 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BrainNetDiff: Generative AI Empowers Brain Network Generation via Multimodal Diffusion Model
Nov 09, 2023
Brain network analysis has emerged as pivotal method for gaining a deeper understanding of brain functions and disease mechanisms. Despite the existence of various network construction approaches, shortcomings persist in the learning of correlations between structural and functional brain imaging data. In light of this, we introduce a novel method called BrainNetDiff, which combines a multi-head Transformer encoder to extract relevant features from fMRI time series and integrates a conditional latent diffusion model for brain network generation. Leveraging a conditional prompt and a fusion attention mechanism, this method significantly improves the accuracy and stability of brain network generation. To the best of our knowledge, this represents the first framework that employs diffusion for the fusion of the multimodal brain imaging and brain network generation from images to graphs. We validate applicability of this framework in the construction of brain network across healthy and neurologically impaired cohorts using the authentic dataset. Experimental results vividly demonstrate the significant effectiveness of the proposed method across the downstream disease classification tasks. These findings convincingly emphasize the prospective value in the field of brain network research, particularly its key significance in neuroimaging analysis and disease diagnosis. This research provides a valuable reference for the processing of multimodal brain imaging data and introduces a novel, efficient solution to the field of neuroimaging.
A differentiable brain simulator bridging brain simulation and brain-inspired computing
Nov 09, 2023Brain simulation builds dynamical models to mimic the structure and functions of the brain, while brain-inspired computing (BIC) develops intelligent systems by learning from the structure and functions of the brain. The two fields are intertwined and should share a common programming framework to facilitate each other's development. However, none of the existing software in the fields can achieve this goal, because traditional brain simulators lack differentiability for training, while existing deep learning (DL) frameworks fail to capture the biophysical realism and complexity of brain dynamics. In this paper, we introduce BrainPy, a differentiable brain simulator developed using JAX and XLA, with the aim of bridging the gap between brain simulation and BIC. BrainPy expands upon the functionalities of JAX, a powerful AI framework, by introducing complete capabilities for flexible, efficient, and scalable brain simulation. It offers a range of sparse and event-driven operators for efficient and scalable brain simulation, an abstraction for managing the intricacies of synaptic computations, a modular and flexible interface for constructing multi-scale brain models, and an object-oriented just-in-time compilation approach to handle the memory-intensive nature of brain dynamics. We showcase the efficiency and scalability of BrainPy on benchmark tasks, highlight its differentiable simulation for biologically plausible spiking models, and discuss its potential to support research at the intersection of brain simulation and BIC.
TransReg: Cross-transformer as auto-registration module for multi-view mammogram mass detection
Nov 09, 2023Screening mammography is the most widely used method for early breast cancer detection, significantly reducing mortality rates. The integration of information from multi-view mammograms enhances radiologists' confidence and diminishes false-positive rates since they can examine on dual-view of the same breast to cross-reference the existence and location of the lesion. Inspired by this, we present TransReg, a Computer-Aided Detection (CAD) system designed to exploit the relationship between craniocaudal (CC), and mediolateral oblique (MLO) views. The system includes cross-transformer to model the relationship between the region of interest (RoIs) extracted by siamese Faster RCNN network for mass detection problems. Our work is the first time cross-transformer has been integrated into an object detection framework to model the relation between ipsilateral views. Our experimental evaluation on DDSM and VinDr-Mammo datasets shows that our TransReg, equipped with SwinT as a feature extractor achieves state-of-the-art performance. Specifically, at the false positive rate per image at 0.5, TransReg using SwinT gets a recall at 83.3% for DDSM dataset and 79.7% for VinDr-Mammo dataset. Furthermore, we conduct a comprehensive analysis to demonstrate that cross-transformer can function as an auto-registration module, aligning the masses in dual-view and utilizing this information to inform final predictions. It is a replication diagnostic workflow of expert radiologists
SODAWideNet -- Salient Object Detection with an Attention augmented Wide Encoder Decoder network without ImageNet pre-training
Nov 09, 2023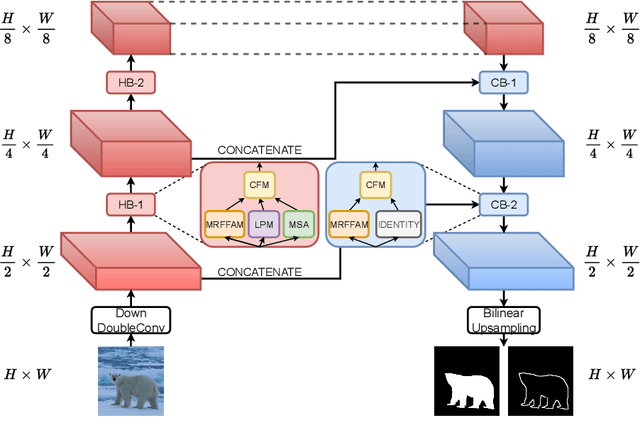

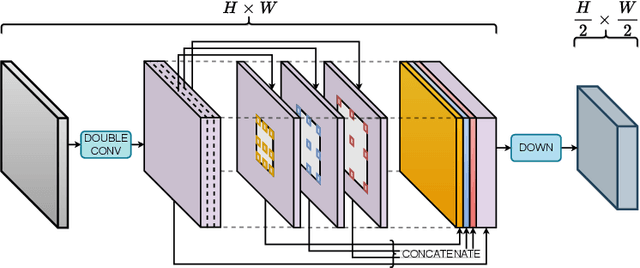
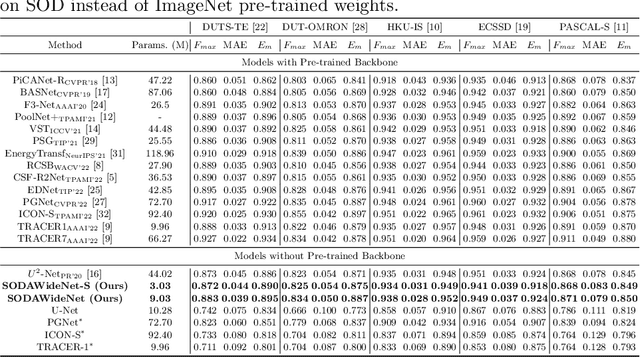
Developing a new Salient Object Detection (SOD) model involves selecting an ImageNet pre-trained backbone and creating novel feature refinement modules to use backbone features. However, adding new components to a pre-trained backbone needs retraining the whole network on the ImageNet dataset, which requires significant time. Hence, we explore developing a neural network from scratch directly trained on SOD without ImageNet pre-training. Such a formulation offers full autonomy to design task-specific components. To that end, we propose SODAWideNet, an encoder-decoder-style network for Salient Object Detection. We deviate from the commonly practiced paradigm of narrow and deep convolutional models to a wide and shallow architecture, resulting in a parameter-efficient deep neural network. To achieve a shallower network, we increase the receptive field from the beginning of the network using a combination of dilated convolutions and self-attention. Therefore, we propose Multi Receptive Field Feature Aggregation Module (MRFFAM) that efficiently obtains discriminative features from farther regions at higher resolutions using dilated convolutions. Next, we propose Multi-Scale Attention (MSA), which creates a feature pyramid and efficiently computes attention across multiple resolutions to extract global features from larger feature maps. Finally, we propose two variants, SODAWideNet-S (3.03M) and SODAWideNet (9.03M), that achieve competitive performance against state-of-the-art models on five datasets.
An Experimental Design for Anytime-Valid Causal Inference on Multi-Armed Bandits
Nov 09, 2023Typically, multi-armed bandit (MAB) experiments are analyzed at the end of the study and thus require the analyst to specify a fixed sample size in advance. However, in many online learning applications, it is advantageous to continuously produce inference on the average treatment effect (ATE) between arms as new data arrive and determine a data-driven stopping time for the experiment. Existing work on continuous inference for adaptive experiments assumes that the treatment assignment probabilities are bounded away from zero and one, thus excluding nearly all standard bandit algorithms. In this work, we develop the Mixture Adaptive Design (MAD), a new experimental design for multi-armed bandits that enables continuous inference on the ATE with guarantees on statistical validity and power for nearly any bandit algorithm. On a high level, the MAD "mixes" a bandit algorithm of the user's choice with a Bernoulli design through a tuning parameter $\delta_t$, where $\delta_t$ is a deterministic sequence that controls the priority placed on the Bernoulli design as the sample size grows. We show that for $\delta_t = o\left(1/t^{1/4}\right)$, the MAD produces a confidence sequence that is asymptotically valid and guaranteed to shrink around the true ATE. We empirically show that the MAD improves the coverage and power of ATE inference in MAB experiments without significant losses in finite-sample reward.
FireMatch: A Semi-Supervised Video Fire Detection Network Based on Consistency and Distribution Alignment
Nov 09, 2023Deep learning techniques have greatly enhanced the performance of fire detection in videos. However, video-based fire detection models heavily rely on labeled data, and the process of data labeling is particularly costly and time-consuming, especially when dealing with videos. Considering the limited quantity of labeled video data, we propose a semi-supervised fire detection model called FireMatch, which is based on consistency regularization and adversarial distribution alignment. Specifically, we first combine consistency regularization with pseudo-label. For unlabeled data, we design video data augmentation to obtain corresponding weakly augmented and strongly augmented samples. The proposed model predicts weakly augmented samples and retains pseudo-label above a threshold, while training on strongly augmented samples to predict these pseudo-labels for learning more robust feature representations. Secondly, we generate video cross-set augmented samples by adversarial distribution alignment to expand the training data and alleviate the decline in classification performance caused by insufficient labeled data. Finally, we introduce a fairness loss to help the model produce diverse predictions for input samples, thereby addressing the issue of high confidence with the non-fire class in fire classification scenarios. The FireMatch achieved an accuracy of 76.92% and 91.81% on two real-world fire datasets, respectively. The experimental results demonstrate that the proposed method outperforms the current state-of-the-art semi-supervised classification methods.
Online Signal Estimation on the Graph Edges via Line Graph Transformation
Nov 01, 2023We propose the Line Graph Normalized Least Mean Square (LGNLMS) algorithm for online time-varying graph edge signals prediction. LGNLMS utilizes the Line Graph to transform graph edge signals into the node of its edge-to-vertex dual. This enables edge signals to be processed using established GSP concepts without redefining them on graph edges.
Clustering of Urban Traffic Patterns by K-Means and Dynamic Time Warping: Case Study
Sep 18, 2023Clustering of urban traffic patterns is an essential task in many different areas of traffic management and planning. In this paper, two significant applications in the clustering of urban traffic patterns are described. The first application estimates the missing speed values using the speed of road segments with similar traffic patterns to colorify map tiles. The second one is the estimation of essential road segments for generating addresses for a local point on the map, using the similarity patterns of different road segments. The speed time series extracts the traffic pattern in different road segments. In this paper, we proposed the time series clustering algorithm based on K-Means and Dynamic Time Warping. The case study of our proposed algorithm is based on the Snapp application's driver speed time series data. The results of the two applications illustrate that the proposed method can extract similar urban traffic patterns.
Untargeted White-box Adversarial Attack with Heuristic Defence Methods in Real-time Deep Learning based Network Intrusion Detection System
Oct 05, 2023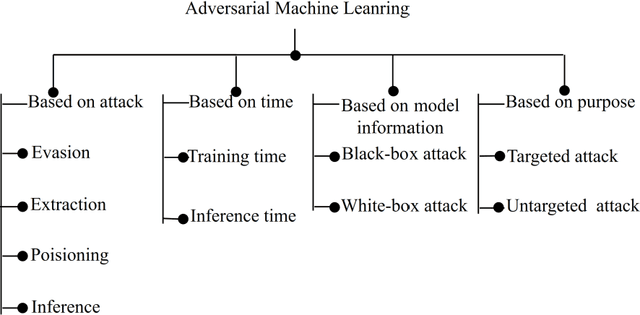

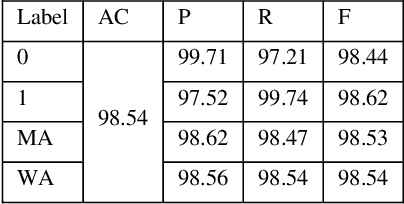
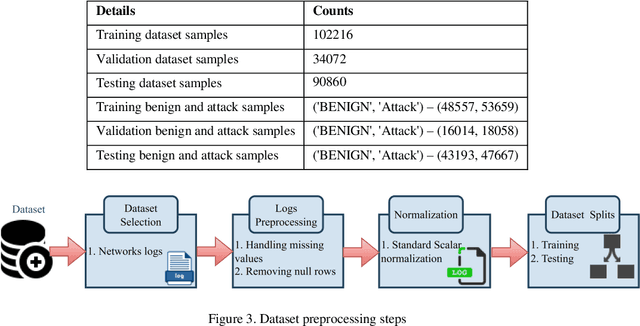
Network Intrusion Detection System (NIDS) is a key component in securing the computer network from various cyber security threats and network attacks. However, consider an unfortunate situation where the NIDS is itself attacked and vulnerable more specifically, we can say, How to defend the defender?. In Adversarial Machine Learning (AML), the malicious actors aim to fool the Machine Learning (ML) and Deep Learning (DL) models to produce incorrect predictions with intentionally crafted adversarial examples. These adversarial perturbed examples have become the biggest vulnerability of ML and DL based systems and are major obstacles to their adoption in real-time and mission-critical applications such as NIDS. AML is an emerging research domain, and it has become a necessity for the in-depth study of adversarial attacks and their defence strategies to safeguard the computer network from various cyber security threads. In this research work, we aim to cover important aspects related to NIDS, adversarial attacks and its defence mechanism to increase the robustness of the ML and DL based NIDS. We implemented four powerful adversarial attack techniques, namely, Fast Gradient Sign Method (FGSM), Jacobian Saliency Map Attack (JSMA), Projected Gradient Descent (PGD) and Carlini & Wagner (C&W) in NIDS. We analyzed its performance in terms of various performance metrics in detail. Furthermore, the three heuristics defence strategies, i.e., Adversarial Training (AT), Gaussian Data Augmentation (GDA) and High Confidence (HC), are implemented to improve the NIDS robustness under adversarial attack situations. The complete workflow is demonstrated in real-time network with data packet flow. This research work provides the overall background for the researchers interested in AML and its implementation from a computer network security point of view.
Joint Problems in Learning Multiple Dynamical Systems
Nov 03, 2023Clustering of time series is a well-studied problem, with applications ranging from quantitative, personalized models of metabolism obtained from metabolite concentrations to state discrimination in quantum information theory. We consider a variant, where given a set of trajectories and a number of parts, we jointly partition the set of trajectories and learn linear dynamical system (LDS) models for each part, so as to minimize the maximum error across all the models. We present globally convergent methods and EM heuristics, accompanied by promising computational results.