 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improved Lossless Coding for Storage and Transmission of Multichannel Immersive Audio
Oct 27, 2023
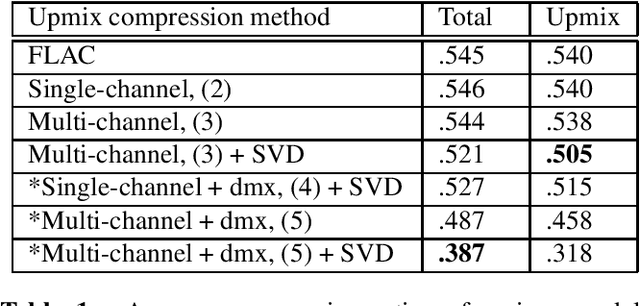
In this paper, techniques for improving multichannel lossless coding are examined. A method is proposed for the simultaneous coding of two or more different renderings (mixes) of the same content. The signal model uses both past samples of the upmix, and the current time samples of downmix samples to predict the upmix. Model parameters are optimized via a general linear solver, and the prediction residual is Rice coded. Additionally, the use of an SVD projection prior to residual coding is proposed. A comparison is made against various baselines, including FLAC. The proposed methods show improved compression ratios for the storage and transmission of immersive audio.
Time-Parameterized Convolutional Neural Networks for Irregularly Sampled Time Series
Aug 06, 2023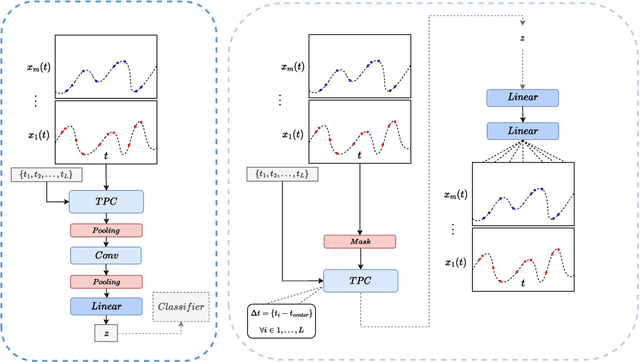
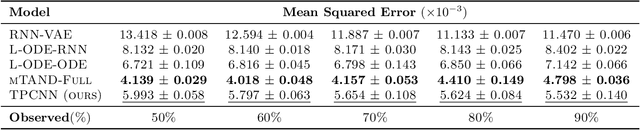
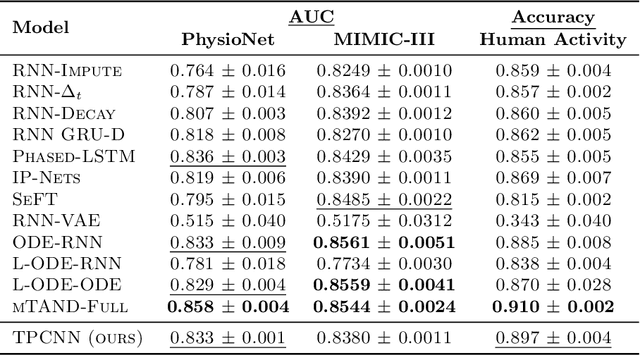
Irregularly sampled multivariate time series are ubiquitous in several application domains, leading to sparse, not fully-observed and non-aligned observations across different variables. Standard sequential neural network architectures, such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs), consider regular spacing between observation times, posing significant challenges to irregular time series modeling. While most of the proposed architectures incorporate RNN variants to handle irregular time intervals, convolutional neural networks have not been adequately studied in the irregular sampling setting. In this paper, we parameterize convolutional layers by employing time-explicitly initialized kernels. Such general functions of time enhance the learning process of continuous-time hidden dynamics and can be efficiently incorporated into convolutional kernel weights. We, thus, propose the time-parameterized convolutional neural network (TPCNN), which shares similar properties with vanilla convolutions but is carefully designed for irregularly sampled time series. We evaluate TPCNN on both interpolation and classification tasks involving real-world irregularly sampled multivariate time series datasets. Our experimental results indicate the competitive performance of the proposed TPCNN model which is also significantly more efficient than other state-of-the-art methods. At the same time, the proposed architecture allows the interpretability of the input series by leveraging the combination of learnable time functions that improve the network performance in subsequent tasks and expedite the inaugural application of convolutions in this field.
sasdim: self-adaptive noise scaling diffusion model for spatial time series imputation
Sep 05, 2023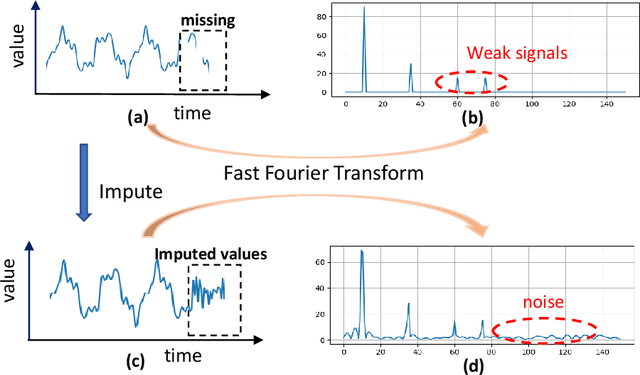
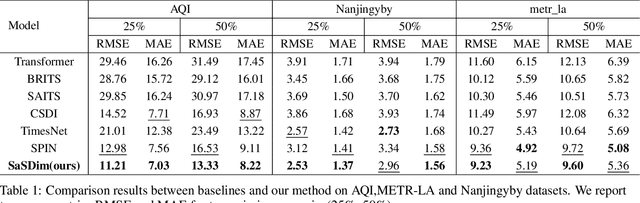
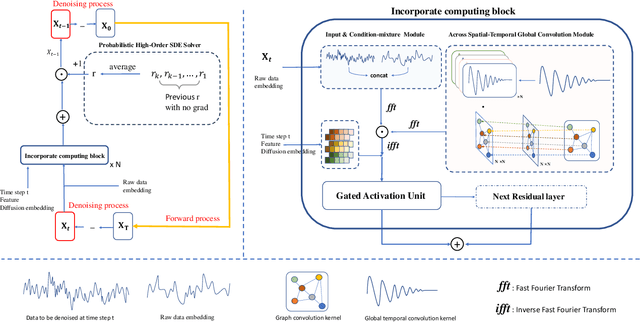
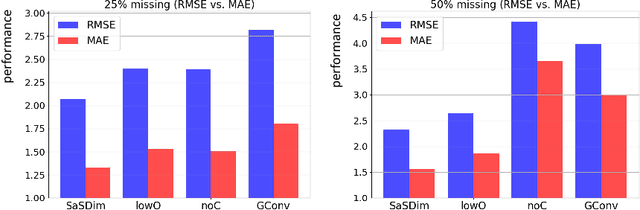
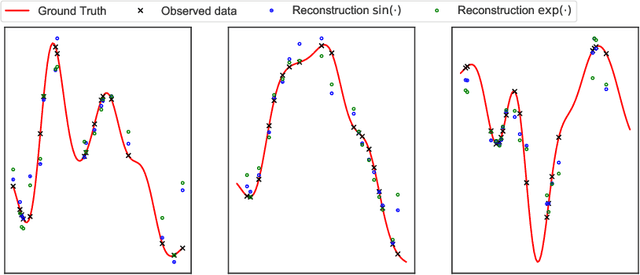
Spatial time series imputation is critically important to many real applications such as intelligent transportation and air quality monitoring. Although recent transformer and diffusion model based approaches have achieved significant performance gains compared with conventional statistic based methods, spatial time series imputation still remains as a challenging issue due to the complex spatio-temporal dependencies and the noise uncertainty of the spatial time series data. Especially, recent diffusion process based models may introduce random noise to the imputations, and thus cause negative impact on the model performance. To this end, we propose a self-adaptive noise scaling diffusion model named SaSDim to more effectively perform spatial time series imputation. Specially, we propose a new loss function that can scale the noise to the similar intensity, and propose the across spatial-temporal global convolution module to more effectively capture the dynamic spatial-temporal dependencies. Extensive experiments conducted on three real world datasets verify the effectiveness of SaSDim by comparison with current state-of-the-art baselines.
CrisisMatch: Semi-Supervised Few-Shot Learning for Fine-Grained Disaster Tweet Classification
Oct 23, 2023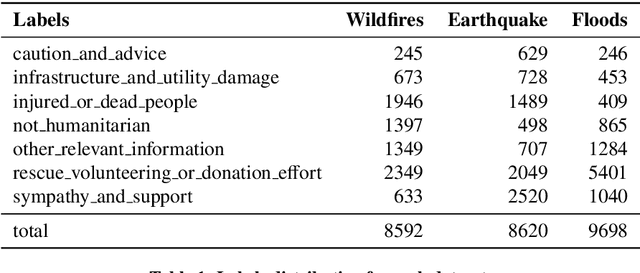
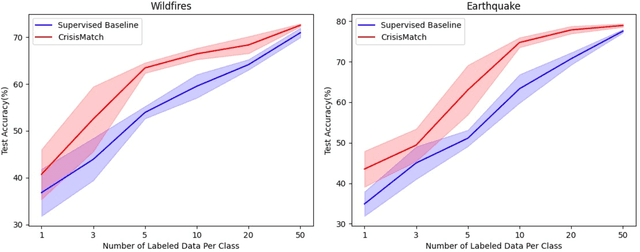
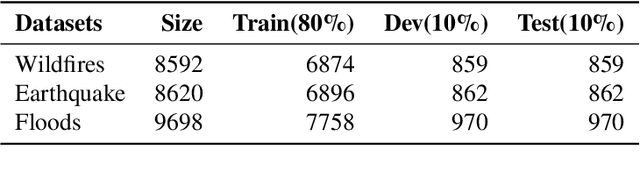
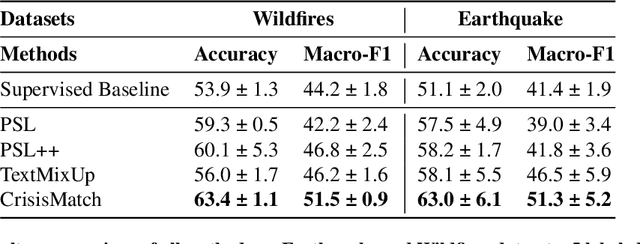
The shared real-time information about natural disasters on social media platforms like Twitter and Facebook plays a critical role in informing volunteers, emergency managers, and response organizations. However, supervised learning models for monitoring disaster events require large amounts of annotated data, making them unrealistic for real-time use in disaster events. To address this challenge, we present a fine-grained disaster tweet classification model under the semi-supervised, few-shot learning setting where only a small number of annotated data is required. Our model, CrisisMatch, effectively classifies tweets into fine-grained classes of interest using few labeled data and large amounts of unlabeled data, mimicking the early stage of a disaster. Through integrating effective semi-supervised learning ideas and incorporating TextMixUp, CrisisMatch achieves performance improvement on two disaster datasets of 11.2\% on average. Further analyses are also provided for the influence of the number of labeled data and out-of-domain results.
A Hybrid GNN approach for predicting node data for 3D meshes
Oct 23, 2023Metal forging is used to manufacture dies. We require the best set of input parameters for the process to be efficient. Currently, we predict the best parameters using the finite element method by generating simulations for the different initial conditions, which is a time-consuming process. In this paper, introduce a hybrid approach that helps in processing and generating new data simulations using a surrogate graph neural network model based on graph convolutions, having a cheaper time cost. We also introduce a hybrid approach that helps in processing and generating new data simulations using the model. Given a dataset representing meshes, our focus is on the conversion of the available information into a graph or point cloud structure. This new representation enables deep learning. The predicted result is similar, with a low error when compared to that produced using the finite element method. The new models have outperformed existing PointNet and simple graph neural network models when applied to produce the simulations.
ADMM Training Algorithms for Residual Networks: Convergence, Complexity and Parallel Training
Oct 23, 2023We design a series of serial and parallel proximal point (gradient) ADMMs for the fully connected residual networks (FCResNets) training problem by introducing auxiliary variables. Convergence of the proximal point version is proven based on a Kurdyka-Lojasiewicz (KL) property analysis framework, and we can ensure a locally R-linear or sublinear convergence rate depending on the different ranges of the Kurdyka-Lojasiewicz (KL) exponent, in which a necessary auxiliary function is constructed to realize our goal. Moreover, the advantages of the parallel implementation in terms of lower time complexity and less (per-node) memory consumption are analyzed theoretically. To the best of our knowledge, this is the first work analyzing the convergence, convergence rate, time complexity and (per-node) runtime memory requirement of the ADMM applied in the FCResNets training problem theoretically. Experiments are reported to show the high speed, better performance, robustness and potential in the deep network training tasks. Finally, we present the advantage and potential of our parallel training in large-scale problems.
Neural Network with Local Converging Input (NNLCI) for Supersonic Flow Problems with Unstructured Grids
Oct 23, 2023In recent years, surrogate models based on deep neural networks (DNN) have been widely used to solve partial differential equations, which were traditionally handled by means of numerical simulations. This kind of surrogate models, however, focuses on global interpolation of the training dataset, and thus requires a large network structure. The process is both time consuming and computationally costly, thereby restricting their use for high-fidelity prediction of complex physical problems. In the present study, we develop a neural network with local converging input (NNLCI) for high-fidelity prediction using unstructured data. The framework utilizes the local domain of dependence with converging coarse solutions as input, which greatly reduces computational resource and training time. As a validation case, the NNLCI method is applied to study inviscid supersonic flows in channels with bumps. Different bump geometries and locations are considered to benchmark the effectiveness and versability of the proposed approach. Detailed flow structures, including shock-wave interactions, are examined systematically.
Collaborative Evaluation: Exploring the Synergy of Large Language Models and Humans for Open-ended Generation Evaluation
Oct 30, 2023Humans are widely involved in the evaluation of open-ended natural language generation tasks (NLG) that demand creativity, as automatic metrics often exhibit weak correlations with human judgments. Large language models (LLMs) recently have emerged as a scalable and cost-effective alternative to human evaluations. However, both humans and LLMs have limitations, i.e., inherent subjectivity and unreliable judgments, particularly for open-ended tasks that require adaptable metrics tailored to diverse task requirements. To explore the synergy between humans and LLM-based evaluators and address the challenges of existing inconsistent evaluation criteria in open-ended NLG tasks, we propose a Collaborative Evaluation pipeline CoEval, involving the design of a checklist of task-specific criteria and the detailed evaluation of texts, in which LLM generates initial ideation, and then humans engage in scrutiny. We conducted a series of experiments to investigate the mutual effects between LLMs and humans in CoEval. Results show that, by utilizing LLMs, CoEval effectively evaluates lengthy texts, saving significant time and reducing human evaluation outliers. Human scrutiny still plays a role, revising around 20% of LLM evaluation scores for ultimate reliability.
Large Trajectory Models are Scalable Motion Predictors and Planners
Oct 30, 2023Motion prediction and planning are vital tasks in autonomous driving, and recent efforts have shifted to machine learning-based approaches. The challenges include understanding diverse road topologies, reasoning traffic dynamics over a long time horizon, interpreting heterogeneous behaviors, and generating policies in a large continuous state space. Inspired by the success of large language models in addressing similar complexities through model scaling, we introduce a scalable trajectory model called State Transformer (STR). STR reformulates the motion prediction and motion planning problems by arranging observations, states, and actions into one unified sequence modeling task. With a simple model design, STR consistently outperforms baseline approaches in both problems. Remarkably, experimental results reveal that large trajectory models (LTMs), such as STR, adhere to the scaling laws by presenting outstanding adaptability and learning efficiency. Qualitative results further demonstrate that LTMs are capable of making plausible predictions in scenarios that diverge significantly from the training data distribution. LTMs also learn to make complex reasonings for long-term planning, without explicit loss designs or costly high-level annotations.
Flow-based Distributionally Robust Optimization
Oct 30, 2023We present a computationally efficient framework, called \texttt{FlowDRO}, for solving flow-based distributionally robust optimization (DRO) problems with Wasserstein uncertainty sets, when requiring the worst-case distribution (also called the Least Favorable Distribution, LFD) to be continuous so that the algorithm can be scalable to problems with larger sample sizes and achieve better generalization capability for the induced robust algorithms. To tackle the computationally challenging infinitely dimensional optimization problem, we leverage flow-based models, continuous-time invertible transport maps between the data distribution and the target distribution, and develop a Wasserstein proximal gradient flow type of algorithm. In practice, we parameterize the transport maps by a sequence of neural networks progressively trained in blocks by gradient descent. Our computational framework is general, can handle high-dimensional data with large sample sizes, and can be useful for various applications. We demonstrate its usage in adversarial learning, distributionally robust hypothesis testing, and a new mechanism for data-driven distribution perturbation differential privacy, where the proposed method gives strong empirical performance on real high-dimensional data.