 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SMURF-THP: Score Matching-based UnceRtainty quantiFication for Transformer Hawkes Process
Oct 25, 2023
Transformer Hawkes process models have shown to be successful in modeling event sequence data. However, most of the existing training methods rely on maximizing the likelihood of event sequences, which involves calculating some intractable integral. Moreover, the existing methods fail to provide uncertainty quantification for model predictions, e.g., confidence intervals for the predicted event's arrival time. To address these issues, we propose SMURF-THP, a score-based method for learning Transformer Hawkes process and quantifying prediction uncertainty. Specifically, SMURF-THP learns the score function of events' arrival time based on a score-matching objective that avoids the intractable computation. With such a learned score function, we can sample arrival time of events from the predictive distribution. This naturally allows for the quantification of uncertainty by computing confidence intervals over the generated samples. We conduct extensive experiments in both event type prediction and uncertainty quantification of arrival time. In all the experiments, SMURF-THP outperforms existing likelihood-based methods in confidence calibration while exhibiting comparable prediction accuracy.
Can input reconstruction be used to directly estimate uncertainty of a regression U-Net model? -- Application to proton therapy dose prediction for head and neck cancer patients
Oct 30, 2023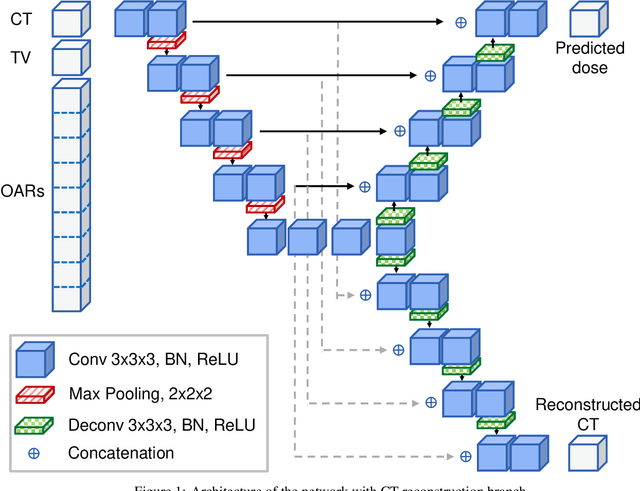
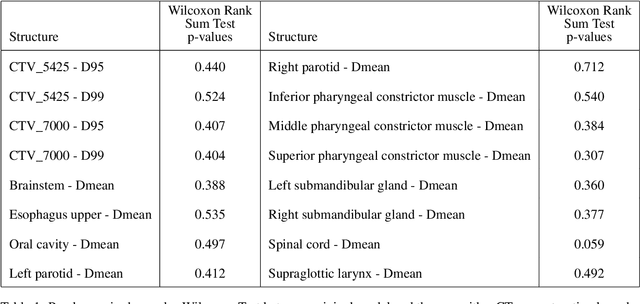

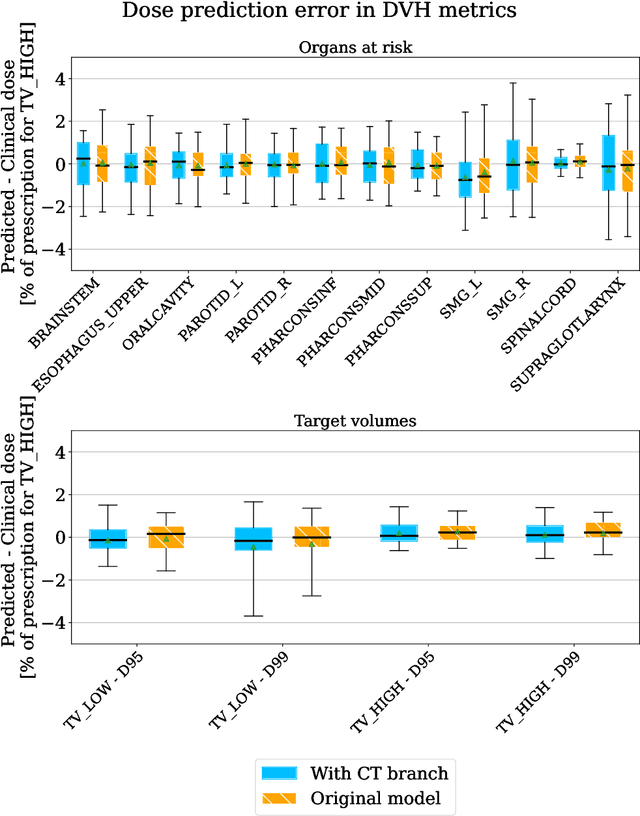
Estimating the uncertainty of deep learning models in a reliable and efficient way has remained an open problem, where many different solutions have been proposed in the literature. Most common methods are based on Bayesian approximations, like Monte Carlo dropout (MCDO) or Deep ensembling (DE), but they have a high inference time (i.e. require multiple inference passes) and might not work for out-of-distribution detection (OOD) data (i.e. similar uncertainty for in-distribution (ID) and OOD). In safety critical environments, like medical applications, accurate and fast uncertainty estimation methods, able to detect OOD data, are crucial, since wrong predictions can jeopardize patients safety. In this study, we present an alternative direct uncertainty estimation method and apply it for a regression U-Net architecture. The method consists in the addition of a branch from the bottleneck which reconstructs the input. The input reconstruction error can be used as a surrogate of the model uncertainty. For the proof-of-concept, our method is applied to proton therapy dose prediction in head and neck cancer patients. Accuracy, time-gain, and OOD detection are analyzed for our method in this particular application and compared with the popular MCDO and DE. The input reconstruction method showed a higher Pearson correlation coefficient with the prediction error (0.620) than DE and MCDO (between 0.447 and 0.612). Moreover, our method allows an easier identification of OOD (Z-score of 34.05). It estimates the uncertainty simultaneously to the regression task, therefore requires less time or computational resources.
Ultra-Efficient On-Device Object Detection on AI-Integrated Smart Glasses with TinyissimoYOLO
Nov 03, 2023Smart glasses are rapidly gaining advanced functionality thanks to cutting-edge computing technologies, accelerated hardware architectures, and tiny AI algorithms. Integrating AI into smart glasses featuring a small form factor and limited battery capacity is still challenging when targeting full-day usage for a satisfactory user experience. This paper illustrates the design and implementation of tiny machine-learning algorithms exploiting novel low-power processors to enable prolonged continuous operation in smart glasses. We explore the energy- and latency-efficient of smart glasses in the case of real-time object detection. To this goal, we designed a smart glasses prototype as a research platform featuring two microcontrollers, including a novel milliwatt-power RISC-V parallel processor with a hardware accelerator for visual AI, and a Bluetooth low-power module for communication. The smart glasses integrate power cycling mechanisms, including image and audio sensing interfaces. Furthermore, we developed a family of novel tiny deep-learning models based on YOLO with sub-million parameters customized for microcontroller-based inference dubbed TinyissimoYOLO v1.3, v5, and v8, aiming at benchmarking object detection with smart glasses for energy and latency. Evaluations on the prototype of the smart glasses demonstrate TinyissimoYOLO's 17ms inference latency and 1.59mJ energy consumption per inference while ensuring acceptable detection accuracy. Further evaluation reveals an end-to-end latency from image capturing to the algorithm's prediction of 56ms or equivalently 18 fps, with a total power consumption of 62.9mW, equivalent to a 9.3 hours of continuous run time on a 154mAh battery. These results outperform MCUNet (TinyNAS+TinyEngine), which runs a simpler task (image classification) at just 7.3 fps per second.
Swarm Performance Indicators: Metrics for Robustness, Fault Tolerance, Scalability and Adaptability
Nov 03, 2023Swarms have distributed control and so are assumed to inherently have superior robustness, scalability and adaptability compared to centralised multi-agent systems. However, these features have generally only been defined qualitatively and there is a lack of quantitative metrics and experimental measures for the claimed parameters. Swarm Performance Indicators are defined here as Key Performance Indicators for swarm features but can be applied to multi-agent systems with centralised control as well. These swarm features are Robustness, Fault Tolerance, Adaptability and Scalability. Swarm Performance Indicators can be used to highlight the benefits of swarms beyond solely considering task-based performance metrics (e.g. time taken)
Regret Analysis of Learning-Based Linear Quadratic Gaussian Control with Additive Exploration
Nov 05, 2023In this paper, we analyze the regret incurred by a computationally efficient exploration strategy, known as naive exploration, for controlling unknown partially observable systems within the Linear Quadratic Gaussian (LQG) framework. We introduce a two-phase control algorithm called LQG-NAIVE, which involves an initial phase of injecting Gaussian input signals to obtain a system model, followed by a second phase of an interplay between naive exploration and control in an episodic fashion. We show that LQG-NAIVE achieves a regret growth rate of $\tilde{\mathcal{O}}(\sqrt{T})$, i.e., $\mathcal{O}(\sqrt{T})$ up to logarithmic factors after $T$ time steps, and we validate its performance through numerical simulations. Additionally, we propose LQG-IF2E, which extends the exploration signal to a `closed-loop' setting by incorporating the Fisher Information Matrix (FIM). We provide compelling numerical evidence of the competitive performance of LQG-IF2E compared to LQG-NAIVE.
Towards Calibrated Robust Fine-Tuning of Vision-Language Models
Nov 06, 2023While fine-tuning unlocks the potential of a pre-trained model for a specific task, it compromises the model's ability to generalize to out-of-distribution (OOD) datasets. To mitigate this, robust fine-tuning aims to ensure performance on OOD datasets as well as on an in-distribution (ID) dataset for which the model is being tuned. However, another criterion for reliable machine learning (ML), confidence calibration, has been overlooked despite its increasing demand for real-world high-stakes ML applications (e.g., autonomous driving and medical diagnosis). For the first time, we raise concerns about the calibration of fine-tuned vision-language models (VLMs) under distribution shift by showing that naive fine-tuning and even state-of-the-art robust fine-tuning methods hurt the calibration of pre-trained VLMs, especially on OOD datasets. To address this issue, we provide a simple approach, called calibrated robust fine-tuning (CaRot), that incentivizes calibration and robustness on both ID and OOD datasets. Empirical results on ImageNet-1K distribution shift evaluation verify the effectiveness of our method.
MFAAN: Unveiling Audio Deepfakes with a Multi-Feature Authenticity Network
Nov 06, 2023In the contemporary digital age, the proliferation of deepfakes presents a formidable challenge to the sanctity of information dissemination. Audio deepfakes, in particular, can be deceptively realistic, posing significant risks in misinformation campaigns. To address this threat, we introduce the Multi-Feature Audio Authenticity Network (MFAAN), an advanced architecture tailored for the detection of fabricated audio content. MFAAN incorporates multiple parallel paths designed to harness the strengths of different audio representations, including Mel-frequency cepstral coefficients (MFCC), linear-frequency cepstral coefficients (LFCC), and Chroma Short Time Fourier Transform (Chroma-STFT). By synergistically fusing these features, MFAAN achieves a nuanced understanding of audio content, facilitating robust differentiation between genuine and manipulated recordings. Preliminary evaluations of MFAAN on two benchmark datasets, 'In-the-Wild' Audio Deepfake Data and The Fake-or-Real Dataset, demonstrate its superior performance, achieving accuracies of 98.93% and 94.47% respectively. Such results not only underscore the efficacy of MFAAN but also highlight its potential as a pivotal tool in the ongoing battle against deepfake audio content.
Performance Prediction of Data-Driven Knowledge summarization of High Entropy Alloys (HEAs) literature implementing Natural Language Processing algorithms
Nov 06, 2023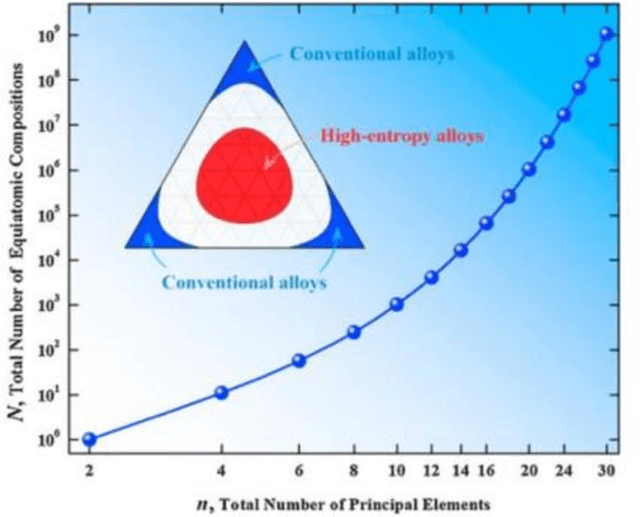
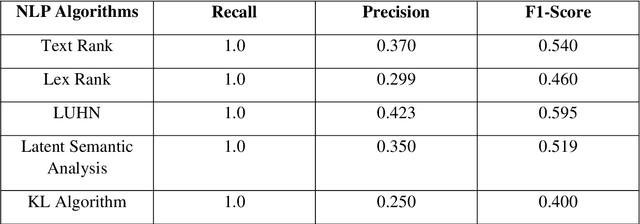
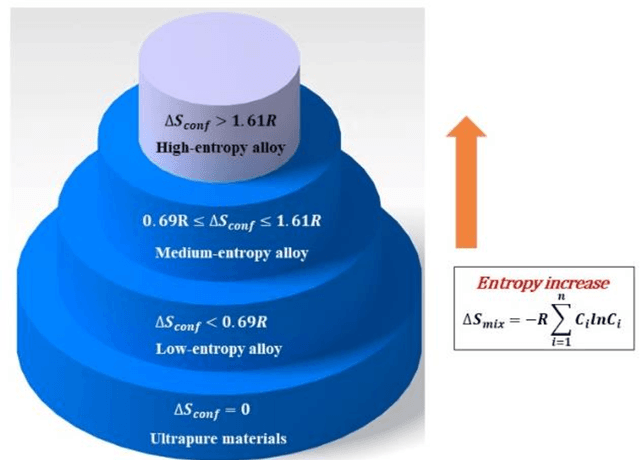
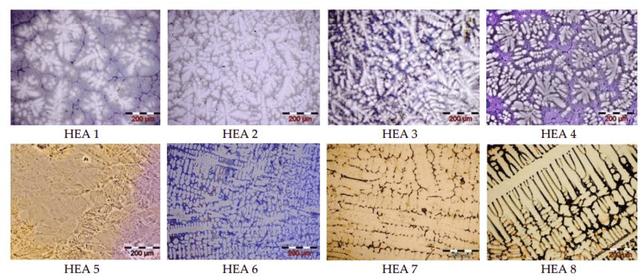
The ability to interpret spoken language is connected to natural language processing. It involves teaching the AI how words relate to one another, how they are meant to be used, and in what settings. The goal of natural language processing (NLP) is to get a machine intelligence to process words the same way a human brain does. This enables machine intelligence to interpret, arrange, and comprehend textual data by processing the natural language. The technology can comprehend what is communicated, whether it be through speech or writing because AI pro-cesses language more quickly than humans can. In the present study, five NLP algorithms, namely, Geneism, Sumy, Luhn, Latent Semantic Analysis (LSA), and Kull-back-Liebler (KL) al-gorithm, are implemented for the first time for the knowledge summarization purpose of the High Entropy Alloys (HEAs). The performance prediction of these algorithms is made by using the BLEU score and ROUGE score. The results showed that the Luhn algorithm has the highest accuracy score for the knowledge summarization tasks compared to the other used algorithms.
Consistent4D: Consistent 360° Dynamic Object Generation from Monocular Video
Nov 06, 2023In this paper, we present Consistent4D, a novel approach for generating 4D dynamic objects from uncalibrated monocular videos. Uniquely, we cast the 360-degree dynamic object reconstruction as a 4D generation problem, eliminating the need for tedious multi-view data collection and camera calibration. This is achieved by leveraging the object-level 3D-aware image diffusion model as the primary supervision signal for training Dynamic Neural Radiance Fields (DyNeRF). Specifically, we propose a Cascade DyNeRF to facilitate stable convergence and temporal continuity under the supervision signal which is discrete along the time axis. To achieve spatial and temporal consistency, we further introduce an Interpolation-driven Consistency Loss. It is optimized by minimizing the discrepancy between rendered frames from DyNeRF and interpolated frames from a pre-trained video interpolation model. Extensive experiments show that our Consistent4D can perform competitively to prior art alternatives, opening up new possibilities for 4D dynamic object generation from monocular videos, whilst also demonstrating advantage for conventional text-to-3D generation tasks. Our project page is https://consistent4d.github.io/.
Keeping in Time: Adding Temporal Context to Sentiment Analysis Models
Sep 24, 2023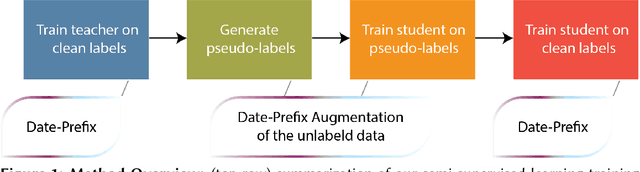

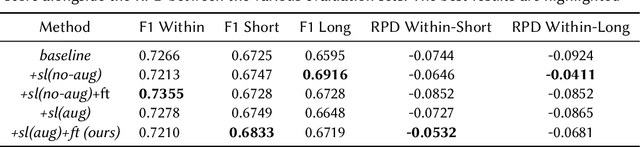
This paper presents a state-of-the-art solution to the LongEval CLEF 2023 Lab Task 2: LongEval-Classification. The goal of this task is to improve and preserve the performance of sentiment analysis models across shorter and longer time periods. Our framework feeds date-prefixed textual inputs to a pre-trained language model, where the timestamp is included in the text. We show date-prefixed samples better conditions model outputs on the temporal context of the respective texts. Moreover, we further boost performance by performing self-labeling on unlabeled data to train a student model. We augment the self-labeling process using a novel augmentation strategy leveraging the date-prefixed formatting of our samples. We demonstrate concrete performance gains on the LongEval-Classification evaluation set over non-augmented self-labeling. Our framework achieves a 2nd place ranking with an overall score of 0.6923 and reports the best Relative Performance Drop (RPD) of -0.0656 over the short evaluation set.