 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised and semi-supervised co-salient object detection via segmentation frequency statistics
Nov 11, 2023
In this paper, we address the detection of co-occurring salient objects (CoSOD) in an image group using frequency statistics in an unsupervised manner, which further enable us to develop a semi-supervised method. While previous works have mostly focused on fully supervised CoSOD, less attention has been allocated to detecting co-salient objects when limited segmentation annotations are available for training. Our simple yet effective unsupervised method US-CoSOD combines the object co-occurrence frequency statistics of unsupervised single-image semantic segmentations with salient foreground detections using self-supervised feature learning. For the first time, we show that a large unlabeled dataset e.g. ImageNet-1k can be effectively leveraged to significantly improve unsupervised CoSOD performance. Our unsupervised model is a great pre-training initialization for our semi-supervised model SS-CoSOD, especially when very limited labeled data is available for training. To avoid propagating erroneous signals from predictions on unlabeled data, we propose a confidence estimation module to guide our semi-supervised training. Extensive experiments on three CoSOD benchmark datasets show that both of our unsupervised and semi-supervised models outperform the corresponding state-of-the-art models by a significant margin (e.g., on the Cosal2015 dataset, our US-CoSOD model has an 8.8% F-measure gain over a SOTA unsupervised co-segmentation model and our SS-CoSOD model has an 11.81% F-measure gain over a SOTA semi-supervised CoSOD model).
Data-driven rules for multidimensional reflection problems
Nov 11, 2023Over the recent past data-driven algorithms for solving stochastic optimal control problems in face of model uncertainty have become an increasingly active area of research. However, for singular controls and underlying diffusion dynamics the analysis has so far been restricted to the scalar case. In this paper we fill this gap by studying a multivariate singular control problem for reversible diffusions with controls of reflection type. Our contributions are threefold. We first explicitly determine the long-run average costs as a domain-dependent functional, showing that the control problem can be equivalently characterized as a shape optimization problem. For given diffusion dynamics, assuming the optimal domain to be strongly star-shaped, we then propose a gradient descent algorithm based on polytope approximations to numerically determine a cost-minimizing domain. Finally, we investigate data-driven solutions when the diffusion dynamics are unknown to the controller. Using techniques from nonparametric statistics for stochastic processes, we construct an optimal domain estimator, whose static regret is bounded by the minimax optimal estimation rate of the unreflected process' invariant density. In the most challenging situation, when the dynamics must be learned simultaneously to controlling the process, we develop an episodic learning algorithm to overcome the emerging exploration-exploitation dilemma and show that given the static regret as a baseline, the loss in its sublinear regret per time unit is of natural order compared to the one-dimensional case.
Tracking and fast imaging of a translational object via Fourier modulation
Oct 28, 2023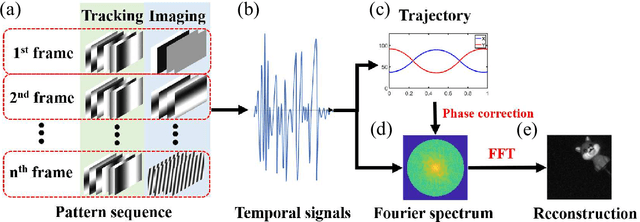
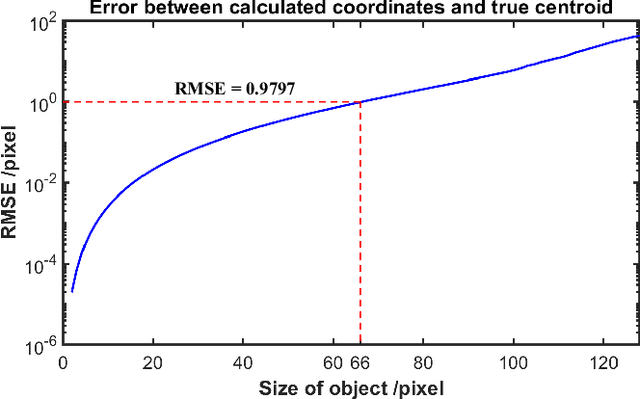
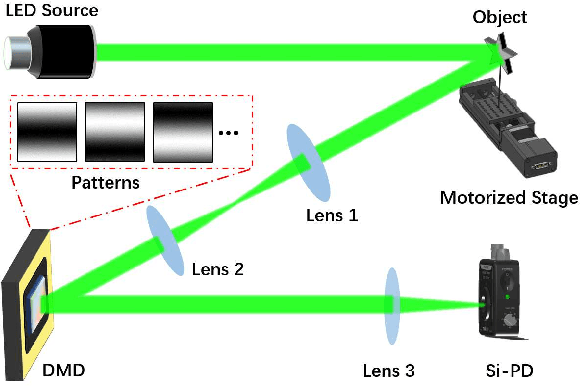

The tracking and imaging of high-speed moving objects hold significant promise for application in various fields. Single-pixel imaging enables the progressive capture of a fast-moving translational object through motion compensation. However, achieving a balance between a short reconstruction time and a good image quality is challenging. In this study, we present a approach that simultaneously incorporates position encoding and spatial information encoding through the Fourier patterns. The utilization of Fourier patterns with specific spatial frequencies ensures robust and accurate object localization. By exploiting the properties of the Fourier transform, our method achieves a remarkable reduction in time complexity and memory consumption while significantly enhancing image quality. Furthermore, we introduce an optimized sampling strategy specifically tailored for small moving objects, significantly reducing the required dwell time for imaging. The proposed method provides a practical solution for the real-time tracking, imaging and edge detection of translational objects, underscoring its considerable potential for diverse applications.
U3DS$^3$: Unsupervised 3D Semantic Scene Segmentation
Nov 10, 2023Contemporary point cloud segmentation approaches largely rely on richly annotated 3D training data. However, it is both time-consuming and challenging to obtain consistently accurate annotations for such 3D scene data. Moreover, there is still a lack of investigation into fully unsupervised scene segmentation for point clouds, especially for holistic 3D scenes. This paper presents U3DS$^3$, as a step towards completely unsupervised point cloud segmentation for any holistic 3D scenes. To achieve this, U3DS$^3$ leverages a generalized unsupervised segmentation method for both object and background across both indoor and outdoor static 3D point clouds with no requirement for model pre-training, by leveraging only the inherent information of the point cloud to achieve full 3D scene segmentation. The initial step of our proposed approach involves generating superpoints based on the geometric characteristics of each scene. Subsequently, it undergoes a learning process through a spatial clustering-based methodology, followed by iterative training using pseudo-labels generated in accordance with the cluster centroids. Moreover, by leveraging the invariance and equivariance of the volumetric representations, we apply the geometric transformation on voxelized features to provide two sets of descriptors for robust representation learning. Finally, our evaluation provides state-of-the-art results on the ScanNet and SemanticKITTI, and competitive results on the S3DIS, benchmark datasets.
MonoProb: Self-Supervised Monocular Depth Estimation with Interpretable Uncertainty
Nov 10, 2023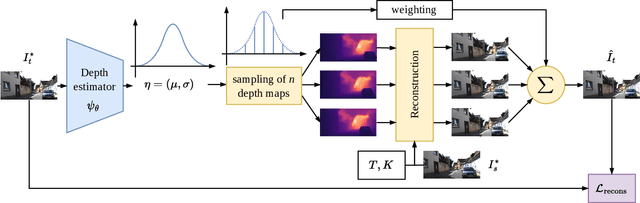
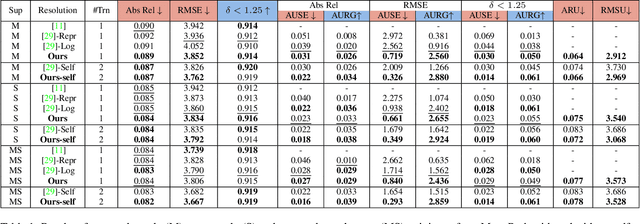


Self-supervised monocular depth estimation methods aim to be used in critical applications such as autonomous vehicles for environment analysis. To circumvent the potential imperfections of these approaches, a quantification of the prediction confidence is crucial to guide decision-making systems that rely on depth estimation. In this paper, we propose MonoProb, a new unsupervised monocular depth estimation method that returns an interpretable uncertainty, which means that the uncertainty reflects the expected error of the network in its depth predictions. We rethink the stereo or the structure-from-motion paradigms used to train unsupervised monocular depth models as a probabilistic problem. Within a single forward pass inference, this model provides a depth prediction and a measure of its confidence, without increasing the inference time. We then improve the performance on depth and uncertainty with a novel self-distillation loss for which a student is supervised by a pseudo ground truth that is a probability distribution on depth output by a teacher. To quantify the performance of our models we design new metrics that, unlike traditional ones, measure the absolute performance of uncertainty predictions. Our experiments highlight enhancements achieved by our method on standard depth and uncertainty metrics as well as on our tailored metrics. https://github.com/CEA-LIST/MonoProb
Synthesizing Bidirectional Temporal States of Knee Osteoarthritis Radiographs with Cycle-Consistent Generative Adversarial Neural Networks
Nov 10, 2023Knee Osteoarthritis (KOA), a leading cause of disability worldwide, is challenging to detect early due to subtle radiographic indicators. Diverse, extensive datasets are needed but are challenging to compile because of privacy, data collection limitations, and the progressive nature of KOA. However, a model capable of projecting genuine radiographs into different OA stages could augment data pools, enhance algorithm training, and offer pre-emptive prognostic insights. In this study, we trained a CycleGAN model to synthesize past and future stages of KOA on any genuine radiograph. The model was validated using a Convolutional Neural Network that was deceived into misclassifying disease stages in transformed images, demonstrating the CycleGAN's ability to effectively transform disease characteristics forward or backward in time. The model was particularly effective in synthesizing future disease states and showed an exceptional ability to retroactively transition late-stage radiographs to earlier stages by eliminating osteophytes and expanding knee joint space, signature characteristics of None or Doubtful KOA. The model's results signify a promising potential for enhancing diagnostic models, data augmentation, and educational and prognostic usage in healthcare. Nevertheless, further refinement, validation, and a broader evaluation process encompassing both CNN-based assessments and expert medical feedback are emphasized for future research and development.
Testing LLMs on Code Generation with Varying Levels of Prompt Specificity
Nov 10, 2023Large language models (LLMs) have demonstrated unparalleled prowess in mimicking human-like text generation and processing. Among the myriad of applications that benefit from LLMs, automated code generation is increasingly promising. The potential to transform natural language prompts into executable code promises a major shift in software development practices and paves the way for significant reductions in manual coding efforts and the likelihood of human-induced errors. This paper reports the results of a study that evaluates the performance of various LLMs, such as Bard, ChatGPT-3.5, ChatGPT-4, and Claude-2, in generating Python for coding problems. We focus on how levels of prompt specificity impact the accuracy, time efficiency, and space efficiency of the generated code. A benchmark of 104 coding problems, each with four types of prompts with varying degrees of tests and specificity, was employed to examine these aspects comprehensively. Our results indicate significant variations in performance across different LLMs and prompt types, and its key contribution is to reveal the ideal prompting strategy for creating accurate Python functions. This study lays the groundwork for further research in LLM capabilities and suggests practical implications for utilizing LLMs in automated code generation tasks and test-driven development.
Online Conversion with Switching Costs: Robust and Learning-Augmented Algorithms
Oct 31, 2023We introduce and study online conversion with switching costs, a family of online problems that capture emerging problems at the intersection of energy and sustainability. In this problem, an online player attempts to purchase (alternatively, sell) fractional shares of an asset during a fixed time horizon with length $T$. At each time step, a cost function (alternatively, price function) is revealed, and the player must irrevocably decide an amount of asset to convert. The player also incurs a switching cost whenever their decision changes in consecutive time steps, i.e., when they increase or decrease their purchasing amount. We introduce competitive (robust) threshold-based algorithms for both the minimization and maximization variants of this problem, and show they are optimal among deterministic online algorithms. We then propose learning-augmented algorithms that take advantage of untrusted black-box advice (such as predictions from a machine learning model) to achieve significantly better average-case performance without sacrificing worst-case competitive guarantees. Finally, we empirically evaluate our proposed algorithms using a carbon-aware EV charging case study, showing that our algorithms substantially improve on baseline methods for this problem.
AR-TTA: A Simple Method for Real-World Continual Test-Time Adaptation
Sep 18, 2023Test-time adaptation is a promising research direction that allows the source model to adapt itself to changes in data distribution without any supervision. Yet, current methods are usually evaluated on benchmarks that are only a simplification of real-world scenarios. Hence, we propose to validate test-time adaptation methods using the recently introduced datasets for autonomous driving, namely CLAD-C and SHIFT. We observe that current test-time adaptation methods struggle to effectively handle varying degrees of domain shift, often resulting in degraded performance that falls below that of the source model. We noticed that the root of the problem lies in the inability to preserve the knowledge of the source model and adapt to dynamically changing, temporally correlated data streams. Therefore, we enhance well-established self-training framework by incorporating a small memory buffer to increase model stability and at the same time perform dynamic adaptation based on the intensity of domain shift. The proposed method, named AR-TTA, outperforms existing approaches on both synthetic and more real-world benchmarks and shows robustness across a variety of TTA scenarios.
Untargeted White-box Adversarial Attack with Heuristic Defence Methods in Real-time Deep Learning based Network Intrusion Detection System
Oct 07, 2023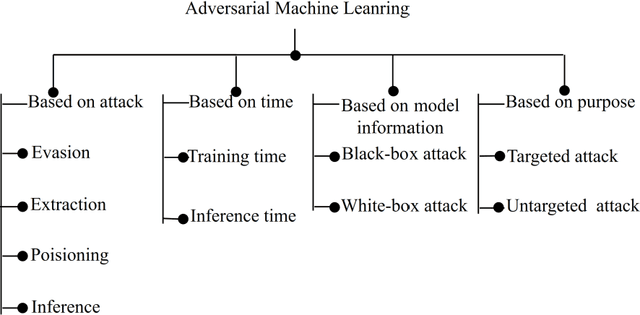

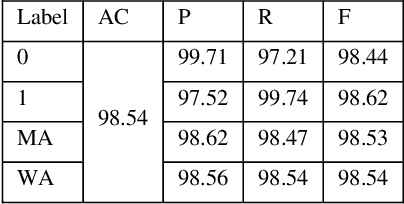
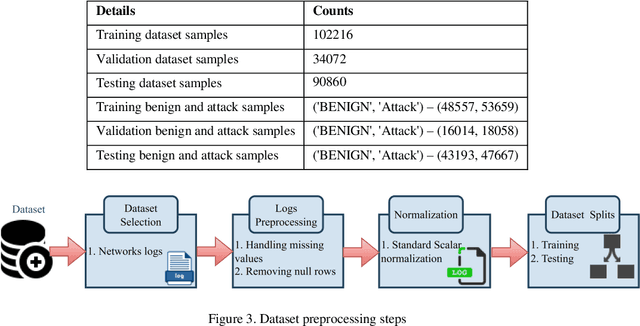
Network Intrusion Detection System (NIDS) is a key component in securing the computer network from various cyber security threats and network attacks. However, consider an unfortunate situation where the NIDS is itself attacked and vulnerable more specifically, we can say, How to defend the defender?. In Adversarial Machine Learning (AML), the malicious actors aim to fool the Machine Learning (ML) and Deep Learning (DL) models to produce incorrect predictions with intentionally crafted adversarial examples. These adversarial perturbed examples have become the biggest vulnerability of ML and DL based systems and are major obstacles to their adoption in real-time and mission-critical applications such as NIDS. AML is an emerging research domain, and it has become a necessity for the in-depth study of adversarial attacks and their defence strategies to safeguard the computer network from various cyber security threads. In this research work, we aim to cover important aspects related to NIDS, adversarial attacks and its defence mechanism to increase the robustness of the ML and DL based NIDS. We implemented four powerful adversarial attack techniques, namely, Fast Gradient Sign Method (FGSM), Jacobian Saliency Map Attack (JSMA), Projected Gradient Descent (PGD) and Carlini & Wagner (C&W) in NIDS. We analyzed its performance in terms of various performance metrics in detail. Furthermore, the three heuristics defence strategies, i.e., Adversarial Training (AT), Gaussian Data Augmentation (GDA) and High Confidence (HC), are implemented to improve the NIDS robustness under adversarial attack situations. The complete workflow is demonstrated in real-time network with data packet flow. This research work provides the overall background for the researchers interested in AML and its implementation from a computer network security point of view.