 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraging Large Language Models for Collective Decision-Making
Nov 03, 2023
In various work contexts, such as meeting scheduling, collaborating, and project planning, collective decision-making is essential but often challenging due to diverse individual preferences, varying work focuses, and power dynamics among members. To address this, we propose a system leveraging Large Language Models (LLMs) to facilitate group decision-making by managing conversations and balancing preferences among individuals. Our system extracts individual preferences and suggests options that satisfy a significant portion of the members. We apply this system to corporate meeting scheduling. We create synthetic employee profiles and simulate conversations at scale, leveraging LLMs to evaluate the system. Our results indicate efficient coordination with reduced interactions between members and the LLM-based system. The system also effectively refines proposed options over time, ensuring their quality and equity. Finally, we conduct a survey study involving human participants to assess our system's ability to aggregate preferences and reasoning. Our findings show that the system exhibits strong performance in both dimensions.
DAD++: Improved Data-free Test Time Adversarial Defense
Sep 10, 2023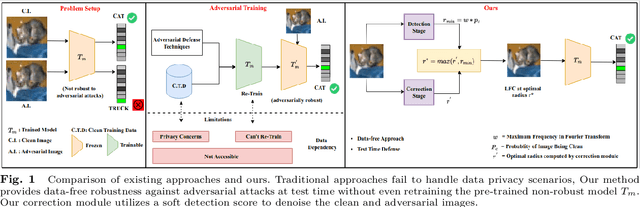
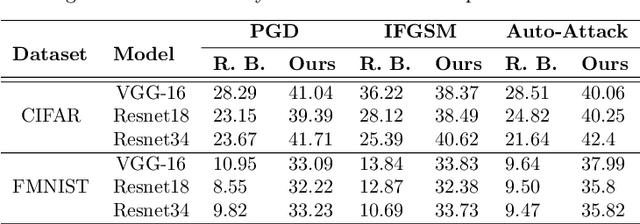
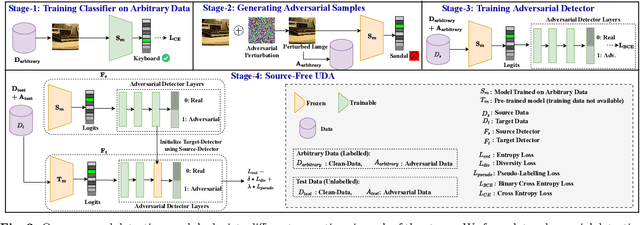

With the increasing deployment of deep neural networks in safety-critical applications such as self-driving cars, medical imaging, anomaly detection, etc., adversarial robustness has become a crucial concern in the reliability of these networks in real-world scenarios. A plethora of works based on adversarial training and regularization-based techniques have been proposed to make these deep networks robust against adversarial attacks. However, these methods require either retraining models or training them from scratch, making them infeasible to defend pre-trained models when access to training data is restricted. To address this problem, we propose a test time Data-free Adversarial Defense (DAD) containing detection and correction frameworks. Moreover, to further improve the efficacy of the correction framework in cases when the detector is under-confident, we propose a soft-detection scheme (dubbed as "DAD++"). We conduct a wide range of experiments and ablations on several datasets and network architectures to show the efficacy of our proposed approach. Furthermore, we demonstrate the applicability of our approach in imparting adversarial defense at test time under data-free (or data-efficient) applications/setups, such as Data-free Knowledge Distillation and Source-free Unsupervised Domain Adaptation, as well as Semi-supervised classification frameworks. We observe that in all the experiments and applications, our DAD++ gives an impressive performance against various adversarial attacks with a minimal drop in clean accuracy. The source code is available at: https://github.com/vcl-iisc/Improved-Data-free-Test-Time-Adversarial-Defense
Memory AMP for Generalized MIMO: Coding Principle and Information-Theoretic Optimality
Nov 07, 2023To support complex communication scenarios in next-generation wireless communications, this paper focuses on a generalized MIMO (GMIMO) with practical assumptions, such as massive antennas, practical channel coding, arbitrary input distributions, and general right-unitarily-invariant channel matrices (covering Rayleigh fading, certain ill-conditioned and correlated channel matrices). The orthogonal/vector approximate message passing (OAMP/VAMP) receiver has been proved to be information-theoretically optimal in GMIMO, but it is limited to high-complexity LMMSE. To solve this problem, a low-complexity memory approximate message passing (MAMP) receiver has recently been shown to be Bayes optimal but limited to uncoded systems. Therefore, how to design a low-complexity and information-theoretically optimal receiver for GMIMO is still an open issue. To address this issue, this paper proposes an information-theoretically optimal MAMP receiver and investigates its achievable rate analysis and optimal coding principle. Specifically, due to the long-memory linear detection, state evolution (SE) for MAMP is intricately multidimensional and cannot be used directly to analyze its achievable rate. To avoid this difficulty, a simplified single-input single-output variational SE (VSE) for MAMP is developed by leveraging the SE fixed-point consistent property of MAMP and OAMP/VAMP. The achievable rate of MAMP is calculated using the VSE, and the optimal coding principle is established to maximize the achievable rate. On this basis, the information-theoretic optimality of MAMP is proved rigorously. Numerical results show that the finite-length performances of MAMP with practical optimized LDPC codes are 0.5-2.7 dB away from the associated constrained capacities. It is worth noting that MAMP can achieve the same performances as OAMP/VAMP with 0.4% of the time consumption for large-scale systems.
Generative Structural Design Integrating BIM and Diffusion Model
Nov 07, 2023Intelligent structural design using AI can effectively reduce time overhead and increase efficiency. It has potential to become the new design paradigm in the future to assist and even replace engineers, and so it has become a research hotspot in the academic community. However, current methods have some limitations to be addressed, whether in terms of application scope, visual quality of generated results, or evaluation metrics of results. This study proposes a comprehensive solution. Firstly, we introduce building information modeling (BIM) into intelligent structural design and establishes a structural design pipeline integrating BIM and generative AI, which is a powerful supplement to the previous frameworks that only considered CAD drawings. In order to improve the perceptual quality and details of generations, this study makes 3 contributions. Firstly, in terms of generation framework, inspired by the process of human drawing, a novel 2-stage generation framework is proposed to replace the traditional end-to-end framework to reduce the generation difficulty for AI models. Secondly, in terms of generative AI tools adopted, diffusion models (DMs) are introduced to replace widely used generative adversarial network (GAN)-based models, and a novel physics-based conditional diffusion model (PCDM) is proposed to consider different design prerequisites. Thirdly, in terms of neural networks, an attention block (AB) consisting of a self-attention block (SAB) and a parallel cross-attention block (PCAB) is designed to facilitate cross-domain data fusion. The quantitative and qualitative results demonstrate the powerful generation and representation capabilities of PCDM. Necessary ablation studies are conducted to examine the validity of the methods. This study also shows that DMs have the potential to replace GANs and become the new benchmark for generative problems in civil engineering.
Watermarks in the Sand: Impossibility of Strong Watermarking for Generative Models
Nov 07, 2023Watermarking generative models consists of planting a statistical signal (watermark) in a model's output so that it can be later verified that the output was generated by the given model. A strong watermarking scheme satisfies the property that a computationally bounded attacker cannot erase the watermark without causing significant quality degradation. In this paper, we study the (im)possibility of strong watermarking schemes. We prove that, under well-specified and natural assumptions, strong watermarking is impossible to achieve. This holds even in the private detection algorithm setting, where the watermark insertion and detection algorithms share a secret key, unknown to the attacker. To prove this result, we introduce a generic efficient watermark attack; the attacker is not required to know the private key of the scheme or even which scheme is used. Our attack is based on two assumptions: (1) The attacker has access to a "quality oracle" that can evaluate whether a candidate output is a high-quality response to a prompt, and (2) The attacker has access to a "perturbation oracle" which can modify an output with a nontrivial probability of maintaining quality, and which induces an efficiently mixing random walk on high-quality outputs. We argue that both assumptions can be satisfied in practice by an attacker with weaker computational capabilities than the watermarked model itself, to which the attacker has only black-box access. Furthermore, our assumptions will likely only be easier to satisfy over time as models grow in capabilities and modalities. We demonstrate the feasibility of our attack by instantiating it to attack three existing watermarking schemes for large language models: Kirchenbauer et al. (2023), Kuditipudi et al. (2023), and Zhao et al. (2023). The same attack successfully removes the watermarks planted by all three schemes, with only minor quality degradation.
Solving MaxSAT with Matrix Multiplication
Nov 01, 2023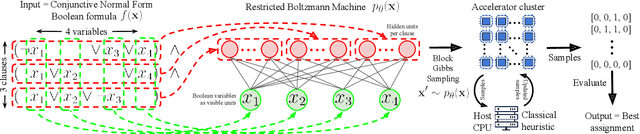
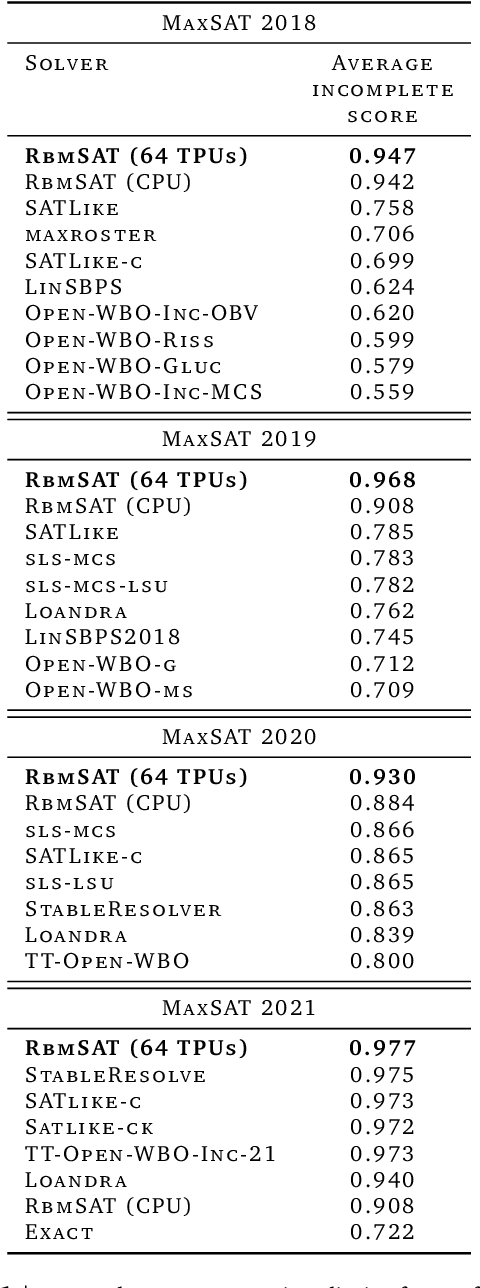
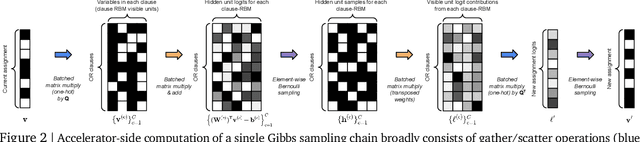
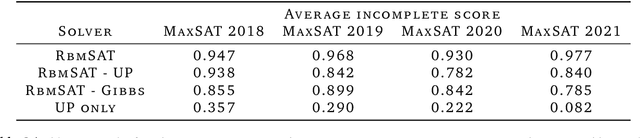
We propose an incomplete algorithm for Maximum Satisfiability (MaxSAT) specifically designed to run on neural network accelerators such as GPUs and TPUs. Given a MaxSAT problem instance in conjunctive normal form, our procedure constructs a Restricted Boltzmann Machine (RBM) with an equilibrium distribution wherein the probability of a Boolean assignment is exponential in the number of clauses it satisfies. Block Gibbs sampling is used to stochastically search the space of assignments with parallel Markov chains. Since matrix multiplication is the main computational primitive for block Gibbs sampling in an RBM, our approach leads to an elegantly simple algorithm (40 lines of JAX) well-suited for neural network accelerators. Theoretical results about RBMs guarantee that the required number of visible and hidden units of the RBM scale only linearly with the number of variables and constant-sized clauses in the MaxSAT instance, ensuring that the computational cost of a Gibbs step scales reasonably with the instance size. Search throughput can be increased by batching parallel chains within a single accelerator as well as by distributing them across multiple accelerators. As a further enhancement, a heuristic based on unit propagation running on CPU is periodically applied to the sampled assignments. Our approach, which we term RbmSAT, is a new design point in the algorithm-hardware co-design space for MaxSAT. We present timed results on a subset of problem instances from the annual MaxSAT Evaluation's Incomplete Unweighted Track for the years 2018 to 2021. When allotted the same running time and CPU compute budget (but no TPUs), RbmSAT outperforms other participating solvers on problems drawn from three out of the four years' competitions. Given the same running time on a TPU cluster for which RbmSAT is uniquely designed, it outperforms all solvers on problems drawn from all four years.
A quantum-classical performance separation in nonconvex optimization
Nov 01, 2023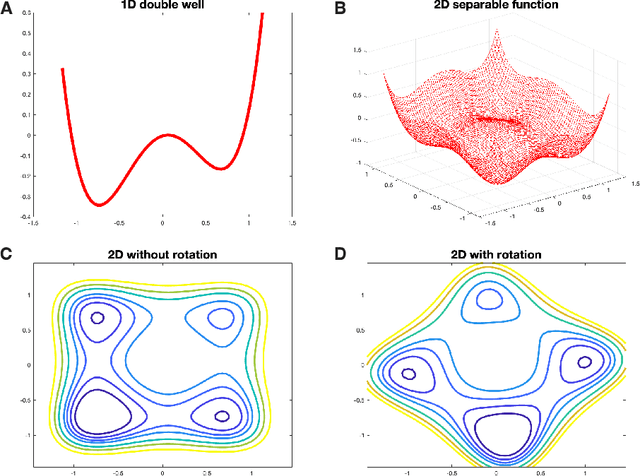
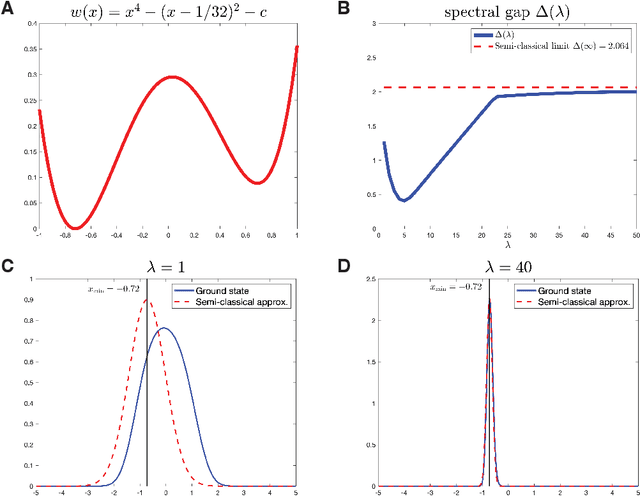
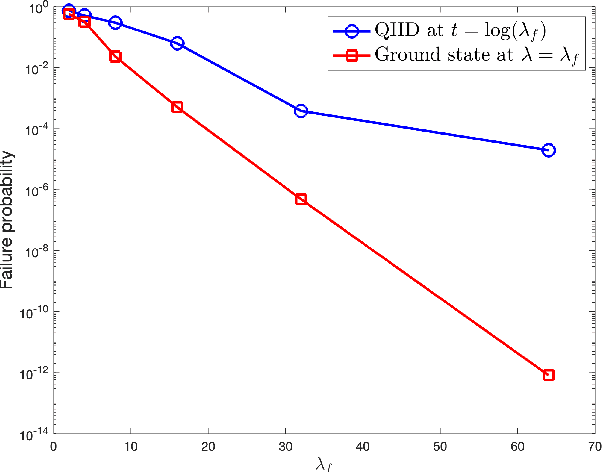
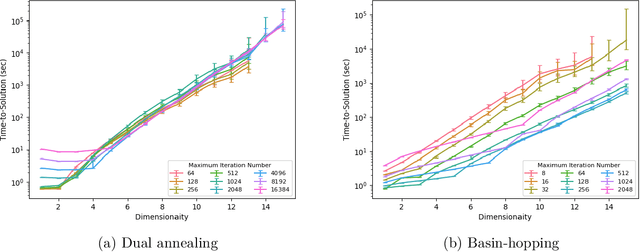
In this paper, we identify a family of nonconvex continuous optimization instances, each $d$-dimensional instance with $2^d$ local minima, to demonstrate a quantum-classical performance separation. Specifically, we prove that the recently proposed Quantum Hamiltonian Descent (QHD) algorithm [Leng et al., arXiv:2303.01471] is able to solve any $d$-dimensional instance from this family using $\widetilde{\mathcal{O}}(d^3)$ quantum queries to the function value and $\widetilde{\mathcal{O}}(d^4)$ additional 1-qubit and 2-qubit elementary quantum gates. On the other side, a comprehensive empirical study suggests that representative state-of-the-art classical optimization algorithms/solvers (including Gurobi) would require a super-polynomial time to solve such optimization instances.
TCGAN: Convolutional Generative Adversarial Network for Time Series Classification and Clustering
Sep 09, 2023Recent works have demonstrated the superiority of supervised Convolutional Neural Networks (CNNs) in learning hierarchical representations from time series data for successful classification. These methods require sufficiently large labeled data for stable learning, however acquiring high-quality labeled time series data can be costly and potentially infeasible. Generative Adversarial Networks (GANs) have achieved great success in enhancing unsupervised and semi-supervised learning. Nonetheless, to our best knowledge, it remains unclear how effectively GANs can serve as a general-purpose solution to learn representations for time series recognition, i.e., classification and clustering. The above considerations inspire us to introduce a Time-series Convolutional GAN (TCGAN). TCGAN learns by playing an adversarial game between two one-dimensional CNNs (i.e., a generator and a discriminator) in the absence of label information. Parts of the trained TCGAN are then reused to construct a representation encoder to empower linear recognition methods. We conducted comprehensive experiments on synthetic and real-world datasets. The results demonstrate that TCGAN is faster and more accurate than existing time-series GANs. The learned representations enable simple classification and clustering methods to achieve superior and stable performance. Furthermore, TCGAN retains high efficacy in scenarios with few-labeled and imbalanced-labeled data. Our work provides a promising path to effectively utilize abundant unlabeled time series data.
DynPoint: Dynamic Neural Point For View Synthesis
Oct 29, 2023The introduction of neural radiance fields has greatly improved the effectiveness of view synthesis for monocular videos. However, existing algorithms face difficulties when dealing with uncontrolled or lengthy scenarios, and require extensive training time specific to each new scenario. To tackle these limitations, we propose DynPoint, an algorithm designed to facilitate the rapid synthesis of novel views for unconstrained monocular videos. Rather than encoding the entirety of the scenario information into a latent representation, DynPoint concentrates on predicting the explicit 3D correspondence between neighboring frames to realize information aggregation. Specifically, this correspondence prediction is achieved through the estimation of consistent depth and scene flow information across frames. Subsequently, the acquired correspondence is utilized to aggregate information from multiple reference frames to a target frame, by constructing hierarchical neural point clouds. The resulting framework enables swift and accurate view synthesis for desired views of target frames. The experimental results obtained demonstrate the considerable acceleration of training time achieved - typically an order of magnitude - by our proposed method while yielding comparable outcomes compared to prior approaches. Furthermore, our method exhibits strong robustness in handling long-duration videos without learning a canonical representation of video content.
Muscle volume quantification: guiding transformers with anatomical priors
Oct 31, 2023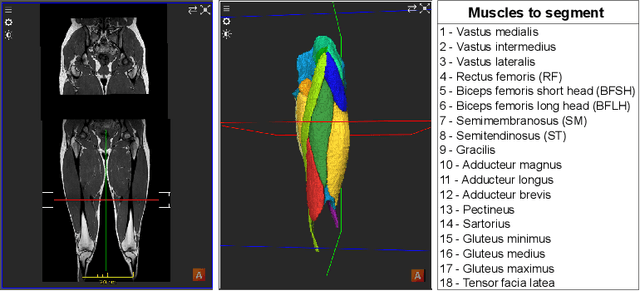
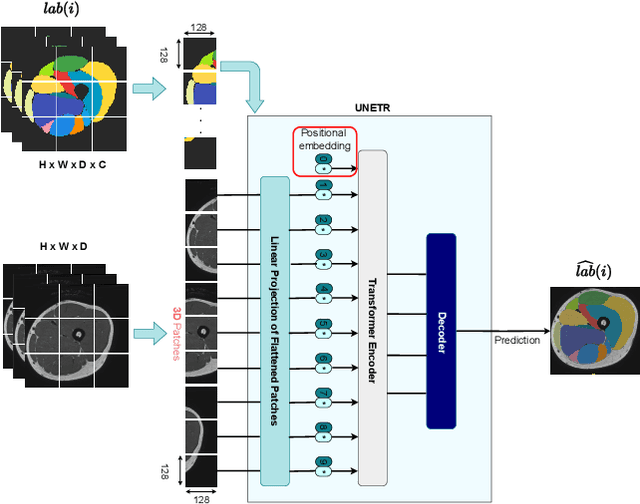
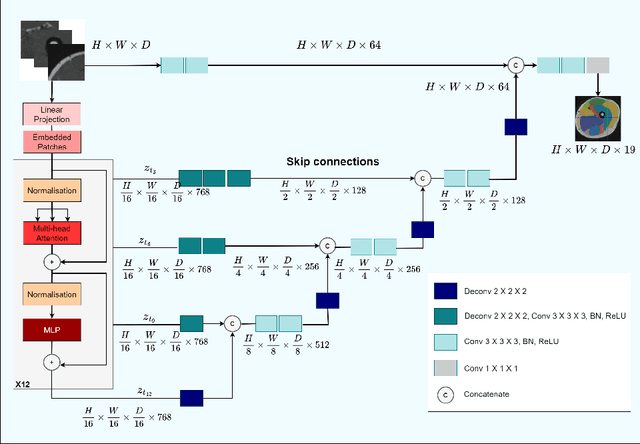
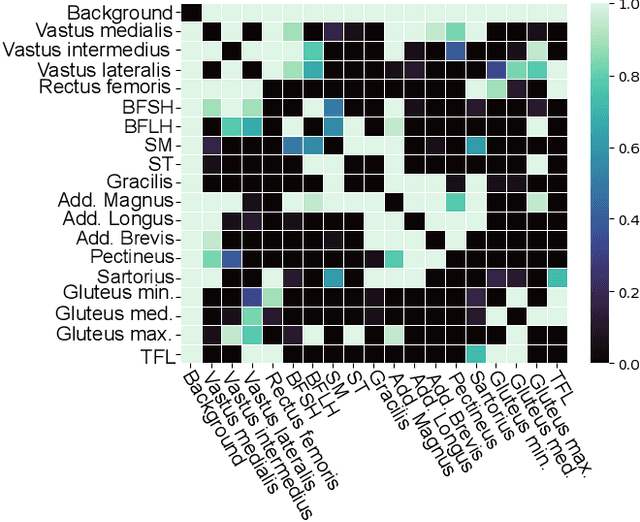
Muscle volume is a useful quantitative biomarker in sports, but also for the follow-up of degenerative musculo-skelletal diseases. In addition to volume, other shape biomarkers can be extracted by segmenting the muscles of interest from medical images. Manual segmentation is still today the gold standard for such measurements despite being very time-consuming. We propose a method for automatic segmentation of 18 muscles of the lower limb on 3D Magnetic Resonance Images to assist such morphometric analysis. By their nature, the tissue of different muscles is undistinguishable when observed in MR Images. Thus, muscle segmentation algorithms cannot rely on appearance but only on contour cues. However, such contours are hard to detect and their thickness varies across subjects. To cope with the above challenges, we propose a segmentation approach based on a hybrid architecture, combining convolutional and visual transformer blocks. We investigate for the first time the behaviour of such hybrid architectures in the context of muscle segmentation for shape analysis. Considering the consistent anatomical muscle configuration, we rely on transformer blocks to capture the longrange relations between the muscles. To further exploit the anatomical priors, a second contribution of this work consists in adding a regularisation loss based on an adjacency matrix of plausible muscle neighbourhoods estimated from the training data. Our experimental results on a unique database of elite athletes show it is possible to train complex hybrid models from a relatively small database of large volumes, while the anatomical prior regularisation favours better predictions.