 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semantic-aware Sampling and Transmission in Energy Harvesting Systems: A POMDP Approach
Nov 11, 2023
We study real-time tracking problem in an energy harvesting system with a Markov source under an imperfect channel. We consider both sampling and transmission costs and different from most prior studies that assume the source is fully observable, the sampling cost renders the source unobservable. The goal is to jointly optimize sampling and transmission policies for three semantic-aware metrics: i) the age of information (AoI), ii) general distortion, and iii) the age of incorrect information (AoII). To this end, we formulate and solve a stochastic control problem. Specifically, for the AoI metric, we cast a Markov decision process (MDP) problem and solve it using relative value iteration (RVI). For the distortion and AoII metrics, we utilize the partially observable MDP (POMDP) modeling and leverage the notion of belief MDP formulation of POMDP to find optimal policies. For the distortion metric and the AoII metric under the perfect channel setup, we effectively truncate the corresponding belief space and solve an MDP problem using RVI. For the general setup, a deep reinforcement learning policy is proposed. Through simulations, we demonstrate significant performance improvements achieved by the derived policies. The results reveal various switching-type structures of optimal policies and show that a distortion-optimal policy is also AoII optimal.
What User Behaviors Make the Differences During the Process of Visual Analytics?
Nov 01, 2023The understanding of visual analytics process can benefit visualization researchers from multiple aspects, including improving visual designs and developing advanced interaction functions. However, the log files of user behaviors are still hard to analyze due to the complexity of sensemaking and our lack of knowledge on the related user behaviors. This work presents a study on a comprehensive data collection of user behaviors, and our analysis approach with time-series classification methods. We have chosen a classical visualization application, Covid-19 data analysis, with common analysis tasks covering geo-spatial, time-series and multi-attributes. Our user study collects user behaviors on a diverse set of visualization tasks with two comparable systems, desktop and immersive visualizations. We summarize the classification results with three time-series machine learning algorithms at two scales, and explore the influences of behavior features. Our results reveal that user behaviors can be distinguished during the process of visual analytics and there is a potentially strong association between the physical behaviors of users and the visualization tasks they perform. We also demonstrate the usage of our models by interpreting open sessions of visual analytics, which provides an automatic way to study sensemaking without tedious manual annotations.
Topological Learning for Motion Data via Mixed Coordinates
Oct 30, 2023Topology can extract the structural information in a dataset efficiently. In this paper, we attempt to incorporate topological information into a multiple output Gaussian process model for transfer learning purposes. To achieve this goal, we extend the framework of circular coordinates into a novel framework of mixed valued coordinates to take linear trends in the time series into consideration. One of the major challenges to learn from multiple time series effectively via a multiple output Gaussian process model is constructing a functional kernel. We propose to use topologically induced clustering to construct a cluster based kernel in a multiple output Gaussian process model. This kernel not only incorporates the topological structural information, but also allows us to put forward a unified framework using topological information in time and motion series.
* 7 pages, 4 figures
Information-Theoretic Generalization Bounds for Transductive Learning and its Applications
Nov 08, 2023In this paper, we develop data-dependent and algorithm-dependent generalization bounds for transductive learning algorithms in the context of information theory for the first time. We show that the generalization gap of transductive learning algorithms can be bounded by the mutual information between training labels and hypothesis. By innovatively proposing the concept of transductive supersamples, we go beyond the inductive learning setting and establish upper bounds in terms of various information measures. Furthermore, we derive novel PAC-Bayesian bounds and build the connection between generalization and loss landscape flatness under the transductive learning setting. Finally, we present the upper bounds for adaptive optimization algorithms and demonstrate the applications of results on semi-supervised learning and graph learning scenarios. Our theoretic results are validated on both synthetic and real-world datasets.
ForecastPFN: Synthetically-Trained Zero-Shot Forecasting
Nov 03, 2023The vast majority of time-series forecasting approaches require a substantial training dataset. However, many real-life forecasting applications have very little initial observations, sometimes just 40 or fewer. Thus, the applicability of most forecasting methods is restricted in data-sparse commercial applications. While there is recent work in the setting of very limited initial data (so-called `zero-shot' forecasting), its performance is inconsistent depending on the data used for pretraining. In this work, we take a different approach and devise ForecastPFN, the first zero-shot forecasting model trained purely on a novel synthetic data distribution. ForecastPFN is a prior-data fitted network, trained to approximate Bayesian inference, which can make predictions on a new time series dataset in a single forward pass. Through extensive experiments, we show that zero-shot predictions made by ForecastPFN are more accurate and faster compared to state-of-the-art forecasting methods, even when the other methods are allowed to train on hundreds of additional in-distribution data points.
Continuous-time control synthesis under nested signal temporal logic specifications
Sep 17, 2023Signal temporal logic (STL) has gained popularity in robotics for expressing complex specifications that may involve timing requirements or deadlines. While the control synthesis for STL specifications without nested temporal operators has been studied in the literature, the case of nested temporal operators is substantially more challenging and requires new theoretical advancements. In this work, we propose an efficient continuous-time control synthesis framework for nonlinear systems under nested STL specifications. The framework is based on the notions of signal temporal logic tree (sTLT) and control barrier function (CBF). In particular, we detail the construction of an sTLT from a given STL formula and a continuous-time dynamical system, the sTLT semantics (i.e., satisfaction condition), and the equivalence or under-approximation relation between sTLT and STL. Leveraging the fact that the satisfaction condition of an sTLT is essentially keeping the state within certain sets during certain time intervals, it provides explicit guidelines for the CBF design. The resulting controller is obtained through the utilization of an online CBF-based program coupled with an event-triggered scheme for online updating the activation time interval of each CBF, with which the correctness of the system behavior can be established by construction. We demonstrate the efficacy of the proposed method for single-integrator and unicycle models under nested STL formulas.
Towards Real-World Test-Time Adaptation: Tri-Net Self-Training with Balanced Normalization
Sep 26, 2023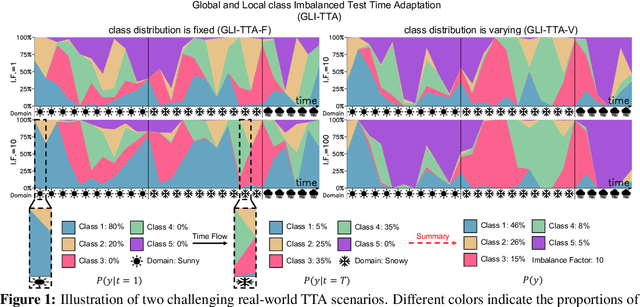
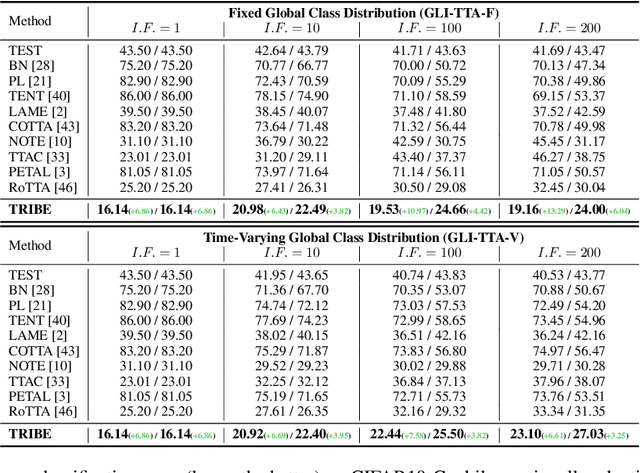
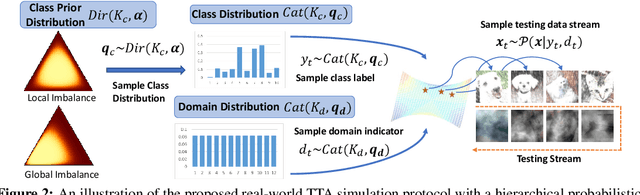
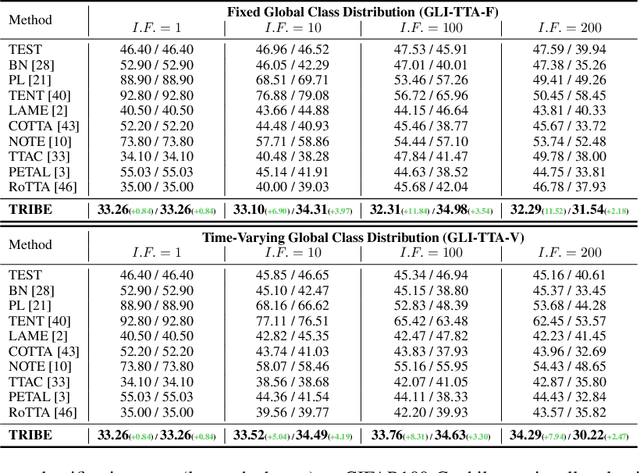
Test-Time Adaptation aims to adapt source domain model to testing data at inference stage with success demonstrated in adapting to unseen corruptions. However, these attempts may fail under more challenging real-world scenarios. Existing works mainly consider real-world test-time adaptation under non-i.i.d. data stream and continual domain shift. In this work, we first complement the existing real-world TTA protocol with a globally class imbalanced testing set. We demonstrate that combining all settings together poses new challenges to existing methods. We argue the failure of state-of-the-art methods is first caused by indiscriminately adapting normalization layers to imbalanced testing data. To remedy this shortcoming, we propose a balanced batchnorm layer to swap out the regular batchnorm at inference stage. The new batchnorm layer is capable of adapting without biasing towards majority classes. We are further inspired by the success of self-training~(ST) in learning from unlabeled data and adapt ST for test-time adaptation. However, ST alone is prone to over adaption which is responsible for the poor performance under continual domain shift. Hence, we propose to improve self-training under continual domain shift by regularizing model updates with an anchored loss. The final TTA model, termed as TRIBE, is built upon a tri-net architecture with balanced batchnorm layers. We evaluate TRIBE on four datasets representing real-world TTA settings. TRIBE consistently achieves the state-of-the-art performance across multiple evaluation protocols. The code is available at \url{https://github.com/Gorilla-Lab-SCUT/TRIBE}.
Green Resilience of Cyber-Physical Systems
Nov 09, 2023Cyber-Physical System (CPS) represents systems that join both hardware and software components to perform real-time services. Maintaining the system's reliability is critical to the continuous delivery of these services. However, the CPS running environment is full of uncertainties and can easily lead to performance degradation. As a result, the need for a recovery technique is highly needed to achieve resilience in the system, with keeping in mind that this technique should be as green as possible. This early doctorate proposal, suggests a game theory solution to achieve resilience and green in CPS. Game theory has been known for its fast performance in decision-making, helping the system to choose what maximizes its payoffs. The proposed game model is described over a real-life collaborative artificial intelligence system (CAIS), that involves robots with humans to achieve a common goal. It shows how the expected results of the system will achieve the resilience of CAIS with minimized CO2 footprint.
Sorting Out Quantum Monte Carlo
Nov 09, 2023Molecular modeling at the quantum level requires choosing a parameterization of the wavefunction that both respects the required particle symmetries, and is scalable to systems of many particles. For the simulation of fermions, valid parameterizations must be antisymmetric with respect to the exchange of particles. Typically, antisymmetry is enforced by leveraging the anti-symmetry of determinants with respect to the exchange of matrix rows, but this involves computing a full determinant each time the wavefunction is evaluated. Instead, we introduce a new antisymmetrization layer derived from sorting, the $\textit{sortlet}$, which scales as $O(N \log N)$ with regards to the number of particles -- in contrast to $O(N^3)$ for the determinant. We show numerically that applying this anti-symmeterization layer on top of an attention based neural-network backbone yields a flexible wavefunction parameterization capable of reaching chemical accuracy when approximating the ground state of first-row atoms and small molecules.
Deep Learning-Based Real-Time Rate Control for Live Streaming on Wireless Networks
Sep 27, 2023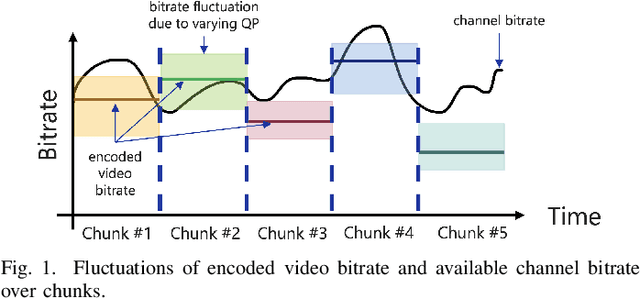
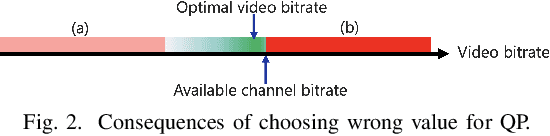
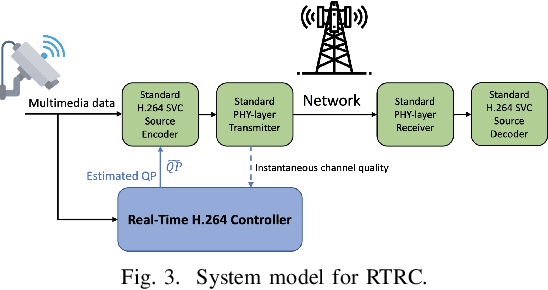
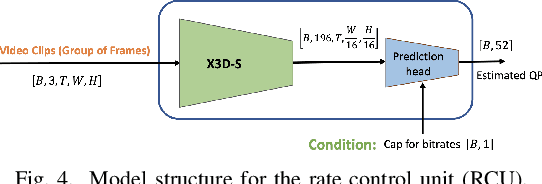
Providing wireless users with high-quality video content has become increasingly important. However, ensuring consistent video quality poses challenges due to variable encoded bitrate caused by dynamic video content and fluctuating channel bitrate caused by wireless fading effects. Suboptimal selection of encoder parameters can lead to video quality loss due to underutilized bandwidth or the introduction of video artifacts due to packet loss. To address this, a real-time deep learning based H.264 controller is proposed. This controller leverages instantaneous channel quality data driven from the physical layer, along with the video chunk, to dynamically estimate the optimal encoder parameters with a negligible delay in real-time. The objective is to maintain an encoded video bitrate slightly below the available channel bitrate. Experimental results, conducted on both QCIF dataset and a diverse selection of random videos from public datasets, validate the effectiveness of the approach. Remarkably, improvements of 10-20 dB in PSNR with repect to the state-of-the-art adaptive bitrate video streaming is achieved, with an average packet drop rate as low as 0.002.