 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bayesian Simulation-based Inference for Cosmological Initial Conditions
Oct 30, 2023
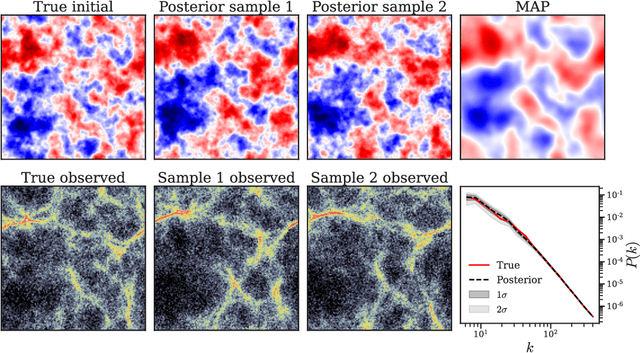
Reconstructing astrophysical and cosmological fields from observations is challenging. It requires accounting for non-linear transformations, mixing of spatial structure, and noise. In contrast, forward simulators that map fields to observations are readily available for many applications. We present a versatile Bayesian field reconstruction algorithm rooted in simulation-based inference and enhanced by autoregressive modeling. The proposed technique is applicable to generic (non-differentiable) forward simulators and allows sampling from the posterior for the underlying field. We show first promising results on a proof-of-concept application: the recovery of cosmological initial conditions from late-time density fields.
Uncertainty Estimation for Safety-critical Scene Segmentation via Fine-grained Reward Maximization
Nov 05, 2023Uncertainty estimation plays an important role for future reliable deployment of deep segmentation models in safety-critical scenarios such as medical applications. However, existing methods for uncertainty estimation have been limited by the lack of explicit guidance for calibrating the prediction risk and model confidence. In this work, we propose a novel fine-grained reward maximization (FGRM) framework, to address uncertainty estimation by directly utilizing an uncertainty metric related reward function with a reinforcement learning based model tuning algorithm. This would benefit the model uncertainty estimation through direct optimization guidance for model calibration. Specifically, our method designs a new uncertainty estimation reward function using the calibration metric, which is maximized to fine-tune an evidential learning pre-trained segmentation model for calibrating prediction risk. Importantly, we innovate an effective fine-grained parameter update scheme, which imposes fine-grained reward-weighting of each network parameter according to the parameter importance quantified by the fisher information matrix. To the best of our knowledge, this is the first work exploring reward optimization for model uncertainty estimation in safety-critical vision tasks. The effectiveness of our method is demonstrated on two large safety-critical surgical scene segmentation datasets under two different uncertainty estimation settings. With real-time one forward pass at inference, our method outperforms state-of-the-art methods by a clear margin on all the calibration metrics of uncertainty estimation, while maintaining a high task accuracy for the segmentation results. Code is available at \url{https://github.com/med-air/FGRM}.
Multi-task Learning for Optical Coherence Tomography Angiography (OCTA) Vessel Segmentation
Nov 03, 2023Optical Coherence Tomography Angiography (OCTA) is a non-invasive imaging technique that provides high-resolution cross-sectional images of the retina, which are useful for diagnosing and monitoring various retinal diseases. However, manual segmentation of OCTA images is a time-consuming and labor-intensive task, which motivates the development of automated segmentation methods. In this paper, we propose a novel multi-task learning method for OCTA segmentation, called OCTA-MTL, that leverages an image-to-DT (Distance Transform) branch and an adaptive loss combination strategy. The image-to-DT branch predicts the distance from each vessel voxel to the vessel surface, which can provide useful shape prior and boundary information for the segmentation task. The adaptive loss combination strategy dynamically adjusts the loss weights according to the inverse of the average loss values of each task, to balance the learning process and avoid the dominance of one task over the other. We evaluate our method on the ROSE-2 dataset its superiority in terms of segmentation performance against two baseline methods: a single-task segmentation method and a multi-task segmentation method with a fixed loss combination.
Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs
Nov 03, 2023In human-written articles, we often leverage the subtleties of text style, such as bold and italics, to guide the attention of readers. These textual emphases are vital for the readers to grasp the conveyed information. When interacting with large language models (LLMs), we have a similar need - steering the model to pay closer attention to user-specified information, e.g., an instruction. Existing methods, however, are constrained to process plain text and do not support such a mechanism. This motivates us to introduce PASTA - Post-hoc Attention STeering Approach, a method that allows LLMs to read text with user-specified emphasis marks. To this end, PASTA identifies a small subset of attention heads and applies precise attention reweighting on them, directing the model attention to user-specified parts. Like prompting, PASTA is applied at inference time and does not require changing any model parameters. Experiments demonstrate that PASTA can substantially enhance an LLM's ability to follow user instructions or integrate new knowledge from user inputs, leading to a significant performance improvement on a variety of tasks, e.g., an average accuracy improvement of 22% for LLAMA-7B. Our code is publicly available at https://github.com/QingruZhang/PASTA .
Trust-Preserved Human-Robot Shared Autonomy enabled by Bayesian Relational Event Modeling
Nov 03, 2023Shared autonomy functions as a flexible framework that empowers robots to operate across a spectrum of autonomy levels, allowing for efficient task execution with minimal human oversight. However, humans might be intimidated by the autonomous decision-making capabilities of robots due to perceived risks and a lack of trust. This paper proposed a trust-preserved shared autonomy strategy that grants robots to seamlessly adjust their autonomy level, striving to optimize team performance and enhance their acceptance among human collaborators. By enhancing the Relational Event Modeling framework with Bayesian learning techniques, this paper enables dynamic inference of human trust based solely on time-stamped relational events within human-robot teams. Adopting a longitudinal perspective on trust development and calibration in human-robot teams, the proposed shared autonomy strategy warrants robots to preserve human trust by not only passively adapting to it but also actively participating in trust repair when violations occur. We validate the effectiveness of the proposed approach through a user study on human-robot collaborative search and rescue scenarios. The objective and subjective evaluations demonstrate its merits over teleoperation on both task execution and user acceptability.
Bayesian Optimization of Function Networks with Partial Evaluations
Nov 03, 2023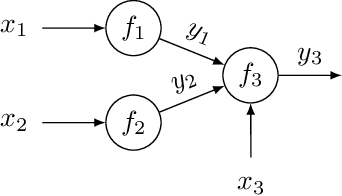
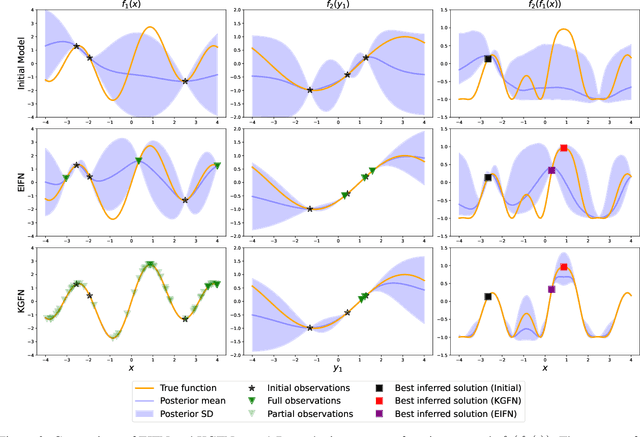

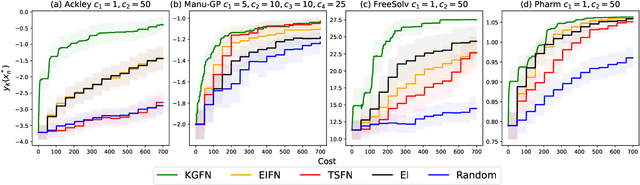
Bayesian optimization is a framework for optimizing functions that are costly or time-consuming to evaluate. Recent work has considered Bayesian optimization of function networks (BOFN), where the objective function is computed via a network of functions, each taking as input the output of previous nodes in the network and additional parameters. Exploiting this network structure has been shown to yield significant performance improvements. Existing BOFN algorithms for general-purpose networks are required to evaluate the full network at each iteration. However, many real-world applications allow evaluating nodes individually. To take advantage of this opportunity, we propose a novel knowledge gradient acquisition function for BOFN that chooses which node to evaluate as well as the inputs for that node in a cost-aware fashion. This approach can dramatically reduce query costs by allowing the evaluation of part of the network at a lower cost relative to evaluating the entire network. We provide an efficient approach to optimizing our acquisition function and show it outperforms existing BOFN methods and other benchmarks across several synthetic and real-world problems. Our acquisition function is the first to enable cost-aware optimization of a broad class of function networks.
AlberDICE: Addressing Out-Of-Distribution Joint Actions in Offline Multi-Agent RL via Alternating Stationary Distribution Correction Estimation
Nov 03, 2023One of the main challenges in offline Reinforcement Learning (RL) is the distribution shift that arises from the learned policy deviating from the data collection policy. This is often addressed by avoiding out-of-distribution (OOD) actions during policy improvement as their presence can lead to substantial performance degradation. This challenge is amplified in the offline Multi-Agent RL (MARL) setting since the joint action space grows exponentially with the number of agents. To avoid this curse of dimensionality, existing MARL methods adopt either value decomposition methods or fully decentralized training of individual agents. However, even when combined with standard conservatism principles, these methods can still result in the selection of OOD joint actions in offline MARL. To this end, we introduce AlberDICE, an offline MARL algorithm that alternatively performs centralized training of individual agents based on stationary distribution optimization. AlberDICE circumvents the exponential complexity of MARL by computing the best response of one agent at a time while effectively avoiding OOD joint action selection. Theoretically, we show that the alternating optimization procedure converges to Nash policies. In the experiments, we demonstrate that AlberDICE significantly outperforms baseline algorithms on a standard suite of MARL benchmarks.
On the Representational Capacity of Recurrent Neural Language Models
Oct 19, 2023This work investigates the computational expressivity of language models (LMs) based on recurrent neural networks (RNNs). Siegelmann and Sontag (1992) famously showed that RNNs with rational weights and hidden states and unbounded computation time are Turing complete. However, LMs define weightings over strings in addition to just (unweighted) language membership and the analysis of the computational power of RNN LMs (RLMs) should reflect this. We extend the Turing completeness result to the probabilistic case, showing how a rationally weighted RLM with unbounded computation time can simulate any probabilistic Turing machine (PTM). Since, in practice, RLMs work in real-time, processing a symbol at every time step, we treat the above result as an upper bound on the expressivity of RLMs. We also provide a lower bound by showing that under the restriction to real-time computation, such models can simulate deterministic real-time rational PTMs.
A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models
Nov 01, 2023A central component of rational behavior is logical inference: the process of determining which conclusions follow from a set of premises. Psychologists have documented several ways in which humans' inferences deviate from the rules of logic. Do language models, which are trained on text generated by humans, replicate these biases, or are they able to overcome them? Focusing on the case of syllogisms -- inferences from two simple premises, which have been studied extensively in psychology -- we show that larger models are more logical than smaller ones, and also more logical than humans. At the same time, even the largest models make systematic errors, some of which mirror human reasoning biases such as ordering effects and logical fallacies. Overall, we find that language models mimic the human biases included in their training data, but are able to overcome them in some cases.
Generalization Bounds for Label Noise Stochastic Gradient Descent
Nov 01, 2023We develop generalization error bounds for stochastic gradient descent (SGD) with label noise in non-convex settings under uniform dissipativity and smoothness conditions. Under a suitable choice of semimetric, we establish a contraction in Wasserstein distance of the label noise stochastic gradient flow that depends polynomially on the parameter dimension $d$. Using the framework of algorithmic stability, we derive time-independent generalisation error bounds for the discretized algorithm with a constant learning rate. The error bound we achieve scales polynomially with $d$ and with the rate of $n^{-2/3}$, where $n$ is the sample size. This rate is better than the best-known rate of $n^{-1/2}$ established for stochastic gradient Langevin dynamics (SGLD) -- which employs parameter-independent Gaussian noise -- under similar conditions. Our analysis offers quantitative insights into the effect of label noise.