 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HRTF Estimation in the Wild
Nov 06, 2023
Head Related Transfer Functions (HRTFs) play a crucial role in creating immersive spatial audio experiences. However, HRTFs differ significantly from person to person, and traditional methods for estimating personalized HRTFs are expensive, time-consuming, and require specialized equipment. We imagine a world where your personalized HRTF can be determined by capturing data through earbuds in everyday environments. In this paper, we propose a novel approach for deriving personalized HRTFs that only relies on in-the-wild binaural recordings and head tracking data. By analyzing how sounds change as the user rotates their head through different environments with different noise sources, we can accurately estimate their personalized HRTF. Our results show that our predicted HRTFs closely match ground-truth HRTFs measured in an anechoic chamber. Furthermore, listening studies demonstrate that our personalized HRTFs significantly improve sound localization and reduce front-back confusion in virtual environments. Our approach offers an efficient and accessible method for deriving personalized HRTFs and has the potential to greatly improve spatial audio experiences.
InterVLS: Interactive Model Understanding and Improvement with Vision-Language Surrogates
Nov 06, 2023Deep learning models are widely used in critical applications, highlighting the need for pre-deployment model understanding and improvement. Visual concept-based methods, while increasingly used for this purpose, face challenges: (1) most concepts lack interpretability, (2) existing methods require model knowledge, often unavailable at run time. Additionally, (3) there lacks a no-code method for post-understanding model improvement. Addressing these, we present InterVLS. The system facilitates model understanding by discovering text-aligned concepts, measuring their influence with model-agnostic linear surrogates. Employing visual analytics, InterVLS offers concept-based explanations and performance insights. It enables users to adjust concept influences to update a model, facilitating no-code model improvement. We evaluate InterVLS in a user study, illustrating its functionality with two scenarios. Results indicates that InterVLS is effective to help users identify influential concepts to a model, gain insights and adjust concept influence to improve the model. We conclude with a discussion based on our study results.
Context Unlocks Emotions: Text-based Emotion Classification Dataset Auditing with Large Language Models
Nov 06, 2023The lack of contextual information in text data can make the annotation process of text-based emotion classification datasets challenging. As a result, such datasets often contain labels that fail to consider all the relevant emotions in the vocabulary. This misalignment between text inputs and labels can degrade the performance of machine learning models trained on top of them. As re-annotating entire datasets is a costly and time-consuming task that cannot be done at scale, we propose to use the expressive capabilities of large language models to synthesize additional context for input text to increase its alignment with the annotated emotional labels. In this work, we propose a formal definition of textual context to motivate a prompting strategy to enhance such contextual information. We provide both human and empirical evaluation to demonstrate the efficacy of the enhanced context. Our method improves alignment between inputs and their human-annotated labels from both an empirical and human-evaluated standpoint.
GQKVA: Efficient Pre-training of Transformers by Grouping Queries, Keys, and Values
Nov 06, 2023Massive transformer-based models face several challenges, including slow and computationally intensive pre-training and over-parametrization. This paper addresses these challenges by proposing a versatile method called GQKVA, which generalizes query, key, and value grouping techniques. GQKVA is designed to speed up transformer pre-training while reducing the model size. Our experiments with various GQKVA variants highlight a clear trade-off between performance and model size, allowing for customized choices based on resource and time limitations. Our findings also indicate that the conventional multi-head attention approach is not always the best choice, as there are lighter and faster alternatives available. We tested our method on ViT, which achieved an approximate 0.3% increase in accuracy while reducing the model size by about 4% in the task of image classification. Additionally, our most aggressive model reduction experiment resulted in a reduction of approximately 15% in model size, with only around a 1% drop in accuracy.
A Robust Bi-Directional Algorithm For People Count In Crowded Areas
Nov 06, 2023People counting system in crowded places has become a very useful practical application that can be accomplished in various ways which include many traditional methods using sensors. Examining the case of real time scenarios, the algorithm espoused should be steadfast and accurate. People counting algorithm presented in this paper, is centered on blob assessment, devoted to yield the count of the people through a path along with the direction of traversal. The system depicted is often ensconced at the entrance of a building so that the unmitigated frequency of visitors can be recorded. The core premise of this work is to extricate count of people inflow and outflow pertaining to a particular area. The tot-up achieved can be exploited for purpose of statistics in the circumstances of any calamity occurrence in that zone. Relying upon the count totaled, the population in that vicinity can be assimilated in order to take on relevant measures to rescue the people.
CROMA: Remote Sensing Representations with Contrastive Radar-Optical Masked Autoencoders
Nov 01, 2023A vital and rapidly growing application, remote sensing offers vast yet sparsely labeled, spatially aligned multimodal data; this makes self-supervised learning algorithms invaluable. We present CROMA: a framework that combines contrastive and reconstruction self-supervised objectives to learn rich unimodal and multimodal representations. Our method separately encodes masked-out multispectral optical and synthetic aperture radar samples -- aligned in space and time -- and performs cross-modal contrastive learning. Another encoder fuses these sensors, producing joint multimodal encodings that are used to predict the masked patches via a lightweight decoder. We show that these objectives are complementary when leveraged on spatially aligned multimodal data. We also introduce X- and 2D-ALiBi, which spatially biases our cross- and self-attention matrices. These strategies improve representations and allow our models to effectively extrapolate to images up to 17.6x larger at test-time. CROMA outperforms the current SoTA multispectral model, evaluated on: four classification benchmarks -- finetuning (avg. 1.8%), linear (avg. 2.4%) and nonlinear (avg. 1.4%) probing, kNN classification (avg. 3.5%), and K-means clustering (avg. 8.4%); and three segmentation benchmarks (avg. 6.4%). CROMA's rich, optionally multimodal representations can be widely leveraged across remote sensing applications.
Serving Time: Real-Time, Safe Motion Planning and Control for Manipulation of Unsecured Objects
Sep 06, 2023A key challenge to ensuring the rapid transition of robotic systems from the industrial sector to more ubiquitous applications is the development of algorithms that can guarantee safe operation while in close proximity to humans. Motion planning and control methods, for instance, must be able to certify safety while operating in real-time in arbitrary environments and in the presence of model uncertainty. This paper proposes Wrench Analysis for Inertial Transport using Reachability (WAITR), a certifiably safe motion planning and control framework for serial link manipulators that manipulate unsecured objects in arbitrary environments. WAITR uses reachability analysis to construct over-approximations of the contact wrench applied to unsecured objects, which captures uncertainty in the manipulator dynamics, the object dynamics, and contact parameters such as the coefficient of friction. An optimization problem formulation is presented that can be solved in real-time to generate provably-safe motions for manipulating the unsecured objects. This paper illustrates that WAITR outperforms state of the art methods in a variety of simulation experiments and demonstrates its performance in the real-world.
A Proof of Concept for OTFS Resilience in Doubly-Selective Channels by GPU-Enabled Real-Time SDR
Sep 22, 2023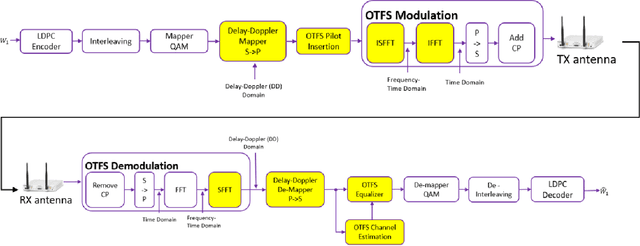
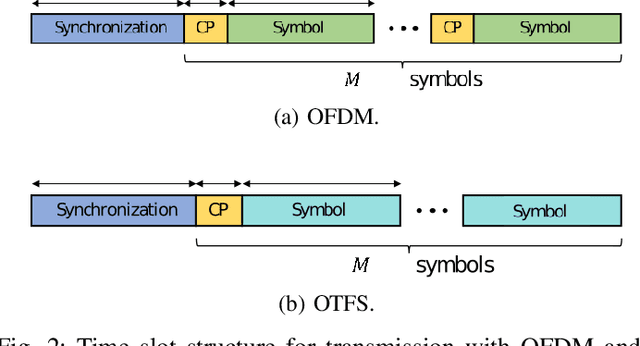
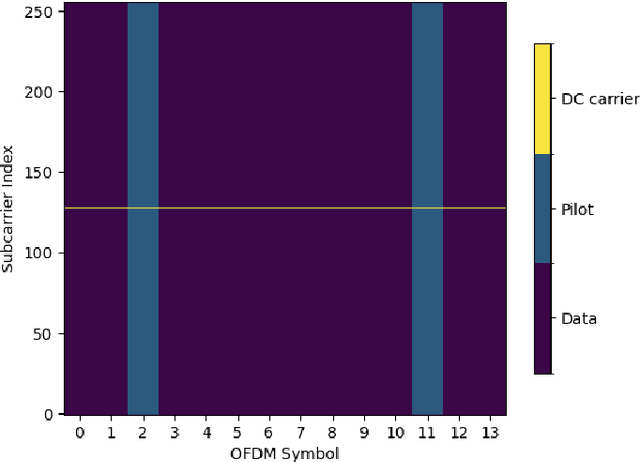
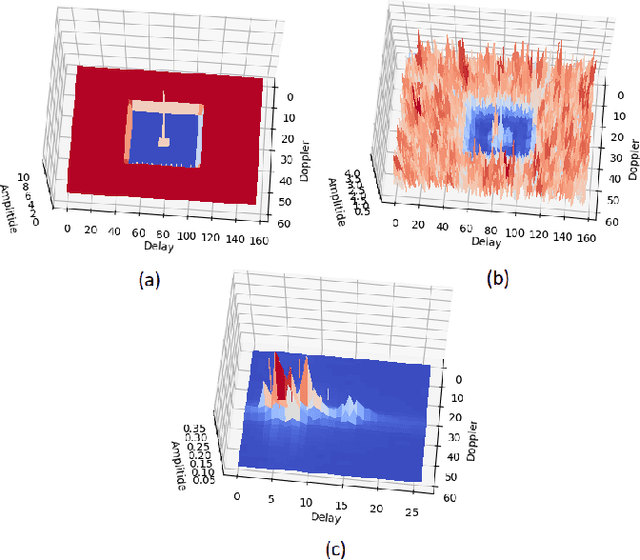
Orthogonal time frequency space (OTFS) is a modulation technique which is robust against the disruptive effects of doubly-selective channels. In this paper, we perform an experimental study of OTFS by a real-time software defined radio (SDR) setup. Our SDR consists of a Graphical Processing Unit (GPU) for signal processing programmed using Sionna and TensorFlow, and Universal Software Radio Peripheral (USRP) devices for air interface. We implement a low-latency transceiver structure for OTFS and investigate its performance under various Doppler values. By comparing the performance of OTFS with Orthogonal Frequency Division Multiplexing (OFDM), we demonstrate that OTFS is highly robust against the disruptive effects of doubly-selective channels in a real-time experimental setup.
On the Representational Capacity of Recurrent Neural Language Models
Oct 23, 2023This work investigates the computational expressivity of language models (LMs) based on recurrent neural networks (RNNs). Siegelmann and Sontag (1992) famously showed that RNNs with rational weights and hidden states and unbounded computation time are Turing complete. However, LMs define weightings over strings in addition to just (unweighted) language membership and the analysis of the computational power of RNN LMs (RLMs) should reflect this. We extend the Turing completeness result to the probabilistic case, showing how a rationally weighted RLM with unbounded computation time can simulate any probabilistic Turing machine (PTM). Since, in practice, RLMs work in real-time, processing a symbol at every time step, we treat the above result as an upper bound on the expressivity of RLMs. We also provide a lower bound by showing that under the restriction to real-time computation, such models can simulate deterministic real-time rational PTMs.
Quantum Neural Networks for Power Flow Analysis
Nov 04, 2023This paper explores the potential application of quantum and hybrid quantum-classical neural networks in power flow analysis. Experiments are conducted using two small-size datasets based on the IEEE 4-bus and 33-bus test systems. A systematic performance comparison is also conducted among quantum, hybrid quantum-classical, and classical neural networks. The comparison is based on (i) generalization ability, (ii) robustness, (iii) training dataset size needed, (iv) training error. (v) training computational time, and (vi) training process stability. The results show that the developed quantum-classical neural network outperforms both quantum and classical neural networks, and hence can improve deep learning-based power flow analysis in the noisy-intermediate-scale quantum (NISQ) era.