis creates real-time animations for a virtual character from audio data. Accurate avatar representations of speech are important for the visualization of sound in linguistics, phonetics, and phonology, visual feedback to assist second language acquisition, and virtual embodiment for paralyzed patients. Previous works have highlighted the capability of deep articulatory inversion to perform high-quality avatar animation using electromagnetic articulography (EMA) features. However, these models focus on offline avatar synthesis with recordings rather than real-time audio, which is necessary for live avatar visualization or embodiment. To address this issue, we propose a method using articulatory inversion for streaming high quality facial and inner-mouth avatar animation from real-time audio. Our approach achieves 130ms average streaming latency for every 0.1 seconds of audio with a 0.792 correlation with ground truth articulations. Finally, we show generated mouth and tongue animations to demonstrate the efficacy of our methodology.
An Approach for Efficient Neural Architecture Search Space Definition
Oct 25, 2023As we advance in the fast-growing era of Machine Learning, various new and more complex neural architectures are arising to tackle problem more efficiently. On the one hand their efficient usage requires advanced knowledge and expertise, which is most of the time difficult to find on the labor market. On the other hand, searching for an optimized neural architecture is a time-consuming task when it is performed manually using a trial and error approach. Hence, a method and a tool support is needed to assist users of neural architectures, leading to an eagerness in the field of Automatic Machine Learning (AutoML). When it comes to Deep Learning, an important part of AutoML is the Neural Architecture Search (NAS). In this paper, we propose a novel cell-based hierarchical search space, easy to comprehend and manipulate. The objectives of the proposed approach are to optimize the search-time and to be general enough to handle most of state of the art Convolutional Neural Networks (CNN) architectures.
A Chronological Survey of Theoretical Advancements in Generative Adversarial Networks for Computer Vision
Nov 02, 2023Generative Adversarial Networks (GANs) have been workhorse generative models for last many years, especially in the research field of computer vision. Accordingly, there have been many significant advancements in the theory and application of GAN models, which are notoriously hard to train, but produce good results if trained well. There have been many a surveys on GANs, organizing the vast GAN literature from various focus and perspectives. However, none of the surveys brings out the important chronological aspect: how the multiple challenges of employing GAN models were solved one-by-one over time, across multiple landmark research works. This survey intends to bridge that gap and present some of the landmark research works on the theory and application of GANs, in chronological order.
Online non-parametric likelihood-ratio estimation by Pearson-divergence functional minimization
Nov 03, 2023Quantifying the difference between two probability density functions, $p$ and $q$, using available data, is a fundamental problem in Statistics and Machine Learning. A usual approach for addressing this problem is the likelihood-ratio estimation (LRE) between $p$ and $q$, which -- to our best knowledge -- has been investigated mainly for the offline case. This paper contributes by introducing a new framework for online non-parametric LRE (OLRE) for the setting where pairs of iid observations $(x_t \sim p, x'_t \sim q)$ are observed over time. The non-parametric nature of our approach has the advantage of being agnostic to the forms of $p$ and $q$. Moreover, we capitalize on the recent advances in Kernel Methods and functional minimization to develop an estimator that can be efficiently updated online. We provide theoretical guarantees for the performance of the OLRE method along with empirical validation in synthetic experiments.
Tuning-less Object Naming with a Foundation Model
Nov 03, 2023
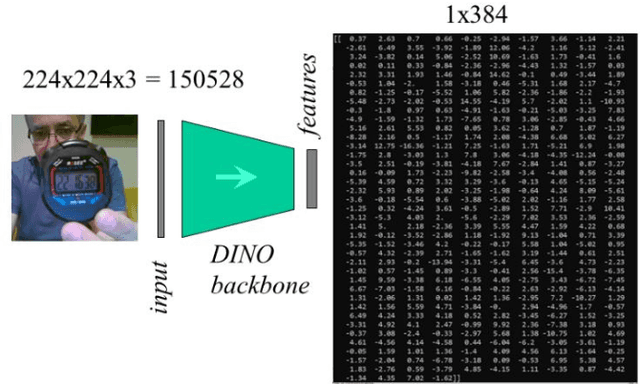
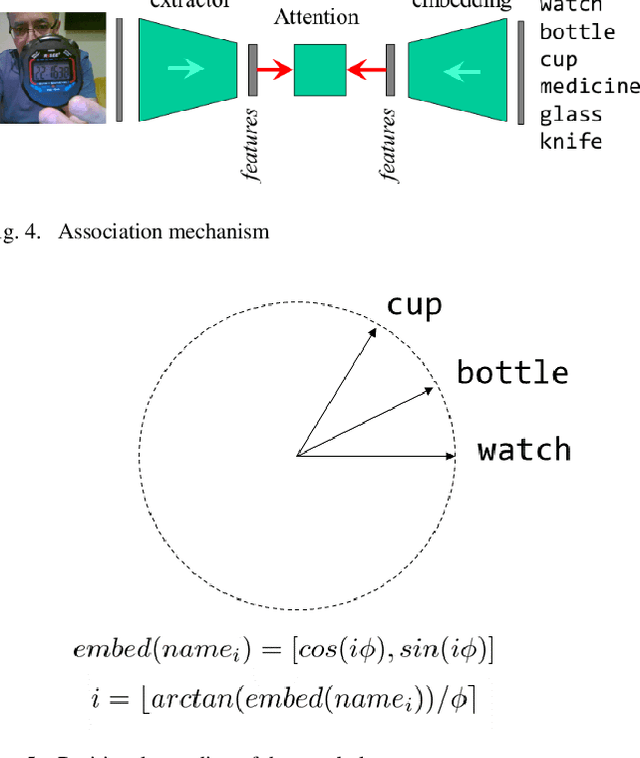
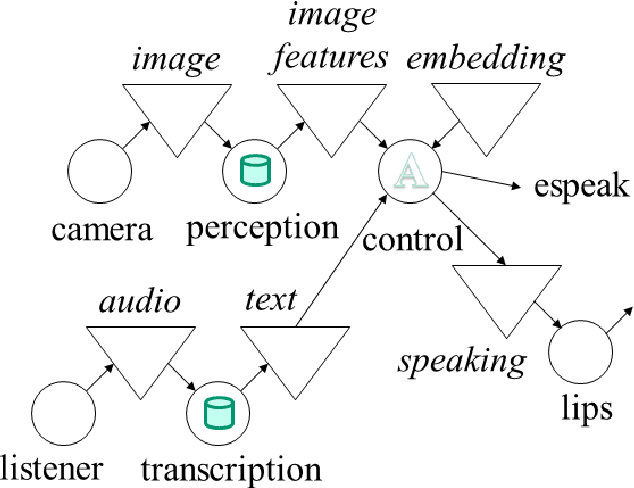
We implement a real-time object naming system that enables learning a set of named entities never seen. Our approach employs an existing foundation model that we consider ready to see anything before starting. It turns seen images into relatively small feature vectors that we associate with index to a gradually built vocabulary without any training of fine-tuning of the model. Our contribution is using the association mechanism known from transformers as attention. It has features that support generalization from irrelevant information for distinguishing the entities and potentially enable associating with much more than indices to vocabulary. As a result, the system can work in a one-shot manner and correctly name objects named in different contents. We also outline implementation details of the system modules integrated by a blackboard architecture. Finally, we investigate the system's quality, mainly how many objects it can handle in this way.
* https://github.com/andylucny/whatisthis
DySurv: Dynamic Deep Learning Model for Survival Prediction in the ICU
Oct 28, 2023Survival analysis helps approximate underlying distributions of time-to-events which in the case of critical care like in the ICU can be a powerful tool for dynamic mortality risk prediction. Extending beyond the classical Cox model, deep learning techniques have been leveraged over the last years relaxing the many constraints of their counterparts from statistical methods. In this work, we propose a novel conditional variational autoencoder-based method called DySurv which uses a combination of static and time-series measurements from patient electronic health records in estimating risk of death dynamically in the ICU. DySurv has been tested on standard benchmarks where it outperforms most existing methods including other deep learning methods and we evaluate it on a real-world patient database from MIMIC-IV. The predictive capacity of DySurv is consistent and the survival estimates remain disentangled across different datasets supporting the idea that dynamic deep learning models based on conditional variational inference in multi-task cases can be robust models for survival analysis.
Dose-aware Diffusion Model for 3D Ultra Low-dose PET Imaging
Nov 07, 2023As PET imaging is accompanied by substantial radiation exposure and cancer risk, reducing radiation dose in PET scans is an important topic. Recently, diffusion models have emerged as the new state-of-the-art generative model to generate high-quality samples and have demonstrated strong potential for various tasks in medical imaging. However, it is difficult to extend diffusion models for 3D image reconstructions due to the memory burden. Directly stacking 2D slices together to create 3D image volumes would results in severe inconsistencies between slices. Previous works tried to either applying a penalty term along the z-axis to remove inconsistencies or reconstructing the 3D image volumes with 2 pre-trained perpendicular 2D diffusion models. Nonetheless, these previous methods failed to produce satisfactory results in challenging cases for PET image denoising. In addition to administered dose, the noise-levels in PET images are affected by several other factors in clinical settings, such as scan time, patient size, and weight, etc. Therefore, a method to simultaneously denoise PET images with different noise-levels is needed. Here, we proposed a dose-aware diffusion model for 3D low-dose PET imaging (DDPET) to address these challenges. The proposed DDPET method was tested on 295 patients from three different medical institutions globally with different low-dose levels. These patient data were acquired on three different commercial PET scanners, including Siemens Vision Quadra, Siemens mCT, and United Imaging Healthcare uExplorere. The proposed method demonstrated superior performance over previously proposed diffusion models for 3D imaging problems as well as models proposed for noise-aware medical image denoising. Code is available at: xxx.
Blendshapes GHUM: Real-time Monocular Facial Blendshape Prediction
Sep 11, 2023
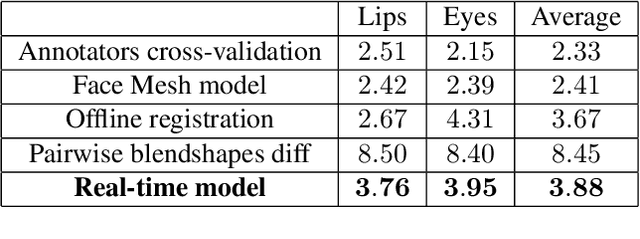
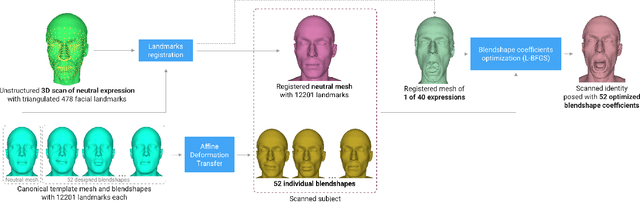
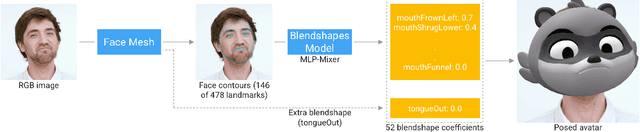
We present Blendshapes GHUM, an on-device ML pipeline that predicts 52 facial blendshape coefficients at 30+ FPS on modern mobile phones, from a single monocular RGB image and enables facial motion capture applications like virtual avatars. Our main contributions are: i) an annotation-free offline method for obtaining blendshape coefficients from real-world human scans, ii) a lightweight real-time model that predicts blendshape coefficients based on facial landmarks.