 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Prediction of Locally Stationary Data Using Expert Advice
Oct 30, 2023
The problem of continuous machine learning is studied. Within the framework of the game-theoretic approach, when for calculating the next forecast, no assumptions about the stochastic nature of the source that generates the data flow are used -- the source can be analog, algorithmic or probabilistic, its parameters can change at random times, when building a prognostic model, only structural assumptions are used about the nature of data generation. An online forecasting algorithm for a locally stationary time series is presented. An estimate of the efficiency of the proposed algorithm is obtained.
Controlled Decoding from Language Models
Oct 25, 2023We propose controlled decoding (CD), a novel off-policy reinforcement learning method to control the autoregressive generation from language models towards high reward outcomes. CD solves an off-policy reinforcement learning problem through a value function for the reward, which we call a prefix scorer. The prefix scorer is used at inference time to steer the generation towards higher reward outcomes. We show that the prefix scorer may be trained on (possibly) off-policy data to predict the expected reward when decoding is continued from a partially decoded response. We empirically demonstrate that CD is effective as a control mechanism on Reddit conversations corpus. We also show that the modularity of the design of CD makes it possible to control for multiple rewards, effectively solving a multi-objective reinforcement learning problem with no additional complexity. Finally, we show that CD can be applied in a novel blockwise fashion at inference-time, again without the need for any training-time changes, essentially bridging the gap between the popular best-of-$K$ strategy and token-level reinforcement learning. This makes CD a promising approach for alignment of language models.
One-Shot Strategic Classification Under Unknown Costs
Nov 05, 2023A primary goal in strategic classification is to learn decision rules which are robust to strategic input manipulation. Earlier works assume that strategic responses are known; while some recent works address the important challenge of unknown responses, they exclusively study sequential settings which allow multiple model deployments over time. But there are many domains$\unicode{x2014}$particularly in public policy, a common motivating use-case$\unicode{x2014}$where multiple deployments are unrealistic, or where even a single bad round is undesirable. To address this gap, we initiate the study of strategic classification under unknown responses in the one-shot setting, which requires committing to a single classifier once. Focusing on the users' cost function as the source of uncertainty, we begin by proving that for a broad class of costs, even a small mis-estimation of the true cost can entail arbitrarily low accuracy in the worst case. In light of this, we frame the one-shot task as a minimax problem, with the goal of identifying the classifier with the smallest worst-case risk over an uncertainty set of possible costs. Our main contribution is efficient algorithms for both the full-batch and stochastic settings, which we prove converge (offline) to the minimax optimal solution at the dimension-independent rate of $\tilde{\mathcal{O}}(T^{-\frac{1}{2}})$. Our analysis reveals important structure stemming from the strategic nature of user responses, particularly the importance of dual norm regularization with respect to the cost function.
Wideband Beamforming for STAR-RIS-assisted THz Communications with Three-Side Beam Split
Oct 21, 2023In this paper, we consider the simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS)-assisted THz communications with three-side beam split. Except for the beam split at the base station (BS), we analyze the double-side beam split at the STAR-RIS for the first time. To relieve the double-side beam split effect, we propose a time delayer (TD)-based fully-connected structure at the STAR-RIS. As a further advance, a low-hardware complexity and low-power consumption sub-connected structure is developed, where multiple STAR-RIS elements share one TD. Meanwhile, considering the practical scenario, we investigate a multi-STAR-RIS and multi-user communication system, and a sum rate maximization problem is formulated by jointly optimizing the hybrid analog/digital beamforming, time delays at the BS as well as the double-layer phase-shift coefficients, time delays and amplitude coefficients at the STAR-RISs. Based on this, we first allocate users for each STAR-RIS, and then derive the analog beamforming, time delays at the BS, and the double-layer phase-shift coefficients, time delays at each STAR-RIS. Next, we develop an alternative optimization algorithm to calculate the digital beamforming at the BS and amplitude coefficients at the STAR-RISs. Finally, the numerical results verify the effectiveness of the proposed schemes.
Diversifying Spatial-Temporal Perception for Video Domain Generalization
Oct 27, 2023Video domain generalization aims to learn generalizable video classification models for unseen target domains by training in a source domain. A critical challenge of video domain generalization is to defend against the heavy reliance on domain-specific cues extracted from the source domain when recognizing target videos. To this end, we propose to perceive diverse spatial-temporal cues in videos, aiming to discover potential domain-invariant cues in addition to domain-specific cues. We contribute a novel model named Spatial-Temporal Diversification Network (STDN), which improves the diversity from both space and time dimensions of video data. First, our STDN proposes to discover various types of spatial cues within individual frames by spatial grouping. Then, our STDN proposes to explicitly model spatial-temporal dependencies between video contents at multiple space-time scales by spatial-temporal relation modeling. Extensive experiments on three benchmarks of different types demonstrate the effectiveness and versatility of our approach.
Boosting Summarization with Normalizing Flows and Aggressive Training
Nov 01, 2023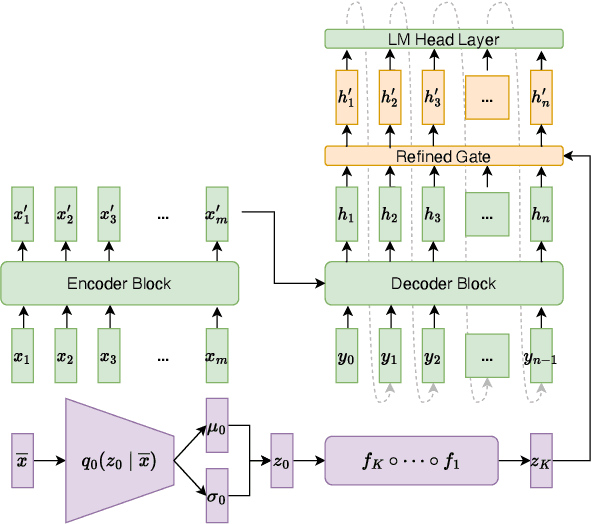
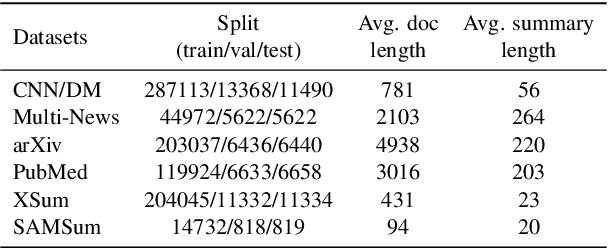
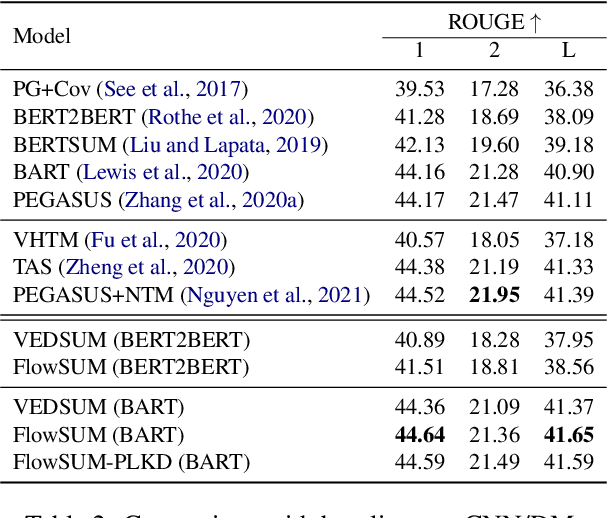
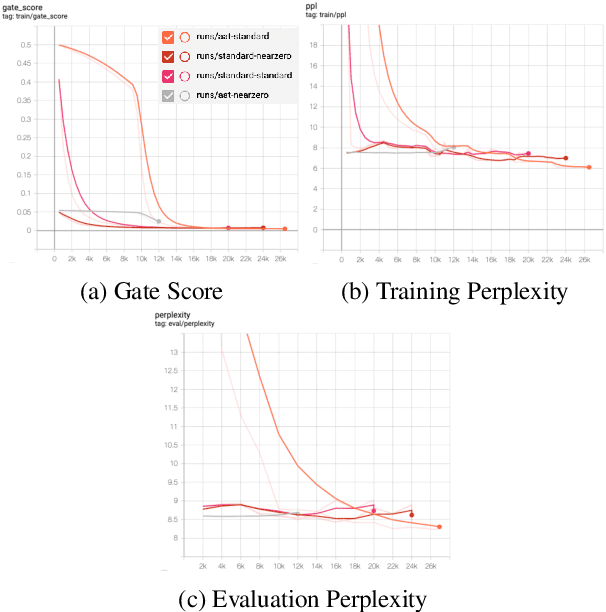
This paper presents FlowSUM, a normalizing flows-based variational encoder-decoder framework for Transformer-based summarization. Our approach tackles two primary challenges in variational summarization: insufficient semantic information in latent representations and posterior collapse during training. To address these challenges, we employ normalizing flows to enable flexible latent posterior modeling, and we propose a controlled alternate aggressive training (CAAT) strategy with an improved gate mechanism. Experimental results show that FlowSUM significantly enhances the quality of generated summaries and unleashes the potential for knowledge distillation with minimal impact on inference time. Furthermore, we investigate the issue of posterior collapse in normalizing flows and analyze how the summary quality is affected by the training strategy, gate initialization, and the type and number of normalizing flows used, offering valuable insights for future research.
PAUMER: Patch Pausing Transformer for Semantic Segmentation
Nov 01, 2023We study the problem of improving the efficiency of segmentation transformers by using disparate amounts of computation for different parts of the image. Our method, PAUMER, accomplishes this by pausing computation for patches that are deemed to not need any more computation before the final decoder. We use the entropy of predictions computed from intermediate activations as the pausing criterion, and find this aligns well with semantics of the image. Our method has a unique advantage that a single network trained with the proposed strategy can be effortlessly adapted at inference to various run-time requirements by modulating its pausing parameters. On two standard segmentation datasets, Cityscapes and ADE20K, we show that our method operates with about a $50\%$ higher throughput with an mIoU drop of about $0.65\%$ and $4.6\%$ respectively.
Learning impartial policies for sequential counterfactual explanations using Deep Reinforcement Learning
Nov 01, 2023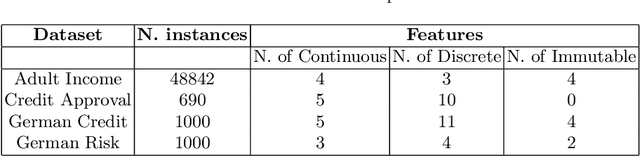
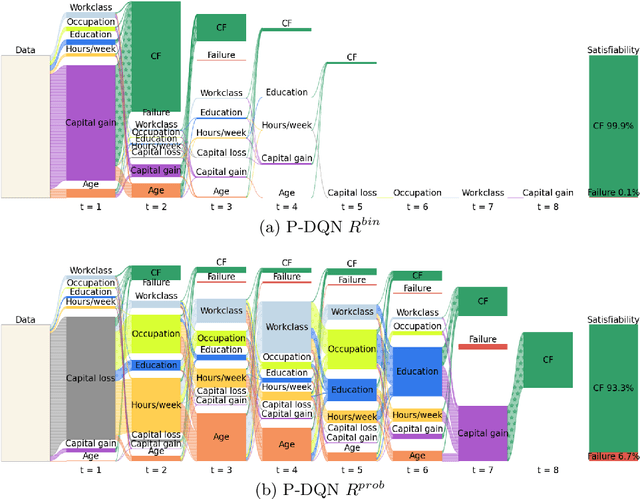
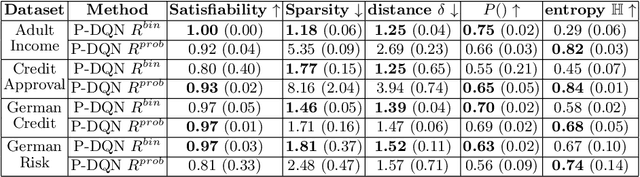
In the field of explainable Artificial Intelligence (XAI), sequential counterfactual (SCF) examples are often used to alter the decision of a trained classifier by implementing a sequence of modifications to the input instance. Although certain test-time algorithms aim to optimize for each new instance individually, recently Reinforcement Learning (RL) methods have been proposed that seek to learn policies for discovering SCFs, thereby enhancing scalability. As is typical in RL, the formulation of the RL problem, including the specification of state space, actions, and rewards, can often be ambiguous. In this work, we identify shortcomings in existing methods that can result in policies with undesired properties, such as a bias towards specific actions. We propose to use the output probabilities of the classifier to create a more informative reward, to mitigate this effect.
Loss Modeling for Multi-Annotator Datasets
Nov 01, 2023Accounting for the opinions of all annotators of a dataset is critical for fairness. However, when annotating large datasets, individual annotators will frequently provide thousands of ratings which can lead to fatigue. Additionally, these annotation processes can occur over multiple days which can lead to an inaccurate representation of an annotator's opinion over time. To combat this, we propose to learn a more accurate representation of diverse opinions by utilizing multitask learning in conjunction with loss-based label correction. We show that using our novel formulation, we can cleanly separate agreeing and disagreeing annotations. Furthermore, we demonstrate that this modification can improve prediction performance in a single or multi-annotator setting. Lastly, we show that this method remains robust to additional label noise that is applied to subjective data.
COSTAR: Improved Temporal Counterfactual Estimation with Self-Supervised Learning
Nov 01, 2023Estimation of temporal counterfactual outcomes from observed history is crucial for decision-making in many domains such as healthcare and e-commerce, particularly when randomized controlled trials (RCTs) suffer from high cost or impracticality. For real-world datasets, modeling time-dependent confounders is challenging due to complex dynamics, long-range dependencies and both past treatments and covariates affecting the future outcomes. In this paper, we introduce COunterfactual Self-supervised TrAnsformeR (COSTAR), a novel approach that integrates self-supervised learning for improved historical representations. The proposed framework combines temporal and feature-wise attention with a component-wise contrastive loss tailored for temporal treatment outcome observations, yielding superior performance in estimation accuracy and generalization to out-of-distribution data compared to existing models, as validated by empirical results on both synthetic and real-world datasets.