 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SODAWideNet -- Salient Object Detection with an Attention augmented Wide Encoder Decoder network without ImageNet pre-training
Nov 09, 2023
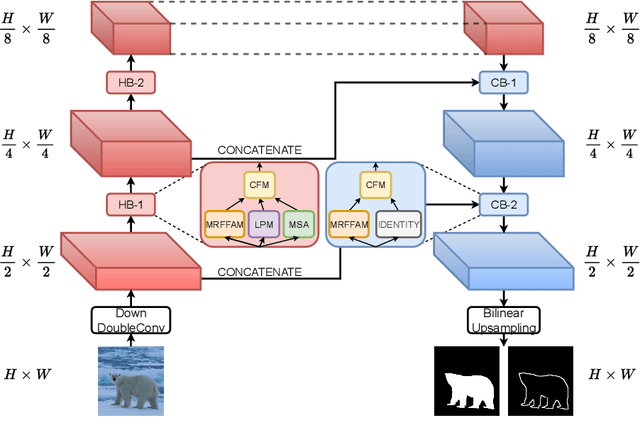

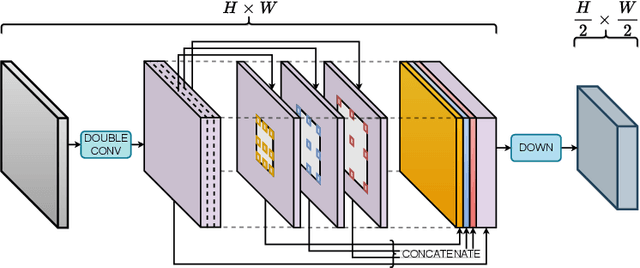
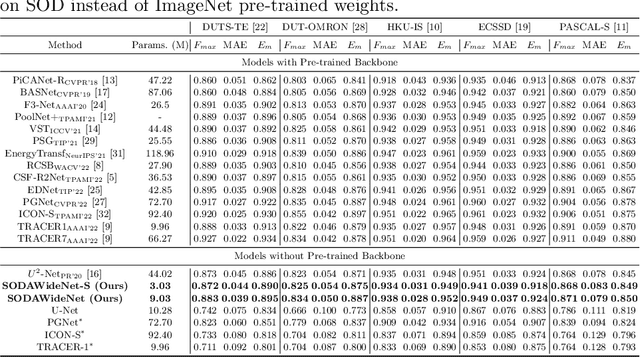
Developing a new Salient Object Detection (SOD) model involves selecting an ImageNet pre-trained backbone and creating novel feature refinement modules to use backbone features. However, adding new components to a pre-trained backbone needs retraining the whole network on the ImageNet dataset, which requires significant time. Hence, we explore developing a neural network from scratch directly trained on SOD without ImageNet pre-training. Such a formulation offers full autonomy to design task-specific components. To that end, we propose SODAWideNet, an encoder-decoder-style network for Salient Object Detection. We deviate from the commonly practiced paradigm of narrow and deep convolutional models to a wide and shallow architecture, resulting in a parameter-efficient deep neural network. To achieve a shallower network, we increase the receptive field from the beginning of the network using a combination of dilated convolutions and self-attention. Therefore, we propose Multi Receptive Field Feature Aggregation Module (MRFFAM) that efficiently obtains discriminative features from farther regions at higher resolutions using dilated convolutions. Next, we propose Multi-Scale Attention (MSA), which creates a feature pyramid and efficiently computes attention across multiple resolutions to extract global features from larger feature maps. Finally, we propose two variants, SODAWideNet-S (3.03M) and SODAWideNet (9.03M), that achieve competitive performance against state-of-the-art models on five datasets.
An Experimental Design for Anytime-Valid Causal Inference on Multi-Armed Bandits
Nov 09, 2023Typically, multi-armed bandit (MAB) experiments are analyzed at the end of the study and thus require the analyst to specify a fixed sample size in advance. However, in many online learning applications, it is advantageous to continuously produce inference on the average treatment effect (ATE) between arms as new data arrive and determine a data-driven stopping time for the experiment. Existing work on continuous inference for adaptive experiments assumes that the treatment assignment probabilities are bounded away from zero and one, thus excluding nearly all standard bandit algorithms. In this work, we develop the Mixture Adaptive Design (MAD), a new experimental design for multi-armed bandits that enables continuous inference on the ATE with guarantees on statistical validity and power for nearly any bandit algorithm. On a high level, the MAD "mixes" a bandit algorithm of the user's choice with a Bernoulli design through a tuning parameter $\delta_t$, where $\delta_t$ is a deterministic sequence that controls the priority placed on the Bernoulli design as the sample size grows. We show that for $\delta_t = o\left(1/t^{1/4}\right)$, the MAD produces a confidence sequence that is asymptotically valid and guaranteed to shrink around the true ATE. We empirically show that the MAD improves the coverage and power of ATE inference in MAB experiments without significant losses in finite-sample reward.
FireMatch: A Semi-Supervised Video Fire Detection Network Based on Consistency and Distribution Alignment
Nov 09, 2023Deep learning techniques have greatly enhanced the performance of fire detection in videos. However, video-based fire detection models heavily rely on labeled data, and the process of data labeling is particularly costly and time-consuming, especially when dealing with videos. Considering the limited quantity of labeled video data, we propose a semi-supervised fire detection model called FireMatch, which is based on consistency regularization and adversarial distribution alignment. Specifically, we first combine consistency regularization with pseudo-label. For unlabeled data, we design video data augmentation to obtain corresponding weakly augmented and strongly augmented samples. The proposed model predicts weakly augmented samples and retains pseudo-label above a threshold, while training on strongly augmented samples to predict these pseudo-labels for learning more robust feature representations. Secondly, we generate video cross-set augmented samples by adversarial distribution alignment to expand the training data and alleviate the decline in classification performance caused by insufficient labeled data. Finally, we introduce a fairness loss to help the model produce diverse predictions for input samples, thereby addressing the issue of high confidence with the non-fire class in fire classification scenarios. The FireMatch achieved an accuracy of 76.92% and 91.81% on two real-world fire datasets, respectively. The experimental results demonstrate that the proposed method outperforms the current state-of-the-art semi-supervised classification methods.
Differentiable Optimization Based Time-Varying Control Barrier Functions for Dynamic Obstacle Avoidance
Sep 29, 2023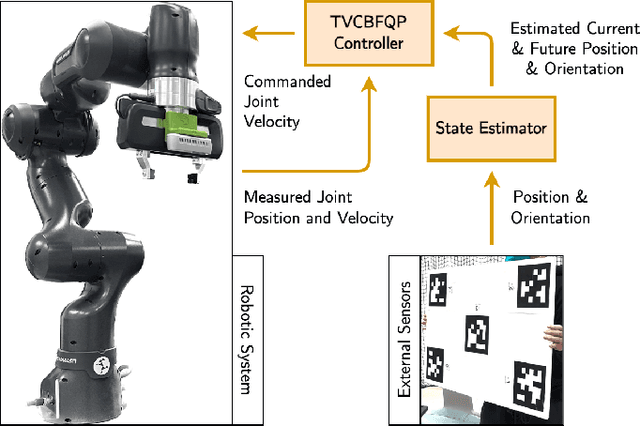
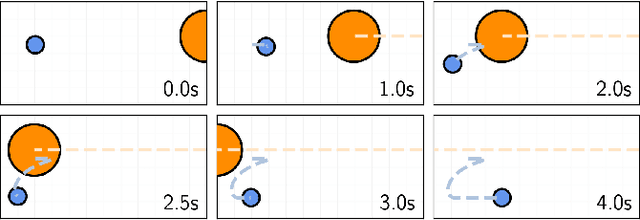
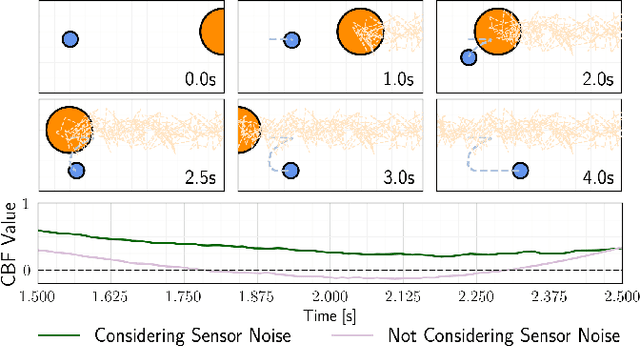
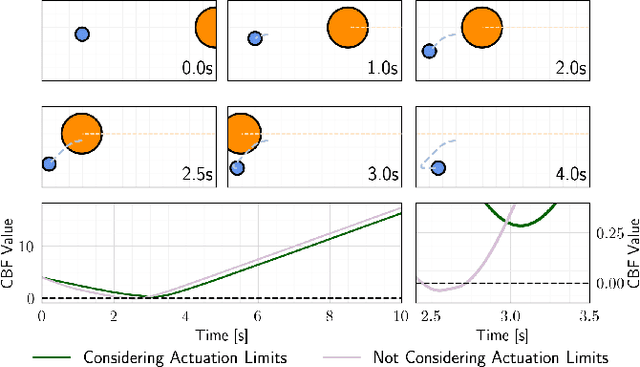
Control barrier functions (CBFs) provide a simple yet effective way for safe control synthesis. Recently, work has been done using differentiable optimization based methods to systematically construct CBFs for static obstacle avoidance tasks between geometric shapes. In this work, we extend the application of differentiable optimization based CBFs to perform dynamic obstacle avoidance tasks. We show that by using the time-varying CBF (TVCBF) formulation, we can perform obstacle avoidance for dynamic geometric obstacles. Additionally, we show how to alter the TVCBF constraint to consider measurement noise and actuation limits. To demonstrate the efficacy of our proposed approach, we first compare its performance with a model predictive control based method on a simulated dynamic obstacle avoidance task with non-ellipsoidal obstacles. Then, we demonstrate the performance of our proposed approach in experimental studies using a 7-degree-of-freedom Franka Research 3 robotic manipulator.
P-ROCKET: Pruning Random Convolution Kernels for Time Series Classification
Sep 15, 2023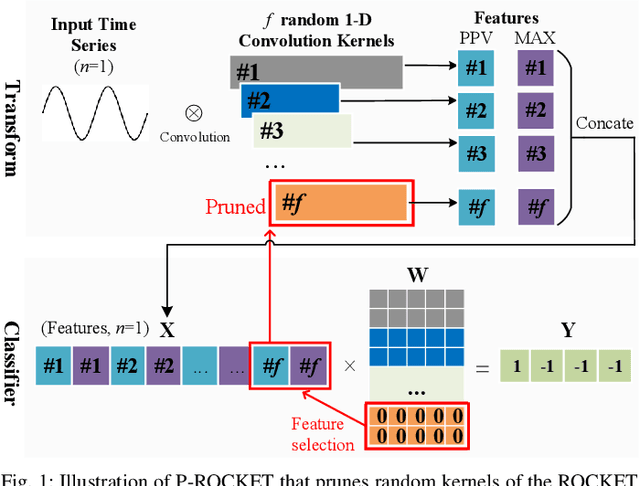
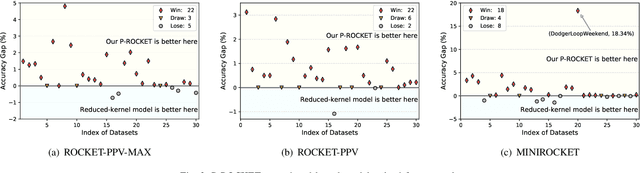
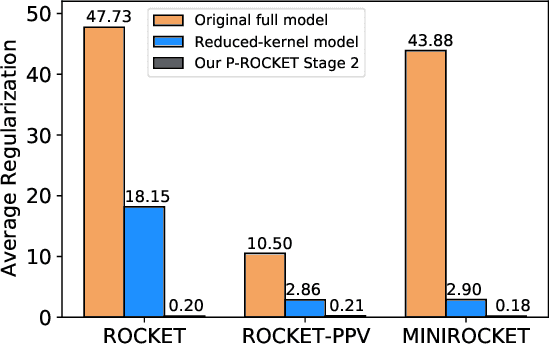
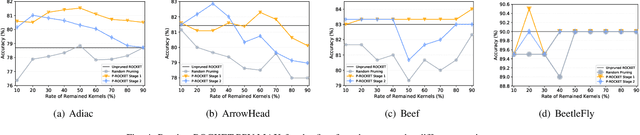
In recent years, two time series classification models, ROCKET and MINIROCKET, have attracted much attention for their low training cost and state-of-the-art accuracy. Utilizing random 1-D convolutional kernels without training, ROCKET and MINIROCKET can rapidly extract features from time series data, allowing for the efficient fitting of linear classifiers. However, to comprehensively capture useful features, a large number of random kernels are required, which is incompatible for resource-constrained devices. Therefore, a heuristic evolutionary algorithm named S-ROCKET is devised to recognize and prune redundant kernels. Nevertheless, the inherent nature of evolutionary algorithms renders the evaluation of kernels within S-ROCKET an unacceptable time-consuming process. In this paper, diverging from S-ROCKET, which directly evaluates random kernels with nonsignificant differences, we remove kernels from a feature selection perspective by eliminating associating connections in the sequential classification layer. To this end, we start by formulating the pruning challenge as a Group Elastic Net classification problem and employ the ADMM method to arrive at a solution. Sequentially, we accelerate the aforementioned time-consuming solving process by bifurcating the $l_{2,1}$ and $l_2$ regularizations into two sequential stages and solve them separately, which ultimately forms our core algorithm, named P-ROCKET. Stage 1 of P-ROCKET employs group-wise regularization similarly to our initial ADMM-based Algorithm, but introduces dynamically varying penalties to greatly accelerate the process. To mitigate overfitting, Stage 2 of P-ROCKET implements element-wise regularization to refit a linear classifier, utilizing the retained features.
Online Signal Estimation on the Graph Edges via Line Graph Transformation
Nov 01, 2023We propose the Line Graph Normalized Least Mean Square (LGNLMS) algorithm for online time-varying graph edge signals prediction. LGNLMS utilizes the Line Graph to transform graph edge signals into the node of its edge-to-vertex dual. This enables edge signals to be processed using established GSP concepts without redefining them on graph edges.
Joint Problems in Learning Multiple Dynamical Systems
Nov 03, 2023Clustering of time series is a well-studied problem, with applications ranging from quantitative, personalized models of metabolism obtained from metabolite concentrations to state discrimination in quantum information theory. We consider a variant, where given a set of trajectories and a number of parts, we jointly partition the set of trajectories and learn linear dynamical system (LDS) models for each part, so as to minimize the maximum error across all the models. We present globally convergent methods and EM heuristics, accompanied by promising computational results.
Understanding and Visualizing Droplet Distributions in Simulations of Shallow Clouds
Oct 31, 2023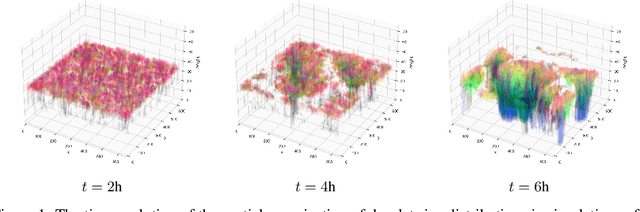
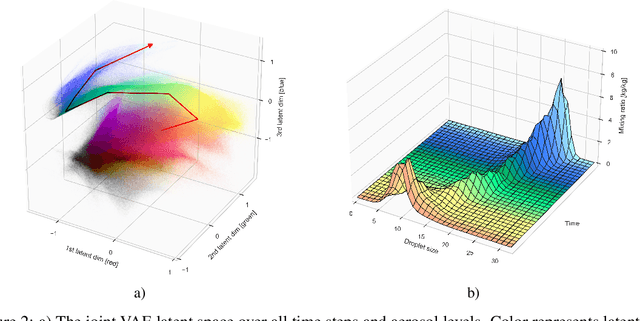
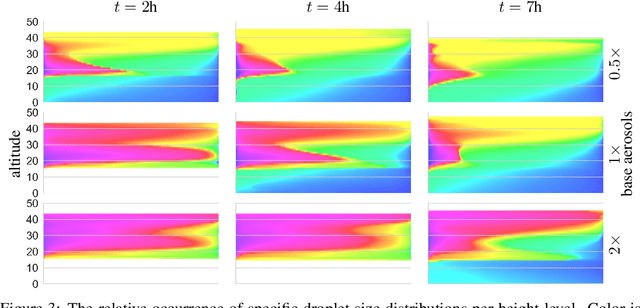
Thorough analysis of local droplet-level interactions is crucial to better understand the microphysical processes in clouds and their effect on the global climate. High-accuracy simulations of relevant droplet size distributions from Large Eddy Simulations (LES) of bin microphysics challenge current analysis techniques due to their high dimensionality involving three spatial dimensions, time, and a continuous range of droplet sizes. Utilizing the compact latent representations from Variational Autoencoders (VAEs), we produce novel and intuitive visualizations for the organization of droplet sizes and their evolution over time beyond what is possible with clustering techniques. This greatly improves interpretation and allows us to examine aerosol-cloud interactions by contrasting simulations with different aerosol concentrations. We find that the evolution of the droplet spectrum is similar across aerosol levels but occurs at different paces. This similarity suggests that precipitation initiation processes are alike despite variations in onset times.
Untargeted White-box Adversarial Attack with Heuristic Defence Methods in Real-time Deep Learning based Network Intrusion Detection System
Oct 05, 2023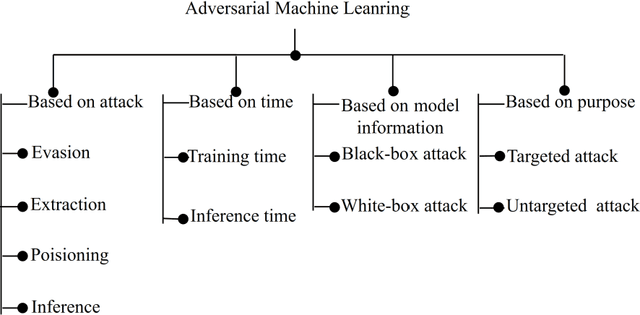

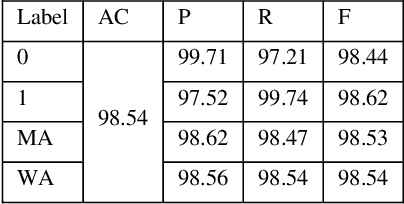
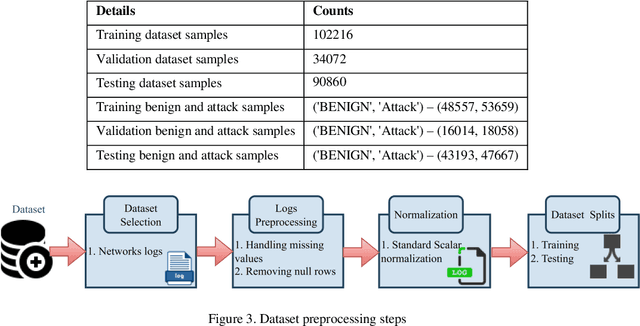
Network Intrusion Detection System (NIDS) is a key component in securing the computer network from various cyber security threats and network attacks. However, consider an unfortunate situation where the NIDS is itself attacked and vulnerable more specifically, we can say, How to defend the defender?. In Adversarial Machine Learning (AML), the malicious actors aim to fool the Machine Learning (ML) and Deep Learning (DL) models to produce incorrect predictions with intentionally crafted adversarial examples. These adversarial perturbed examples have become the biggest vulnerability of ML and DL based systems and are major obstacles to their adoption in real-time and mission-critical applications such as NIDS. AML is an emerging research domain, and it has become a necessity for the in-depth study of adversarial attacks and their defence strategies to safeguard the computer network from various cyber security threads. In this research work, we aim to cover important aspects related to NIDS, adversarial attacks and its defence mechanism to increase the robustness of the ML and DL based NIDS. We implemented four powerful adversarial attack techniques, namely, Fast Gradient Sign Method (FGSM), Jacobian Saliency Map Attack (JSMA), Projected Gradient Descent (PGD) and Carlini & Wagner (C&W) in NIDS. We analyzed its performance in terms of various performance metrics in detail. Furthermore, the three heuristics defence strategies, i.e., Adversarial Training (AT), Gaussian Data Augmentation (GDA) and High Confidence (HC), are implemented to improve the NIDS robustness under adversarial attack situations. The complete workflow is demonstrated in real-time network with data packet flow. This research work provides the overall background for the researchers interested in AML and its implementation from a computer network security point of view.
Contrastive Multi-Modal Representation Learning for Spark Plug Fault Diagnosis
Nov 04, 2023Due to the incapability of one sensory measurement to provide enough information for condition monitoring of some complex engineered industrial mechanisms and also for overcoming the misleading noise of a single sensor, multiple sensors are installed to improve the condition monitoring of some industrial equipment. Therefore, an efficient data fusion strategy is demanded. In this research, we presented a Denoising Multi-Modal Autoencoder with a unique training strategy based on contrastive learning paradigm, both being utilized for the first time in the machine health monitoring realm. The presented approach, which leverages the merits of both supervised and unsupervised learning, not only achieves excellent performance in fusing multiple modalities (or views) of data into an enriched common representation but also takes data fusion to the next level wherein one of the views can be omitted during inference time with very slight performance reduction, or even without any reduction at all. The presented methodology enables multi-modal fault diagnosis systems to perform more robustly in case of sensor failure occurrence, and one can also intentionally omit one of the sensors (the more expensive one) in order to build a more cost-effective condition monitoring system without sacrificing performance for practical purposes. The effectiveness of the presented methodology is examined on a real-world private multi-modal dataset gathered under non-laboratory conditions from a complex engineered mechanism, an inline four-stroke spark-ignition engine, aiming for spark plug fault diagnosis. This dataset, which contains the accelerometer and acoustic signals as two modalities, has a very slight amount of fault, and achieving good performance on such a dataset promises that the presented method can perform well on other equipment as well.