 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improved Topological Preservation in 3D Axon Segmentation and Centerline Detection using Geometric Assessment-driven Topological Smoothing (GATS)
Nov 07, 2023
Automated axon tracing via fully supervised learning requires large amounts of 3D brain imagery, which is time consuming and laborious to obtain. It also requires expertise. Thus, there is a need for more efficient segmentation and centerline detection techniques to use in conjunction with automated annotation tools. Topology-preserving methods ensure that segmented components maintain geometric connectivity, which is especially meaningful for applications where volumetric data is used, and these methods often make use of morphological thinning algorithms as the thinned outputs can be useful for both segmentation and centerline detection of curvilinear structures. Current morphological thinning approaches used in conjunction with topology-preserving methods are prone to over-thinning and require manual configuration of hyperparameters. We propose an automated approach for morphological smoothing using geometric assessment of the radius of tubular structures in brain microscopy volumes, and apply average pooling to prevent over-thinning. We use this approach to formulate a loss function, which we call Geo-metric Assessment-driven Topological Smoothing loss, or GATS. Our approach increased segmentation and center-line detection evaluation metrics by 2%-5% across multiple datasets, and improved the Betti error rates by 9%. Our ablation study showed that geometric assessment of tubular structures achieved higher segmentation and centerline detection scores, and using average pooling for morphological smoothing in place of thinning algorithms reduced the Betti errors. We observed increased topological preservation during automated annotation of 3D axons volumes from models trained with GATS.
Classification of Various Types of Damages in Honeycomb Composite Sandwich Structures using Guided Wave Structural Health Monitoring
Nov 07, 2023Classification of damages in honeycomb composite sandwich structure (HCSS) is important to decide remedial actions. However, previous studies have only detected damages using deviations of monitoring signal from healthy (baseline) using a guided wave (GW) based structural health monitoring system. Classification between various types of damages has not been reported for challenging cases. We show that using careful feature engineering and machine learning it is possible to classify between various types of damages such as core crush (CC), high density core (HDC), lost film adhesive (LFA) and teflon release film (TRF). We believe that we are the first to report numerical models for four types of damages in HCSS, which is followed up with experimental validation. We found that two out of four damages affect the GW signal in a particularly similar manner. We extracted and evaluated multiple features from time as well as frequency domains, and also experimented with features relative to as baseline as well as those that were baseline-free. Using Pearson's correlation coefficient based filtering, redundant features were eliminated. Finally, using an optimal feature set determined using feature elimination, high accuracy was achieved with a random forest classifier on held-out signals. For evaluating performance of the proposed method for different damage sizes, we used simulated data obtained from extensive parametric studies and got an accuracy of 77.89%. Interpretability studies to determine importance of various features showed that features computed using the baseline signal prove more effective as compared to baseline-free features.
Tik-to-Tok: Translating Language Models One Token at a Time: An Embedding Initialization Strategy for Efficient Language Adaptation
Oct 05, 2023Training monolingual language models for low and mid-resource languages is made challenging by limited and often inadequate pretraining data. In this study, we propose a novel model conversion strategy to address this issue, adapting high-resources monolingual language models to a new target language. By generalizing over a word translation dictionary encompassing both the source and target languages, we map tokens from the target tokenizer to semantically similar tokens from the source language tokenizer. This one-to-many token mapping improves tremendously the initialization of the embedding table for the target language. We conduct experiments to convert high-resource models to mid- and low-resource languages, namely Dutch and Frisian. These converted models achieve a new state-of-the-art performance on these languages across all sorts of downstream tasks. By reducing significantly the amount of data and time required for training state-of-the-art models, our novel model conversion strategy has the potential to benefit many languages worldwide.
VIBE: Topic-Driven Temporal Adaptation for Twitter Classification
Nov 04, 2023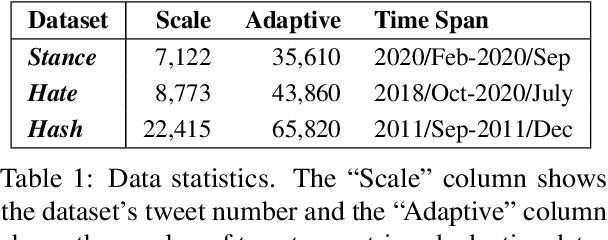
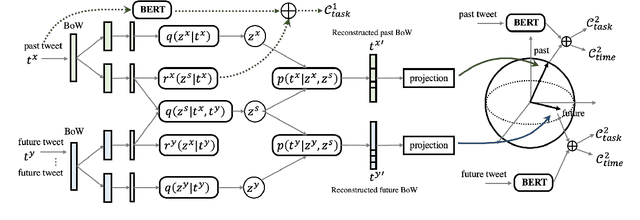
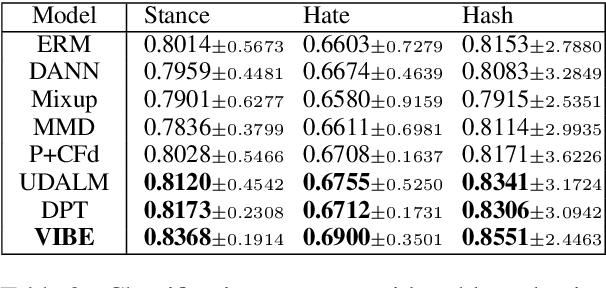
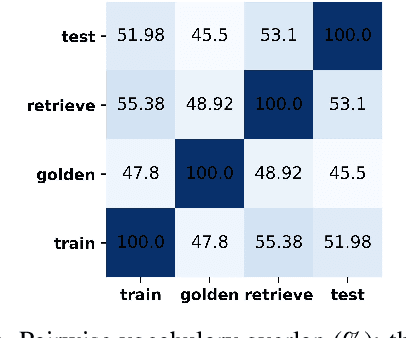
Language features are evolving in real-world social media, resulting in the deteriorating performance of text classification in dynamics. To address this challenge, we study temporal adaptation, where models trained on past data are tested in the future. Most prior work focused on continued pretraining or knowledge updating, which may compromise their performance on noisy social media data. To tackle this issue, we reflect feature change via modeling latent topic evolution and propose a novel model, VIBE: Variational Information Bottleneck for Evolutions. Concretely, we first employ two Information Bottleneck (IB) regularizers to distinguish past and future topics. Then, the distinguished topics work as adaptive features via multi-task training with timestamp and class label prediction. In adaptive learning, VIBE utilizes retrieved unlabeled data from online streams created posterior to training data time. Substantial Twitter experiments on three classification tasks show that our model, with only 3% of data, significantly outperforms previous state-of-the-art continued-pretraining methods.
* accepted by EMNLP 2023
Decoy Effect in Search Interaction: A Pilot Study
Nov 04, 2023In recent years, the influence of cognitive effects and biases on users' thinking, behaving, and decision-making has garnered increasing attention in the field of interactive information retrieval. The decoy effect, one of the main empirically confirmed cognitive biases, refers to the shift in preference between two choices when a third option (the decoy) which is inferior to one of the initial choices is introduced. However, it is not clear how the decoy effect influences user interactions with and evaluations on Search Engine Result Pages (SERPs). To bridge this gap, our study seeks to understand how the decoy effect at the document level influences users' interaction behaviors on SERPs, such as clicks, dwell time, and usefulness perceptions. We conducted experiments on two publicly available user behavior datasets and the findings reveal that, compared to cases where no decoy is present, the probability of a document being clicked could be improved and its usefulness score could be higher, should there be a decoy associated with the document.
Add and Thin: Diffusion for Temporal Point Processes
Nov 02, 2023Autoregressive neural networks within the temporal point process (TPP) framework have become the standard for modeling continuous-time event data. Even though these models can expressively capture event sequences in a one-step-ahead fashion, they are inherently limited for long-term forecasting applications due to the accumulation of errors caused by their sequential nature. To overcome these limitations, we derive ADD-THIN, a principled probabilistic denoising diffusion model for TPPs that operates on entire event sequences. Unlike existing diffusion approaches, ADD-THIN naturally handles data with discrete and continuous components. In experiments on synthetic and real-world datasets, our model matches the state-of-the-art TPP models in density estimation and strongly outperforms them in forecasting.
H-NeXt: The next step towards roto-translation invariant networks
Nov 02, 2023The widespread popularity of equivariant networks underscores the significance of parameter efficient models and effective use of training data. At a time when robustness to unseen deformations is becoming increasingly important, we present H-NeXt, which bridges the gap between equivariance and invariance. H-NeXt is a parameter-efficient roto-translation invariant network that is trained without a single augmented image in the training set. Our network comprises three components: an equivariant backbone for learning roto-translation independent features, an invariant pooling layer for discarding roto-translation information, and a classification layer. H-NeXt outperforms the state of the art in classification on unaugmented training sets and augmented test sets of MNIST and CIFAR-10.
PolyMerge: A Novel Technique aimed at Dynamic HD Map Updates Leveraging Polylines
Oct 31, 2023Currently, High-Definition (HD) maps are a prerequisite for the stable operation of autonomous vehicles. Such maps contain information about all static road objects for the vehicle to consider during navigation, such as road edges, road lanes, crosswalks, and etc. To generate such an HD map, current approaches need to process pre-recorded environment data obtained from onboard sensors. However, recording such a dataset often requires a lot of time and effort. In addition, every time actual road environments are changed, a new dataset should be recorded to generate a relevant HD map. This paper addresses a novel approach that allows to continuously generate or update the HD map using onboard sensor data. When there is no need to pre-record the dataset, updating the HD map can be run in parallel with the main autonomous vehicle navigation pipeline. The proposed approach utilizes the VectorMapNet framework to generate vector road object instances from a sensor data scan. The PolyMerge technique is aimed to merge new instances into previous ones, mitigating detection errors and, therefore, generating or updating the HD map. The performance of the algorithm was confirmed by comparison with ground truth on the NuScenes dataset. Experimental results showed that the mean error for different levels of environment complexity was comparable to the VectorMapNet single instance error.
Active Neural Topological Mapping for Multi-Agent Exploration
Nov 01, 2023This paper investigates the multi-agent cooperative exploration problem, which requires multiple agents to explore an unseen environment via sensory signals in a limited time. A popular approach to exploration tasks is to combine active mapping with planning. Metric maps capture the details of the spatial representation, but are with high communication traffic and may vary significantly between scenarios, resulting in inferior generalization. Topological maps are a promising alternative as they consist only of nodes and edges with abstract but essential information and are less influenced by the scene structures. However, most existing topology-based exploration tasks utilize classical methods for planning, which are time-consuming and sub-optimal due to their handcrafted design. Deep reinforcement learning (DRL) has shown great potential for learning (near) optimal policies through fast end-to-end inference. In this paper, we propose Multi-Agent Neural Topological Mapping (MANTM) to improve exploration efficiency and generalization for multi-agent exploration tasks. MANTM mainly comprises a Topological Mapper and a novel RL-based Hierarchical Topological Planner (HTP). The Topological Mapper employs a visual encoder and distance-based heuristics to construct a graph containing main nodes and their corresponding ghost nodes. The HTP leverages graph neural networks to capture correlations between agents and graph nodes in a coarse-to-fine manner for effective global goal selection. Extensive experiments conducted in a physically-realistic simulator, Habitat, demonstrate that MANTM reduces the steps by at least 26.40% over planning-based baselines and by at least 7.63% over RL-based competitors in unseen scenarios.
Early Churn Prediction from Large Scale User-Product Interaction Time Series
Sep 25, 2023User churn, characterized by customers ending their relationship with a business, has profound economic consequences across various Business-to-Customer scenarios. For numerous system-to-user actions, such as promotional discounts and retention campaigns, predicting potential churners stands as a primary objective. In volatile sectors like fantasy sports, unpredictable factors such as international sports events can influence even regular spending habits. Consequently, while transaction history and user-product interaction are valuable in predicting churn, they demand deep domain knowledge and intricate feature engineering. Additionally, feature development for churn prediction systems can be resource-intensive, particularly in production settings serving 200m+ users, where inference pipelines largely focus on feature engineering. This paper conducts an exhaustive study on predicting user churn using historical data. We aim to create a model forecasting customer churn likelihood, facilitating businesses in comprehending attrition trends and formulating effective retention plans. Our approach treats churn prediction as multivariate time series classification, demonstrating that combining user activity and deep neural networks yields remarkable results for churn prediction in complex business-to-customer contexts.