 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Analyzing the Impact of Companies on AI Research Based on Publications
Oct 31, 2023
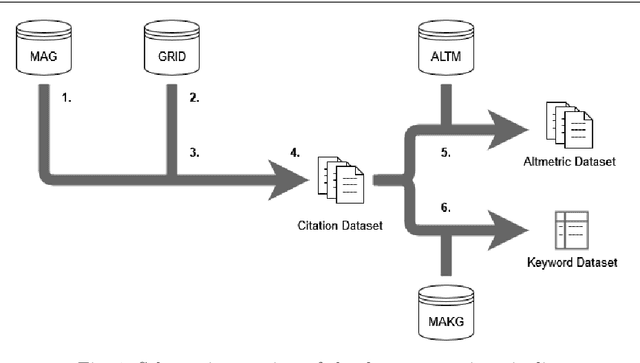

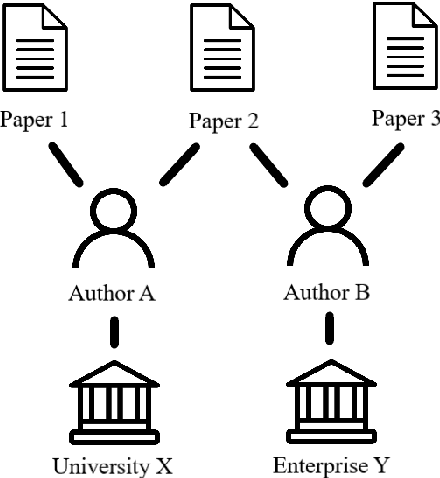

Artificial Intelligence (AI) is one of the most momentous technologies of our time. Thus, it is of major importance to know which stakeholders influence AI research. Besides researchers at universities and colleges, researchers in companies have hardly been considered in this context. In this article, we consider how the influence of companies on AI research can be made measurable on the basis of scientific publishing activities. We compare academic- and company-authored AI publications published in the last decade and use scientometric data from multiple scholarly databases to look for differences across these groups and to disclose the top contributing organizations. While the vast majority of publications is still produced by academia, we find that the citation count an individual publication receives is significantly higher when it is (co-)authored by a company. Furthermore, using a variety of altmetric indicators, we notice that publications with company participation receive considerably more attention online. Finally, we place our analysis results in a broader context and present targeted recommendations to safeguard a harmonious balance between academia and industry in the realm of AI research.
Object-centric Video Representation for Long-term Action Anticipation
Oct 31, 2023This paper focuses on building object-centric representations for long-term action anticipation in videos. Our key motivation is that objects provide important cues to recognize and predict human-object interactions, especially when the predictions are longer term, as an observed "background" object could be used by the human actor in the future. We observe that existing object-based video recognition frameworks either assume the existence of in-domain supervised object detectors or follow a fully weakly-supervised pipeline to infer object locations from action labels. We propose to build object-centric video representations by leveraging visual-language pretrained models. This is achieved by "object prompts", an approach to extract task-specific object-centric representations from general-purpose pretrained models without finetuning. To recognize and predict human-object interactions, we use a Transformer-based neural architecture which allows the "retrieval" of relevant objects for action anticipation at various time scales. We conduct extensive evaluations on the Ego4D, 50Salads, and EGTEA Gaze+ benchmarks. Both quantitative and qualitative results confirm the effectiveness of our proposed method.
Machine learning refinement of in situ images acquired by low electron dose LC-TEM
Oct 31, 2023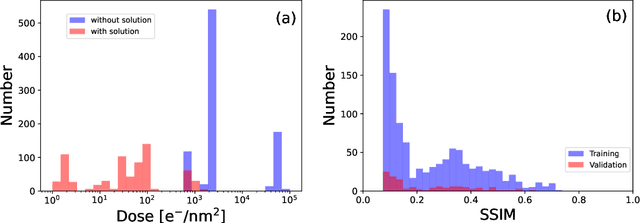
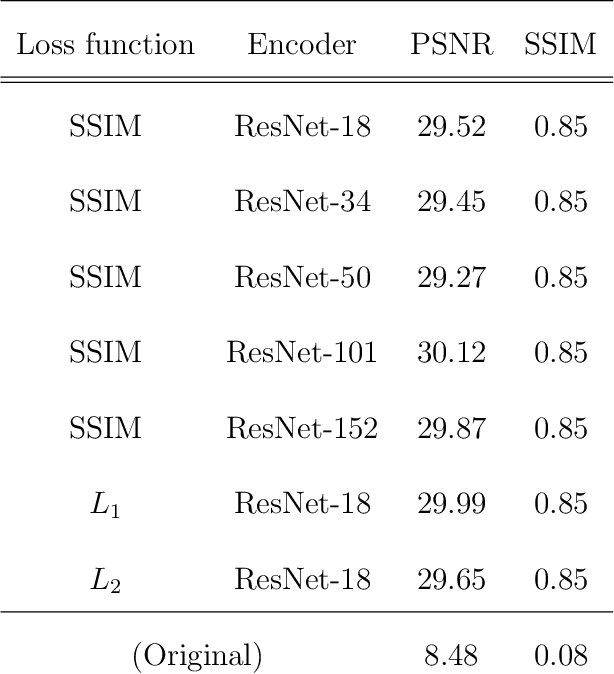
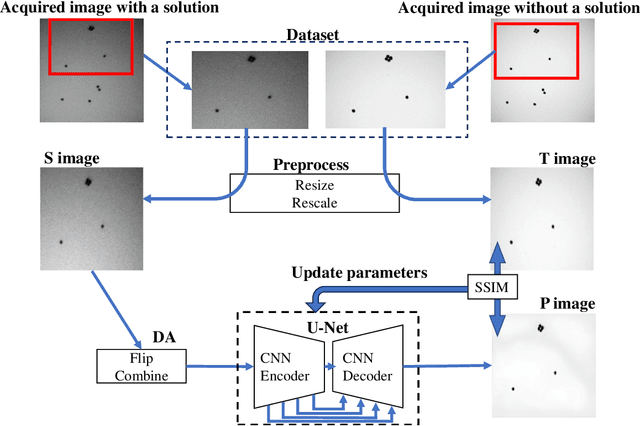
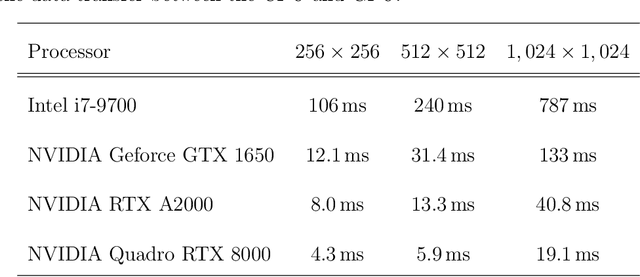
We study a machine learning (ML) technique for refining images acquired during in situ observation using liquid-cell transmission electron microscopy (LC-TEM). Our model is constructed using a U-Net architecture and a ResNet encoder. For training our ML model, we prepared an original image dataset that contained pairs of images of samples acquired with and without a solution present. The former images were used as noisy images and the latter images were used as corresponding ground truth images. The number of pairs of image sets was $1,204$ and the image sets included images acquired at several different magnifications and electron doses. The trained model converted a noisy image into a clear image. The time necessary for the conversion was on the order of 10ms, and we applied the model to in situ observations using the software Gatan DigitalMicrograph (DM). Even if a nanoparticle was not visible in a view window in the DM software because of the low electron dose, it was visible in a successive refined image generated by our ML model.
Multi-task learning of convex combinations of forecasting models
Oct 31, 2023Forecast combination involves using multiple forecasts to create a single, more accurate prediction. Recently, feature-based forecasting has been employed to either select the most appropriate forecasting models or to learn the weights of their convex combination. In this paper, we present a multi-task learning methodology that simultaneously addresses both problems. This approach is implemented through a deep neural network with two branches: the regression branch, which learns the weights of various forecasting methods by minimizing the error of combined forecasts, and the classification branch, which selects forecasting methods with an emphasis on their diversity. To generate training labels for the classification task, we introduce an optimization-driven approach that identifies the most appropriate methods for a given time series. The proposed approach elicits the essential role of diversity in feature-based forecasting and highlights the interplay between model combination and model selection when learning forecasting ensembles. Experimental results on a large set of series from the M4 competition dataset show that our proposal enhances point forecast accuracy compared to state-of-the-art methods.
Compact Binary Systems Waveform Generation with Generative Pre-trained Transformer
Oct 31, 2023Space-based gravitational wave detection is one of the most anticipated gravitational wave (GW) detection projects in the next decade, which will detect abundant compact binary systems. However, the precise prediction of space GW waveforms remains unexplored. To solve the data processing difficulty in the increasing waveform complexity caused by detectors' response and second-generation time-delay interferometry (TDI 2.0), an interpretable pre-trained large model named CBS-GPT (Compact Binary Systems Waveform Generation with Generative Pre-trained Transformer) is proposed. For compact binary system waveforms, three models were trained to predict the waveforms of massive black hole binary (MBHB), extreme mass-ratio inspirals (EMRIs), and galactic binary (GB), achieving prediction accuracies of 98%, 91%, and 99%, respectively. The CBS-GPT model exhibits notable interpretability, with its hidden parameters effectively capturing the intricate information of waveforms, even with complex instrument response and a wide parameter range. Our research demonstrates the potential of large pre-trained models in gravitational wave data processing, opening up new opportunities for future tasks such as gap completion, GW signal detection, and signal noise reduction.
View Classification and Object Detection in Cardiac Ultrasound to Localize Valves via Deep Learning
Oct 31, 2023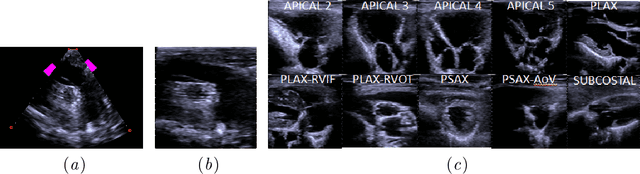

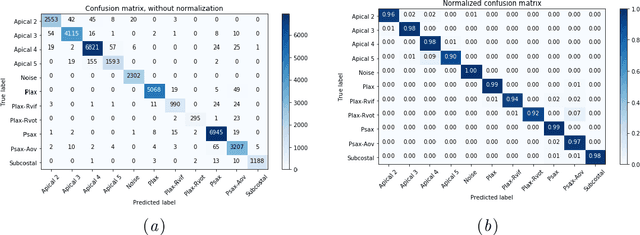
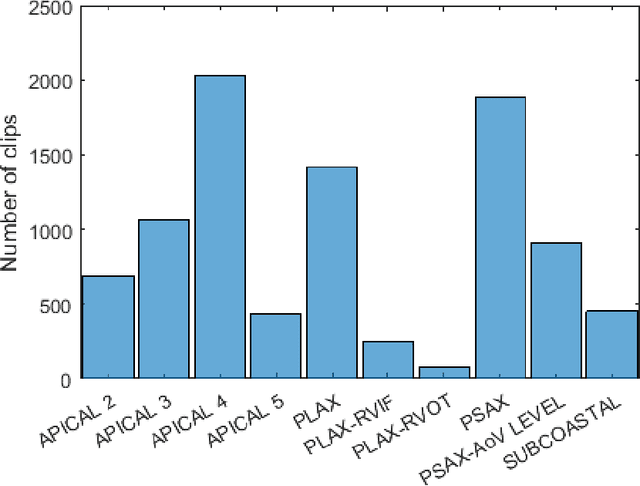
Echocardiography provides an important tool for clinicians to observe the function of the heart in real time, at low cost, and without harmful radiation. Automated localization and classification of heart valves enables automatic extraction of quantities associated with heart mechanical function and related blood flow measurements. We propose a machine learning pipeline that uses deep neural networks for separate classification and localization steps. As the first step in the pipeline, we apply view classification to echocardiograms with ten unique anatomic views of the heart. In the second step, we apply deep learning-based object detection to both localize and identify the valves. Image segmentation based object detection in echocardiography has been shown in many earlier studies but, to the best of our knowledge, this is the first study that predicts the bounding boxes around the valves along with classification from 2D ultrasound images with the help of deep neural networks. Our object detection experiments applied to the Apical views suggest that it is possible to localize and identify multiple valves precisely.
Global Transformer Architecture for Indoor Room Temperature Forecasting
Oct 31, 2023A thorough regulation of building energy systems translates in relevant energy savings and in a better comfort for the occupants. Algorithms to predict the thermal state of a building on a certain time horizon with a good confidence are essential for the implementation of effective control systems. This work presents a global Transformer architecture for indoor temperature forecasting in multi-room buildings, aiming at optimizing energy consumption and reducing greenhouse gas emissions associated with HVAC systems. Recent advancements in deep learning have enabled the development of more sophisticated forecasting models compared to traditional feedback control systems. The proposed global Transformer architecture can be trained on the entire dataset encompassing all rooms, eliminating the need for multiple room-specific models, significantly improving predictive performance, and simplifying deployment and maintenance. Notably, this study is the first to apply a Transformer architecture for indoor temperature forecasting in multi-room buildings. The proposed approach provides a novel solution to enhance the accuracy and efficiency of temperature forecasting, serving as a valuable tool to optimize energy consumption and decrease greenhouse gas emissions in the building sector.
DEPN: Detecting and Editing Privacy Neurons in Pretrained Language Models
Oct 31, 2023Large language models pretrained on a huge amount of data capture rich knowledge and information in the training data. The ability of data memorization and regurgitation in pretrained language models, revealed in previous studies, brings the risk of data leakage. In order to effectively reduce these risks, we propose a framework DEPN to Detect and Edit Privacy Neurons in pretrained language models, partially inspired by knowledge neurons and model editing. In DEPN, we introduce a novel method, termed as privacy neuron detector, to locate neurons associated with private information, and then edit these detected privacy neurons by setting their activations to zero. Furthermore, we propose a privacy neuron aggregator dememorize private information in a batch processing manner. Experimental results show that our method can significantly and efficiently reduce the exposure of private data leakage without deteriorating the performance of the model. Additionally, we empirically demonstrate the relationship between model memorization and privacy neurons, from multiple perspectives, including model size, training time, prompts, privacy neuron distribution, illustrating the robustness of our approach.
TSGBench: Time Series Generation Benchmark
Sep 07, 2023Synthetic Time Series Generation (TSG) is crucial in a range of applications, including data augmentation, anomaly detection, and privacy preservation. Although significant strides have been made in this field, existing methods exhibit three key limitations: (1) They often benchmark against similar model types, constraining a holistic view of performance capabilities. (2) The use of specialized synthetic and private datasets introduces biases and hampers generalizability. (3) Ambiguous evaluation measures, often tied to custom networks or downstream tasks, hinder consistent and fair comparison. To overcome these limitations, we introduce \textsf{TSGBench}, the inaugural TSG Benchmark, designed for a unified and comprehensive assessment of TSG methods. It comprises three modules: (1) a curated collection of publicly available, real-world datasets tailored for TSG, together with a standardized preprocessing pipeline; (2) a comprehensive evaluation measures suite including vanilla measures, new distance-based assessments, and visualization tools; (3) a pioneering generalization test rooted in Domain Adaptation (DA), compatible with all methods. We have conducted extensive experiments across ten real-world datasets from diverse domains, utilizing ten advanced TSG methods and twelve evaluation measures, all gauged through \textsf{TSGBench}. The results highlight its remarkable efficacy and consistency. More importantly, \textsf{TSGBench} delivers a statistical breakdown of method rankings, illuminating performance variations across different datasets and measures, and offering nuanced insights into the effectiveness of each method.
Calibrate and Boost Logical Expressiveness of GNN Over Multi-Relational and Temporal Graphs
Nov 03, 2023As a powerful framework for graph representation learning, Graph Neural Networks (GNNs) have garnered significant attention in recent years. However, to the best of our knowledge, there has been no formal analysis of the logical expressiveness of GNNs as Boolean node classifiers over multi-relational graphs, where each edge carries a specific relation type. In this paper, we investigate $\mathcal{FOC}_2$, a fragment of first-order logic with two variables and counting quantifiers. On the negative side, we demonstrate that the R$^2$-GNN architecture, which extends the local message passing GNN by incorporating global readout, fails to capture $\mathcal{FOC}_2$ classifiers in the general case. Nevertheless, on the positive side, we establish that R$^2$-GNNs models are equivalent to $\mathcal{FOC}_2$ classifiers under certain restricted yet reasonable scenarios. To address the limitations of R$^2$-GNNs regarding expressiveness, we propose a simple graph transformation technique, akin to a preprocessing step, which can be executed in linear time. This transformation enables R$^2$-GNNs to effectively capture any $\mathcal{FOC}_2$ classifiers when applied to the "transformed" input graph. Moreover, we extend our analysis of expressiveness and graph transformation to temporal graphs, exploring several temporal GNN architectures and providing an expressiveness hierarchy for them. To validate our findings, we implement R$^2$-GNNs and the graph transformation technique and conduct empirical tests in node classification tasks against various well-known GNN architectures that support multi-relational or temporal graphs. Our experimental results consistently demonstrate that R$^2$-GNN with the graph transformation outperforms the baseline methods on both synthetic and real-world datasets