 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-hop Question Answering under Temporal Knowledge Editing
Mar 30, 2024
Multi-hop question answering (MQA) under knowledge editing (KE) has garnered significant attention in the era of large language models. However, existing models for MQA under KE exhibit poor performance when dealing with questions containing explicit temporal contexts. To address this limitation, we propose a novel framework, namely TEMPoral knowLEdge augmented Multi-hop Question Answering (TEMPLE-MQA). Unlike previous methods, TEMPLE-MQA first constructs a time-aware graph (TAG) to store edit knowledge in a structured manner. Then, through our proposed inference path, structural retrieval, and joint reasoning stages, TEMPLE-MQA effectively discerns temporal contexts within the question query. Experiments on benchmark datasets demonstrate that TEMPLE-MQA significantly outperforms baseline models. Additionally, we contribute a new dataset, namely TKEMQA, which serves as the inaugural benchmark tailored specifically for MQA with temporal scopes.
Feature-Based Echo-State Networks: A Step Towards Interpretability and Minimalism in Reservoir Computer
Mar 28, 2024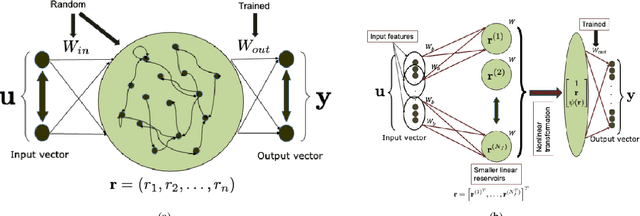
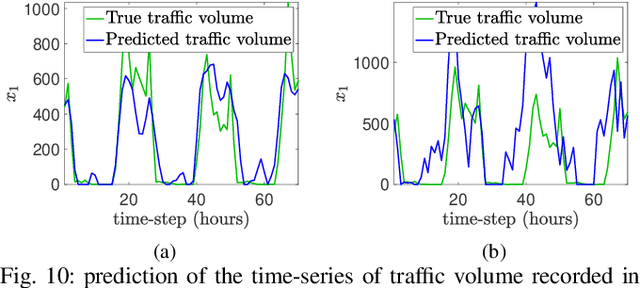
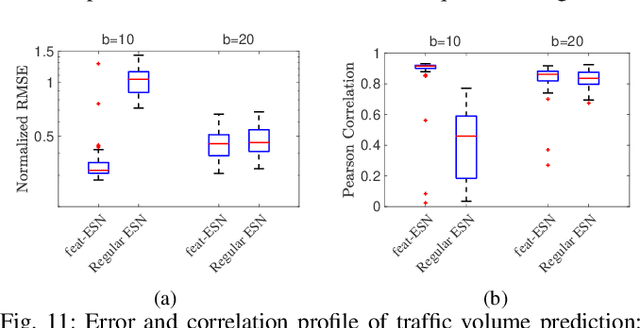
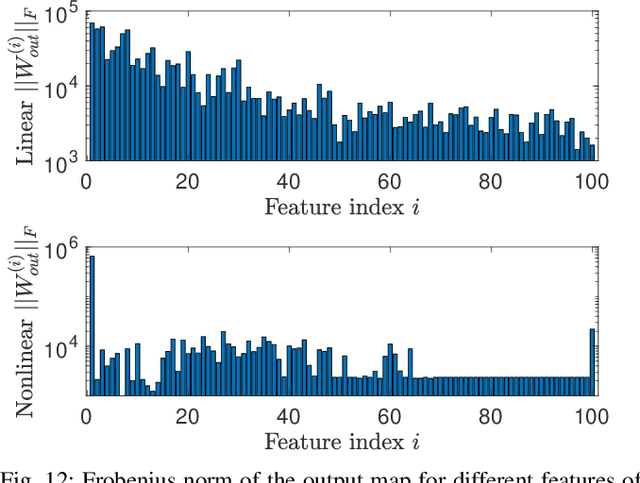
This paper proposes a novel and interpretable recurrent neural-network structure using the echo-state network (ESN) paradigm for time-series prediction. While the traditional ESNs perform well for dynamical systems prediction, it needs a large dynamic reservoir with increased computational complexity. It also lacks interpretability to discern contributions from different input combinations to the output. Here, a systematic reservoir architecture is developed using smaller parallel reservoirs driven by different input combinations, known as features, and then they are nonlinearly combined to produce the output. The resultant feature-based ESN (Feat-ESN) outperforms the traditional single-reservoir ESN with less reservoir nodes. The predictive capability of the proposed architecture is demonstrated on three systems: two synthetic datasets from chaotic dynamical systems and a set of real-time traffic data.
Nonparametric Bellman Mappings for Reinforcement Learning: Application to Robust Adaptive Filtering
Mar 29, 2024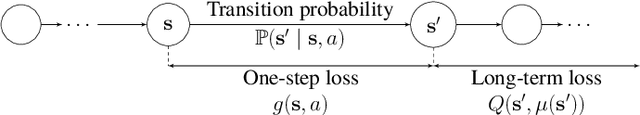
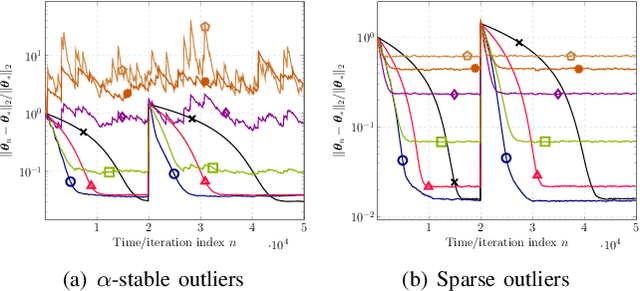
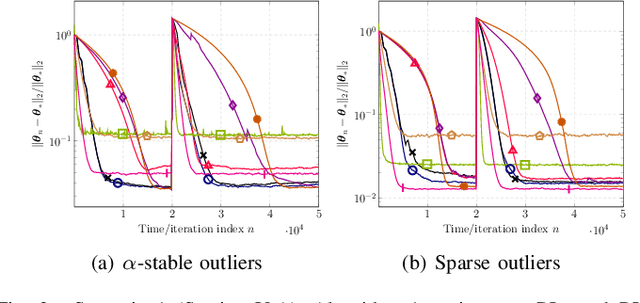
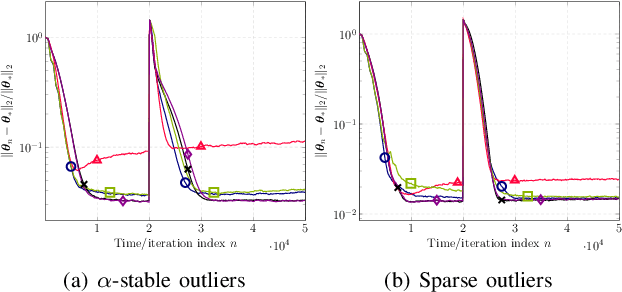
This paper designs novel nonparametric Bellman mappings in reproducing kernel Hilbert spaces (RKHSs) for reinforcement learning (RL). The proposed mappings benefit from the rich approximating properties of RKHSs, adopt no assumptions on the statistics of the data owing to their nonparametric nature, require no knowledge on transition probabilities of Markov decision processes, and may operate without any training data. Moreover, they allow for sampling on-the-fly via the design of trajectory samples, re-use past test data via experience replay, effect dimensionality reduction by random Fourier features, and enable computationally lightweight operations to fit into efficient online or time-adaptive learning. The paper offers also a variational framework to design the free parameters of the proposed Bellman mappings, and shows that appropriate choices of those parameters yield several popular Bellman-mapping designs. As an application, the proposed mappings are employed to offer a novel solution to the problem of countering outliers in adaptive filtering. More specifically, with no prior information on the statistics of the outliers and no training data, a policy-iteration algorithm is introduced to select online, per time instance, the ``optimal'' coefficient p in the least-mean-p-power-error method. Numerical tests on synthetic data showcase, in most of the cases, the superior performance of the proposed solution over several RL and non-RL schemes.
HARMamba: Efficient Wearable Sensor Human Activity Recognition Based on Bidirectional Selective SSM
Mar 29, 2024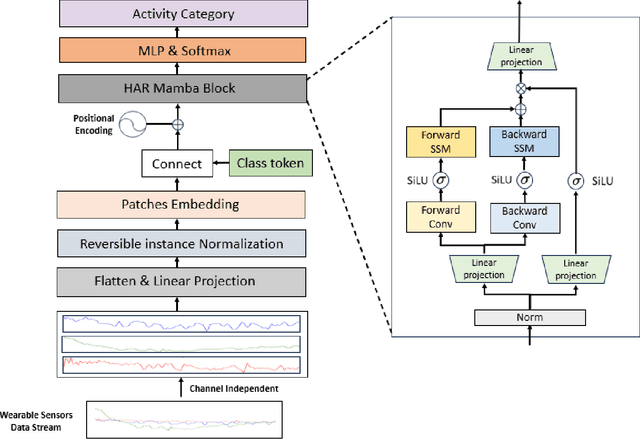
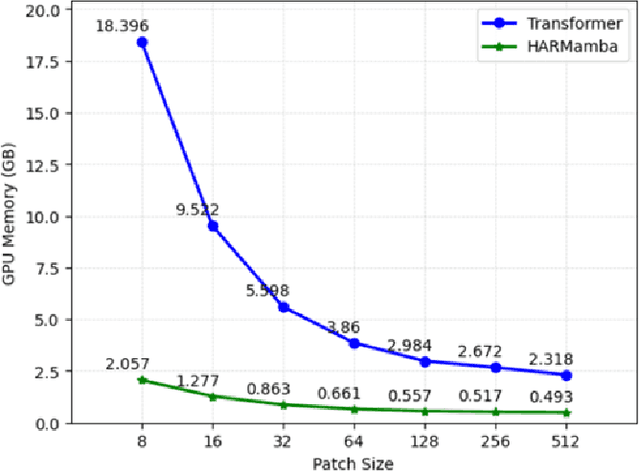
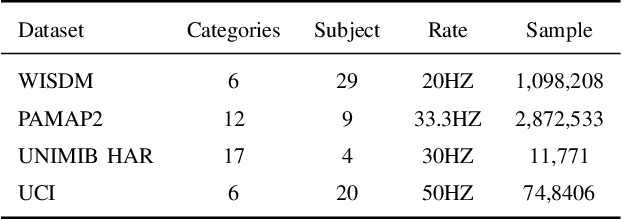
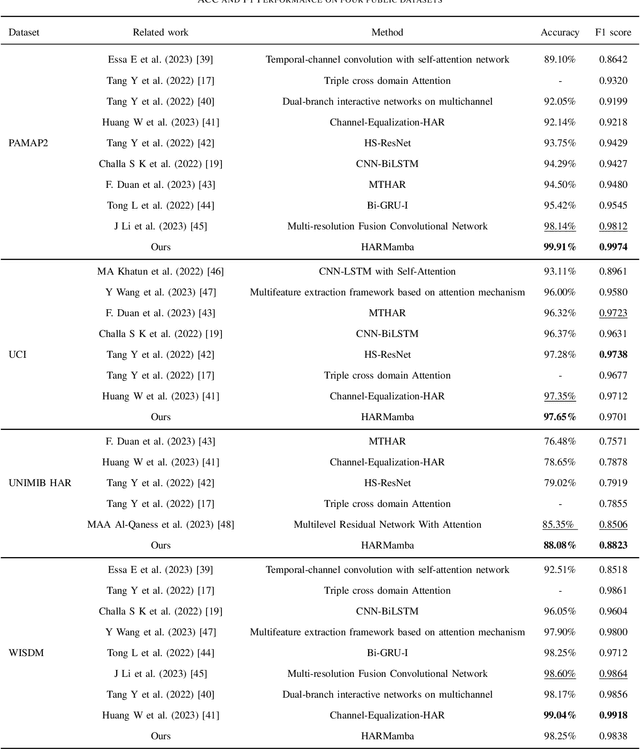
Wearable sensor human activity recognition (HAR) is a crucial area of research in activity sensing. While transformer-based temporal deep learning models have been extensively studied and implemented, their large number of parameters present significant challenges in terms of system computing load and memory usage, rendering them unsuitable for real-time mobile activity recognition applications. Recently, an efficient hardware-aware state space model (SSM) called Mamba has emerged as a promising alternative. Mamba demonstrates strong potential in long sequence modeling, boasts a simpler network architecture, and offers an efficient hardware-aware design. Leveraging SSM for activity recognition represents an appealing avenue for exploration. In this study, we introduce HARMamba, which employs a more lightweight selective SSM as the foundational model architecture for activity recognition. The goal is to address the computational resource constraints encountered in real-time activity recognition scenarios. Our approach involves processing sensor data flow by independently learning each channel and segmenting the data into "patches". The marked sensor sequence's position embedding serves as the input token for the bidirectional state space model, ultimately leading to activity categorization through the classification head. Compared to established activity recognition frameworks like Transformer-based models, HARMamba achieves superior performance while also reducing computational and memory overhead. Furthermore, our proposed method has been extensively tested on four public activity datasets: PAMAP2, WISDM, UNIMIB, and UCI, demonstrating impressive performance in activity recognition tasks.
IIP-Mixer:Intra-Inter Patch Mixing Architecture for Battery Remaining Useful Life Prediction
Mar 27, 2024Accurately estimating the Remaining Useful Life (RUL) of lithium-ion batteries is crucial for maintaining the safe and stable operation of rechargeable battery management systems. However, this task is often challenging due to the complex temporal dynamics involved. Recently, attention-based networks, such as Transformers and Informer, have been the popular architecture in time series forecasting. Despite their effectiveness, these models with abundant parameters necessitate substantial training time to unravel temporal patterns. To tackle these challenges, we propose a simple MLP-Mixer-based architecture named 'Intra-Inter Patch Mixer' (IIP-Mixer), which is an architecture based exclusively on multi-layer perceptrons (MLPs), extracting information by mixing operations along both intra-patch and inter-patch dimensions for battery RUL prediction. The proposed IIP-Mixer comprises parallel dual-head mixer layers: the intra-patch mixing MLP, capturing local temporal patterns in the short-term period, and the inter-patch mixing MLP, capturing global temporal patterns in the long-term period. Notably, to address the varying importance of features in RUL prediction, we introduce a weighted loss function in the MLP-Mixer-based architecture, marking the first time such an approach has been employed. Our experiments demonstrate that IIP-Mixer achieves competitive performance in battery RUL prediction, outperforming other popular time-series frameworks
CBF-Based STL Motion Planning for Social Navigation in Crowded Environment
Mar 30, 2024A motion planning methodology based on the combination of Control Barrier Functions (CBF) and Signal Temporal Logic (STL) is employed in this paper. This methodology allows task completion at any point within a specified time interval, considering a dynamic system subject to velocity constraints. In this work, we apply this approach into the context of Socially Responsible Navigation (SRN), introducing a rotation constraint. This constraint is designed to maintain the user within the robot's field of view (FOV), enhancing human-robot interaction with the concept of side-by-side human-robot companion. This angular constraint offers the possibility to customize social navigation to specific needs, thereby enabling safe SRN. Its validation is carried out through simulations demonstrating the system's effectiveness in adhering to spatio-temporal constraints, including those related to robot velocity, rotation, and the presence of static and dynamic obstacles.
A Survey on Deep Learning and State-of-the-art Applications
Mar 31, 2024Deep learning, a branch of artificial intelligence, is a computational model that uses multiple layers of interconnected units (neurons) to learn intricate patterns and representations directly from raw input data. Empowered by this learning capability, it has become a powerful tool for solving complex problems and is the core driver of many groundbreaking technologies and innovations. Building a deep learning model is a challenging task due to the algorithm`s complexity and the dynamic nature of real-world problems. Several studies have reviewed deep learning concepts and applications. However, the studies mostly focused on the types of deep learning models and convolutional neural network architectures, offering limited coverage of the state-of-the-art of deep learning models and their applications in solving complex problems across different domains. Therefore, motivated by the limitations, this study aims to comprehensively review the state-of-the-art deep learning models in computer vision, natural language processing, time series analysis and pervasive computing. We highlight the key features of the models and their effectiveness in solving the problems within each domain. Furthermore, this study presents the fundamentals of deep learning, various deep learning model types and prominent convolutional neural network architectures. Finally, challenges and future directions in deep learning research are discussed to offer a broader perspective for future researchers.
MugenNet: A Novel Combined Convolution Neural Network and Transformer Network with its Application for Colonic Polyp Image Segmentation
Mar 31, 2024Biomedical image segmentation is a very important part in disease diagnosis. The term "colonic polyps" refers to polypoid lesions that occur on the surface of the colonic mucosa within the intestinal lumen. In clinical practice, early detection of polyps is conducted through colonoscopy examinations and biomedical image processing. Therefore, the accurate polyp image segmentation is of great significance in colonoscopy examinations. Convolutional Neural Network (CNN) is a common automatic segmentation method, but its main disadvantage is the long training time. Transformer utilizes a self-attention mechanism, which essentially assigns different importance weights to each piece of information, thus achieving high computational efficiency during segmentation. However, a potential drawback is the risk of information loss. In the study reported in this paper, based on the well-known hybridization principle, we proposed a method to combine CNN and Transformer to retain the strengths of both, and we applied this method to build a system called MugenNet for colonic polyp image segmentation. We conducted a comprehensive experiment to compare MugenNet with other CNN models on five publicly available datasets. The ablation experiment on MugentNet was conducted as well. The experimental results show that MugenNet achieves significantly higher processing speed and accuracy compared with CNN alone. The generalized implication with our work is a method to optimally combine two complimentary methods of machine learning.
DreamMotion: Space-Time Self-Similarity Score Distillation for Zero-Shot Video Editing
Mar 18, 2024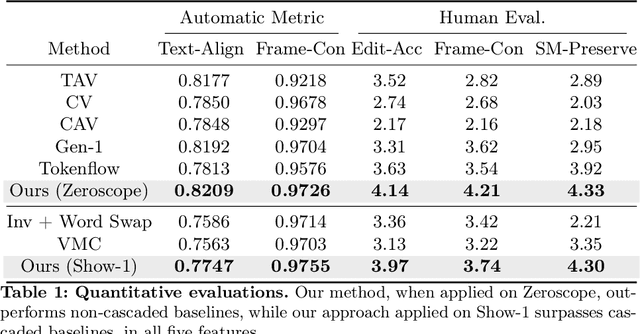


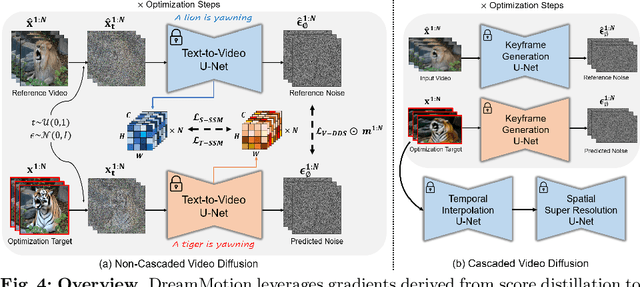
Text-driven diffusion-based video editing presents a unique challenge not encountered in image editing literature: establishing real-world motion. Unlike existing video editing approaches, here we focus on score distillation sampling to circumvent the standard reverse diffusion process and initiate optimization from videos that already exhibit natural motion. Our analysis reveals that while video score distillation can effectively introduce new content indicated by target text, it can also cause significant structure and motion deviation. To counteract this, we propose to match space-time self-similarities of the original video and the edited video during the score distillation. Thanks to the use of score distillation, our approach is model-agnostic, which can be applied for both cascaded and non-cascaded video diffusion frameworks. Through extensive comparisons with leading methods, our approach demonstrates its superiority in altering appearances while accurately preserving the original structure and motion.
StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
Mar 14, 2024



The enormous success of diffusion models in text-to-image synthesis has made them promising candidates for the next generation of end-user applications for image generation and editing. Previous works have focused on improving the usability of diffusion models by reducing the inference time or increasing user interactivity by allowing new, fine-grained controls such as region-based text prompts. However, we empirically find that integrating both branches of works is nontrivial, limiting the potential of diffusion models. To solve this incompatibility, we present StreamMultiDiffusion, the first real-time region-based text-to-image generation framework. By stabilizing fast inference techniques and restructuring the model into a newly proposed multi-prompt stream batch architecture, we achieve $\times 10$ faster panorama generation than existing solutions, and the generation speed of 1.57 FPS in region-based text-to-image synthesis on a single RTX 2080 Ti GPU. Our solution opens up a new paradigm for interactive image generation named semantic palette, where high-quality images are generated in real-time from given multiple hand-drawn regions, encoding prescribed semantic meanings (e.g., eagle, girl). Our code and demo application are available at https://github.com/ironjr/StreamMultiDiffusion.