 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MuSHRoom: Multi-Sensor Hybrid Room Dataset for Joint 3D Reconstruction and Novel View Synthesis
Nov 05, 2023
Metaverse technologies demand accurate, real-time, and immersive modeling on consumer-grade hardware for both non-human perception (e.g., drone/robot/autonomous car navigation) and immersive technologies like AR/VR, requiring both structural accuracy and photorealism. However, there exists a knowledge gap in how to apply geometric reconstruction and photorealism modeling (novel view synthesis) in a unified framework. To address this gap and promote the development of robust and immersive modeling and rendering with consumer-grade devices, first, we propose a real-world Multi-Sensor Hybrid Room Dataset (MuSHRoom). Our dataset presents exciting challenges and requires state-of-the-art methods to be cost-effective, robust to noisy data and devices, and can jointly learn 3D reconstruction and novel view synthesis, instead of treating them as separate tasks, making them ideal for real-world applications. Second, we benchmark several famous pipelines on our dataset for joint 3D mesh reconstruction and novel view synthesis. Finally, in order to further improve the overall performance, we propose a new method that achieves a good trade-off between the two tasks. Our dataset and benchmark show great potential in promoting the improvements for fusing 3D reconstruction and high-quality rendering in a robust and computationally efficient end-to-end fashion.
FloodBrain: Flood Disaster Reporting by Web-based Retrieval Augmented Generation with an LLM
Nov 05, 2023


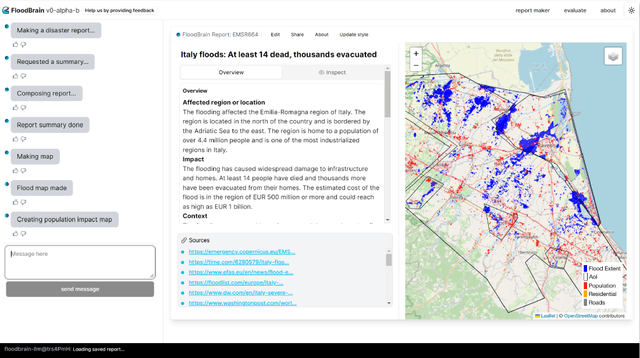
Fast disaster impact reporting is crucial in planning humanitarian assistance. Large Language Models (LLMs) are well known for their ability to write coherent text and fulfill a variety of tasks relevant to impact reporting, such as question answering or text summarization. However, LLMs are constrained by the knowledge within their training data and are prone to generating inaccurate, or "hallucinated", information. To address this, we introduce a sophisticated pipeline embodied in our tool FloodBrain (floodbrain.com), specialized in generating flood disaster impact reports by extracting and curating information from the web. Our pipeline assimilates information from web search results to produce detailed and accurate reports on flood events. We test different LLMs as backbones in our tool and compare their generated reports to human-written reports on different metrics. Similar to other studies, we find a notable correlation between the scores assigned by GPT-4 and the scores given by human evaluators when comparing our generated reports to human-authored ones. Additionally, we conduct an ablation study to test our single pipeline components and their relevancy for the final reports. With our tool, we aim to advance the use of LLMs for disaster impact reporting and reduce the time for coordination of humanitarian efforts in the wake of flood disasters.
Towards Generic Anomaly Detection and Understanding: Large-scale Visual-linguistic Model (GPT-4V) Takes the Lead
Nov 05, 2023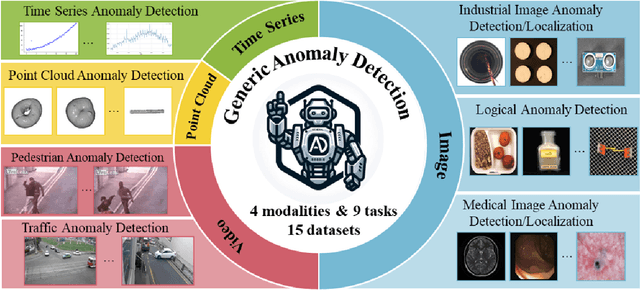
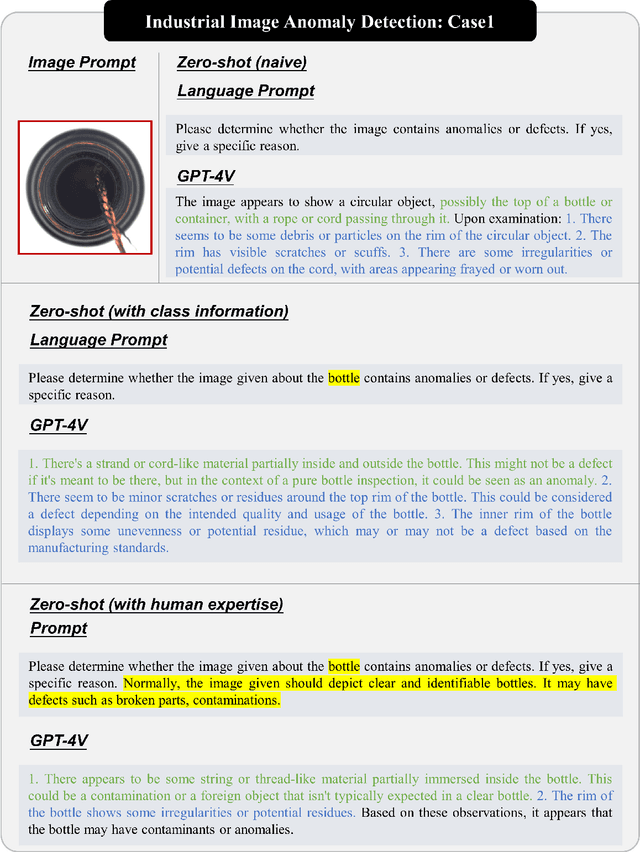

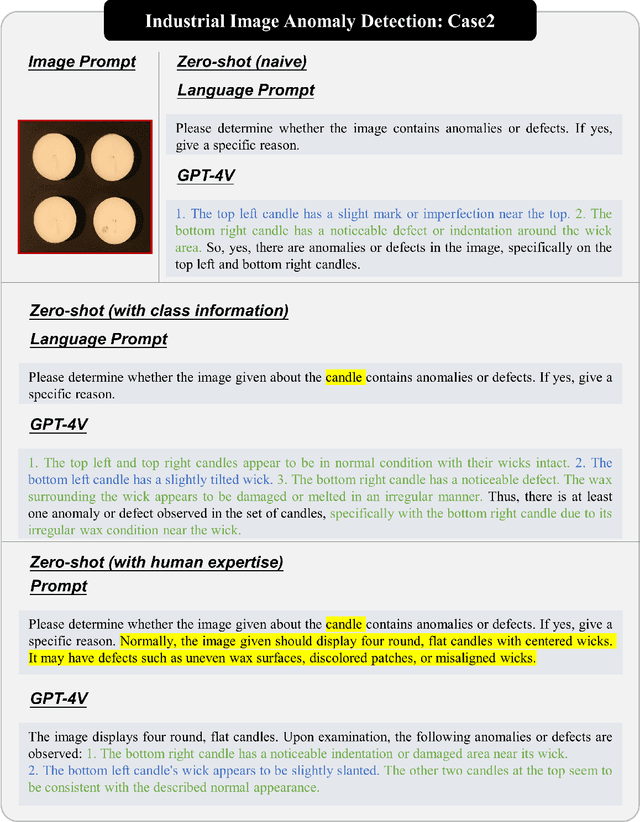
Anomaly detection is a crucial task across different domains and data types. However, existing anomaly detection models are often designed for specific domains and modalities. This study explores the use of GPT-4V(ision), a powerful visual-linguistic model, to address anomaly detection tasks in a generic manner. We investigate the application of GPT-4V in multi-modality, multi-domain anomaly detection tasks, including image, video, point cloud, and time series data, across multiple application areas, such as industrial, medical, logical, video, 3D anomaly detection, and localization tasks. To enhance GPT-4V's performance, we incorporate different kinds of additional cues such as class information, human expertise, and reference images as prompts.Based on our experiments, GPT-4V proves to be highly effective in detecting and explaining global and fine-grained semantic patterns in zero/one-shot anomaly detection. This enables accurate differentiation between normal and abnormal instances. Although we conducted extensive evaluations in this study, there is still room for future evaluation to further exploit GPT-4V's generic anomaly detection capacity from different aspects. These include exploring quantitative metrics, expanding evaluation benchmarks, incorporating multi-round interactions, and incorporating human feedback loops. Nevertheless, GPT-4V exhibits promising performance in generic anomaly detection and understanding, thus opening up a new avenue for anomaly detection.
An Approach for Efficient Neural Architecture Search Space Definition
Oct 25, 2023As we advance in the fast-growing era of Machine Learning, various new and more complex neural architectures are arising to tackle problem more efficiently. On the one hand their efficient usage requires advanced knowledge and expertise, which is most of the time difficult to find on the labor market. On the other hand, searching for an optimized neural architecture is a time-consuming task when it is performed manually using a trial and error approach. Hence, a method and a tool support is needed to assist users of neural architectures, leading to an eagerness in the field of Automatic Machine Learning (AutoML). When it comes to Deep Learning, an important part of AutoML is the Neural Architecture Search (NAS). In this paper, we propose a novel cell-based hierarchical search space, easy to comprehend and manipulate. The objectives of the proposed approach are to optimize the search-time and to be general enough to handle most of state of the art Convolutional Neural Networks (CNN) architectures.
Towards Streaming Speech-to-Avatar Synthesis
Oct 25, 2023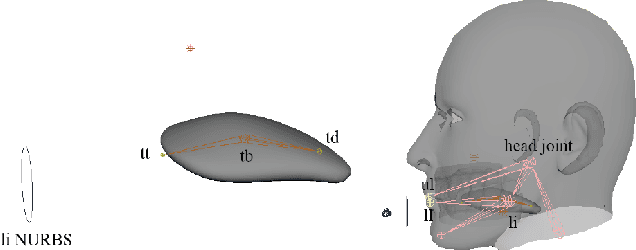
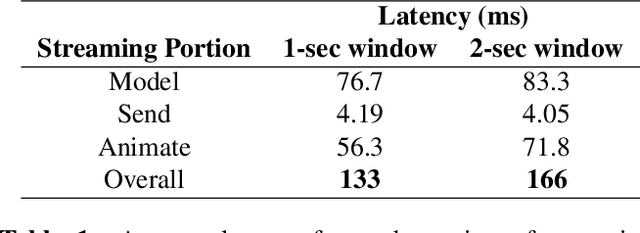
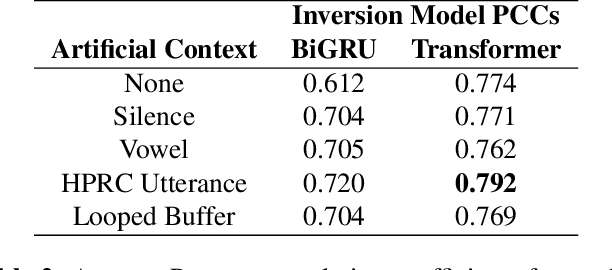

Streaming speech-to-avatar synthesis creates real-time animations for a virtual character from audio data. Accurate avatar representations of speech are important for the visualization of sound in linguistics, phonetics, and phonology, visual feedback to assist second language acquisition, and virtual embodiment for paralyzed patients. Previous works have highlighted the capability of deep articulatory inversion to perform high-quality avatar animation using electromagnetic articulography (EMA) features. However, these models focus on offline avatar synthesis with recordings rather than real-time audio, which is necessary for live avatar visualization or embodiment. To address this issue, we propose a method using articulatory inversion for streaming high quality facial and inner-mouth avatar animation from real-time audio. Our approach achieves 130ms average streaming latency for every 0.1 seconds of audio with a 0.792 correlation with ground truth articulations. Finally, we show generated mouth and tongue animations to demonstrate the efficacy of our methodology.
Modelling Irregularly Sampled Time Series Without Imputation
Sep 15, 2023Modelling irregularly-sampled time series (ISTS) is challenging because of missing values. Most existing methods focus on handling ISTS by converting irregularly sampled data into regularly sampled data via imputation. These models assume an underlying missing mechanism leading to unwanted bias and sub-optimal performance. We present SLAN (Switch LSTM Aggregate Network), which utilizes a pack of LSTMs to model ISTS without imputation, eliminating the assumption of any underlying process. It dynamically adapts its architecture on the fly based on the measured sensors. SLAN exploits the irregularity information to capture each sensor's local summary explicitly and maintains a global summary state throughout the observational period. We demonstrate the efficacy of SLAN on publicly available datasets, namely, MIMIC-III, Physionet 2012 and Physionet 2019. The code is available at https://github.com/Rohit102497/SLAN.
Deep Reinforcement Learning-based Intelligent Traffic Signal Controls with Optimized CO2 emissions
Oct 23, 2023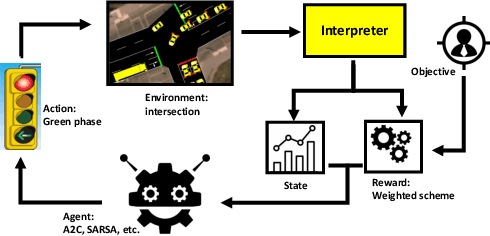
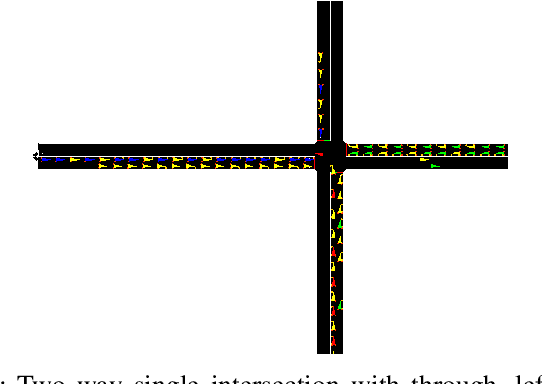
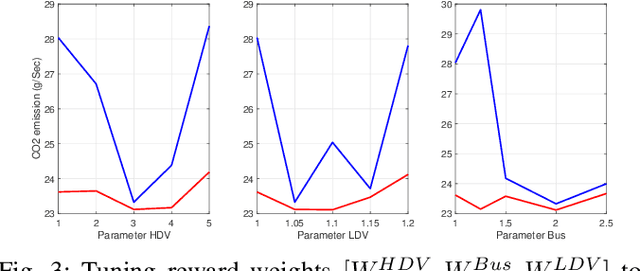
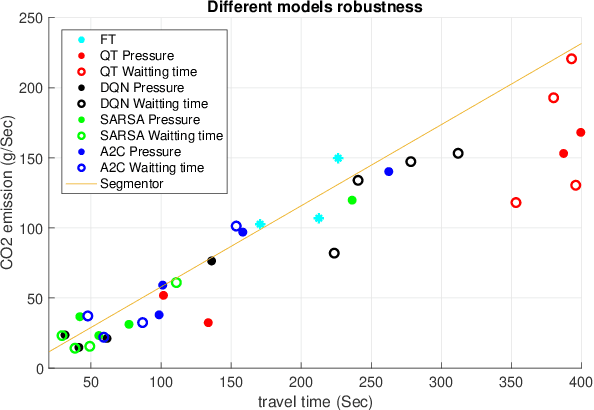
Nowadays, transportation networks face the challenge of sub-optimal control policies that can have adverse effects on human health, the environment, and contribute to traffic congestion. Increased levels of air pollution and extended commute times caused by traffic bottlenecks make intersection traffic signal controllers a crucial component of modern transportation infrastructure. Despite several adaptive traffic signal controllers in literature, limited research has been conducted on their comparative performance. Furthermore, despite carbon dioxide (CO2) emissions' significance as a global issue, the literature has paid limited attention to this area. In this report, we propose EcoLight, a reward shaping scheme for reinforcement learning algorithms that not only reduces CO2 emissions but also achieves competitive results in metrics such as travel time. We compare the performance of tabular Q-Learning, DQN, SARSA, and A2C algorithms using metrics such as travel time, CO2 emissions, waiting time, and stopped time. Our evaluation considers multiple scenarios that encompass a range of road users (trucks, buses, cars) with varying pollution levels.
DySurv: Dynamic Deep Learning Model for Survival Prediction in the ICU
Oct 28, 2023Survival analysis helps approximate underlying distributions of time-to-events which in the case of critical care like in the ICU can be a powerful tool for dynamic mortality risk prediction. Extending beyond the classical Cox model, deep learning techniques have been leveraged over the last years relaxing the many constraints of their counterparts from statistical methods. In this work, we propose a novel conditional variational autoencoder-based method called DySurv which uses a combination of static and time-series measurements from patient electronic health records in estimating risk of death dynamically in the ICU. DySurv has been tested on standard benchmarks where it outperforms most existing methods including other deep learning methods and we evaluate it on a real-world patient database from MIMIC-IV. The predictive capacity of DySurv is consistent and the survival estimates remain disentangled across different datasets supporting the idea that dynamic deep learning models based on conditional variational inference in multi-task cases can be robust models for survival analysis.
DAD++: Improved Data-free Test Time Adversarial Defense
Sep 10, 2023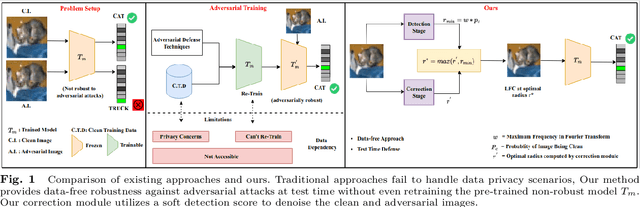
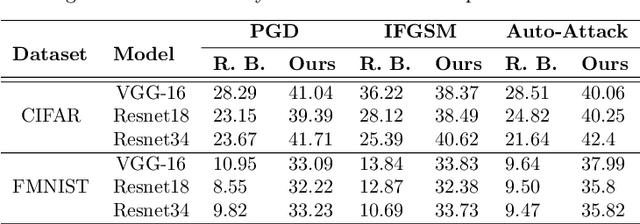
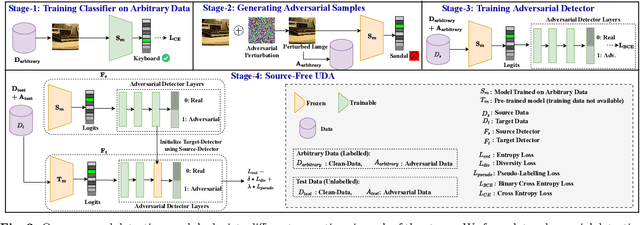

With the increasing deployment of deep neural networks in safety-critical applications such as self-driving cars, medical imaging, anomaly detection, etc., adversarial robustness has become a crucial concern in the reliability of these networks in real-world scenarios. A plethora of works based on adversarial training and regularization-based techniques have been proposed to make these deep networks robust against adversarial attacks. However, these methods require either retraining models or training them from scratch, making them infeasible to defend pre-trained models when access to training data is restricted. To address this problem, we propose a test time Data-free Adversarial Defense (DAD) containing detection and correction frameworks. Moreover, to further improve the efficacy of the correction framework in cases when the detector is under-confident, we propose a soft-detection scheme (dubbed as "DAD++"). We conduct a wide range of experiments and ablations on several datasets and network architectures to show the efficacy of our proposed approach. Furthermore, we demonstrate the applicability of our approach in imparting adversarial defense at test time under data-free (or data-efficient) applications/setups, such as Data-free Knowledge Distillation and Source-free Unsupervised Domain Adaptation, as well as Semi-supervised classification frameworks. We observe that in all the experiments and applications, our DAD++ gives an impressive performance against various adversarial attacks with a minimal drop in clean accuracy. The source code is available at: https://github.com/vcl-iisc/Improved-Data-free-Test-Time-Adversarial-Defense
Vicinal Risk Minimization for Few-Shot Cross-lingual Transfer in Abusive Language Detection
Nov 03, 2023Cross-lingual transfer learning from high-resource to medium and low-resource languages has shown encouraging results. However, the scarcity of resources in target languages remains a challenge. In this work, we resort to data augmentation and continual pre-training for domain adaptation to improve cross-lingual abusive language detection. For data augmentation, we analyze two existing techniques based on vicinal risk minimization and propose MIXAG, a novel data augmentation method which interpolates pairs of instances based on the angle of their representations. Our experiments involve seven languages typologically distinct from English and three different domains. The results reveal that the data augmentation strategies can enhance few-shot cross-lingual abusive language detection. Specifically, we observe that consistently in all target languages, MIXAG improves significantly in multidomain and multilingual environments. Finally, we show through an error analysis how the domain adaptation can favour the class of abusive texts (reducing false negatives), but at the same time, declines the precision of the abusive language detection model.