 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Learning Quantum States with the Logarithmic Loss via VB-FTRL
Nov 06, 2023
Online learning quantum states with the logarithmic loss (LL-OLQS) is a quantum generalization of online portfolio selection, a classic open problem in the field of online learning for over three decades. The problem also emerges in designing randomized optimization algorithms for maximum-likelihood quantum state tomography. Recently, Jezequel et al. (arXiv:2209.13932) proposed the VB-FTRL algorithm, the first nearly regret-optimal algorithm for OPS with moderate computational complexity. In this note, we generalize VB-FTRL for LL-OLQS. Let $d$ denote the dimension and $T$ the number of rounds. The generalized algorithm achieves a regret rate of $O ( d^2 \log ( d + T ) )$ for LL-OLQS. Each iteration of the algorithm consists of solving a semidefinite program that can be implemented in polynomial time by, e.g., cutting-plane methods. For comparison, the best-known regret rate for LL-OLQS is currently $O ( d^2 \log T )$, achieved by the exponential weight method. However, there is no explicit implementation available for the exponential weight method for LL-OLQS. To facilitate the generalization, we introduce the notion of VB-convexity. VB-convexity is a sufficient condition for the logarithmic barrier associated with any function to be convex and is of independent interest.
iDb-A*: Iterative Search and Optimization for Optimal Kinodynamic Motion Planning
Nov 06, 2023Motion planning for robotic systems with complex dynamics is a challenging problem. While recent sampling-based algorithms achieve asymptotic optimality by propagating random control inputs, their empirical convergence rate is often poor, especially in high-dimensional systems such as multirotors. An alternative approach is to first plan with a simplified geometric model and then use trajectory optimization to follow the reference path while accounting for the true dynamics. However, this approach may fail to produce a valid trajectory if the initial guess is not close to a dynamically feasible trajectory. In this paper, we present Iterative Discontinuity Bounded A* (iDb-A*), a novel kinodynamic motion planner that combines search and optimization iteratively. The search step utilizes a finite set of short trajectories (motion primitives) that are interconnected while allowing for a bounded discontinuity between them. The optimization step locally repairs the discontinuities with trajectory optimization. By progressively reducing the allowed discontinuity and incorporating more motion primitives, our algorithm achieves asymptotic optimality with excellent any-time performance. We provide a benchmark of 43 problems across eight different dynamical systems, including different versions of unicycles and multirotors. Compared to state-of-the-art methods, iDb-A* consistently solves more problem instances and finds lower-cost solutions more rapidly.
Plug-and-Play Stability for Intracortical Brain-Computer Interfaces: A One-Year Demonstration of Seamless Brain-to-Text Communication
Nov 06, 2023Intracortical brain-computer interfaces (iBCIs) have shown promise for restoring rapid communication to people with neurological disorders such as amyotrophic lateral sclerosis (ALS). However, to maintain high performance over time, iBCIs typically need frequent recalibration to combat changes in the neural recordings that accrue over days. This requires iBCI users to stop using the iBCI and engage in supervised data collection, making the iBCI system hard to use. In this paper, we propose a method that enables self-recalibration of communication iBCIs without interrupting the user. Our method leverages large language models (LMs) to automatically correct errors in iBCI outputs. The self-recalibration process uses these corrected outputs ("pseudo-labels") to continually update the iBCI decoder online. Over a period of more than one year (403 days), we evaluated our Continual Online Recalibration with Pseudo-labels (CORP) framework with one clinical trial participant. CORP achieved a stable decoding accuracy of 93.84% in an online handwriting iBCI task, significantly outperforming other baseline methods. Notably, this is the longest-running iBCI stability demonstration involving a human participant. Our results provide the first evidence for long-term stabilization of a plug-and-play, high-performance communication iBCI, addressing a major barrier for the clinical translation of iBCIs.
Exact Inference for Continuous-Time Gaussian Process Dynamics
Sep 05, 2023
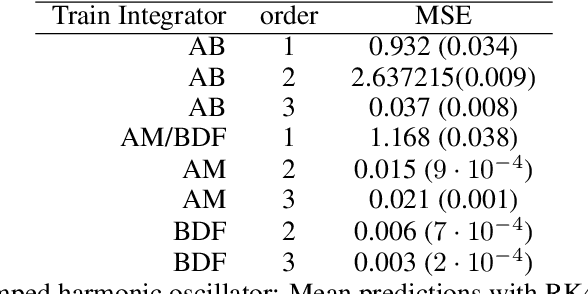
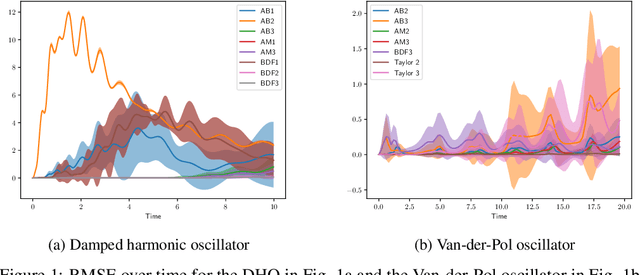
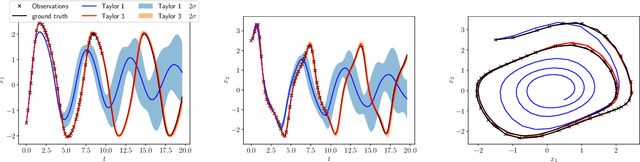
Physical systems can often be described via a continuous-time dynamical system. In practice, the true system is often unknown and has to be learned from measurement data. Since data is typically collected in discrete time, e.g. by sensors, most methods in Gaussian process (GP) dynamics model learning are trained on one-step ahead predictions. This can become problematic in several scenarios, e.g. if measurements are provided at irregularly-sampled time steps or physical system properties have to be conserved. Thus, we aim for a GP model of the true continuous-time dynamics. Higher-order numerical integrators provide the necessary tools to address this problem by discretizing the dynamics function with arbitrary accuracy. Many higher-order integrators require dynamics evaluations at intermediate time steps making exact GP inference intractable. In previous work, this problem is often tackled by approximating the GP posterior with variational inference. However, exact GP inference is preferable in many scenarios, e.g. due to its mathematical guarantees. In order to make direct inference tractable, we propose to leverage multistep and Taylor integrators. We demonstrate how to derive flexible inference schemes for these types of integrators. Further, we derive tailored sampling schemes that allow to draw consistent dynamics functions from the learned posterior. This is crucial to sample consistent predictions from the dynamics model. We demonstrate empirically and theoretically that our approach yields an accurate representation of the continuous-time system.
Keeping in Time: Adding Temporal Context to Sentiment Analysis Models
Sep 24, 2023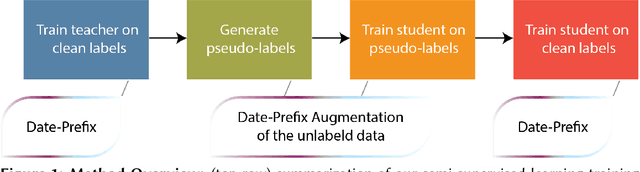

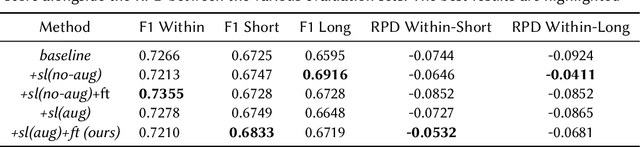
This paper presents a state-of-the-art solution to the LongEval CLEF 2023 Lab Task 2: LongEval-Classification. The goal of this task is to improve and preserve the performance of sentiment analysis models across shorter and longer time periods. Our framework feeds date-prefixed textual inputs to a pre-trained language model, where the timestamp is included in the text. We show date-prefixed samples better conditions model outputs on the temporal context of the respective texts. Moreover, we further boost performance by performing self-labeling on unlabeled data to train a student model. We augment the self-labeling process using a novel augmentation strategy leveraging the date-prefixed formatting of our samples. We demonstrate concrete performance gains on the LongEval-Classification evaluation set over non-augmented self-labeling. Our framework achieves a 2nd place ranking with an overall score of 0.6923 and reports the best Relative Performance Drop (RPD) of -0.0656 over the short evaluation set.
QWID: Quantized Weed Identification Deep neural network
Oct 29, 2023In this paper, we present an efficient solution for weed classification in agriculture. We focus on optimizing model performance at inference while respecting the constraints of the agricultural domain. We propose a Quantized Deep Neural Network model that classifies a dataset of 9 weed classes using 8-bit integer (int8) quantization, a departure from standard 32-bit floating point (fp32) models. Recognizing the hardware resource limitations in agriculture, our model balances model size, inference time, and accuracy, aligning with practical requirements. We evaluate the approach on ResNet-50 and InceptionV3 architectures, comparing their performance against their int8 quantized versions. Transfer learning and fine-tuning are applied using the DeepWeeds dataset. The results show staggering model size and inference time reductions while maintaining accuracy in real-world production scenarios like Desktop, Mobile and Raspberry Pi. Our work sheds light on a promising direction for efficient AI in agriculture, holding potential for broader applications. Code: https://github.com/parikshit14/QNN-for-weed
VIBE: Topic-Driven Temporal Adaptation for Twitter Classification
Nov 04, 2023
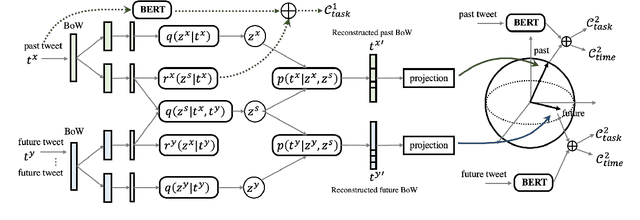
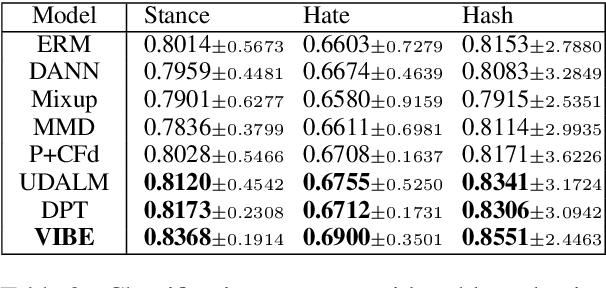
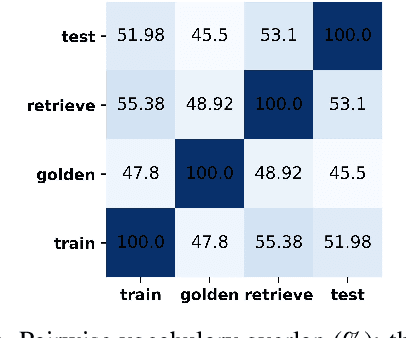
Language features are evolving in real-world social media, resulting in the deteriorating performance of text classification in dynamics. To address this challenge, we study temporal adaptation, where models trained on past data are tested in the future. Most prior work focused on continued pretraining or knowledge updating, which may compromise their performance on noisy social media data. To tackle this issue, we reflect feature change via modeling latent topic evolution and propose a novel model, VIBE: Variational Information Bottleneck for Evolutions. Concretely, we first employ two Information Bottleneck (IB) regularizers to distinguish past and future topics. Then, the distinguished topics work as adaptive features via multi-task training with timestamp and class label prediction. In adaptive learning, VIBE utilizes retrieved unlabeled data from online streams created posterior to training data time. Substantial Twitter experiments on three classification tasks show that our model, with only 3% of data, significantly outperforms previous state-of-the-art continued-pretraining methods.
* accepted by EMNLP 2023
Decoy Effect in Search Interaction: A Pilot Study
Nov 04, 2023In recent years, the influence of cognitive effects and biases on users' thinking, behaving, and decision-making has garnered increasing attention in the field of interactive information retrieval. The decoy effect, one of the main empirically confirmed cognitive biases, refers to the shift in preference between two choices when a third option (the decoy) which is inferior to one of the initial choices is introduced. However, it is not clear how the decoy effect influences user interactions with and evaluations on Search Engine Result Pages (SERPs). To bridge this gap, our study seeks to understand how the decoy effect at the document level influences users' interaction behaviors on SERPs, such as clicks, dwell time, and usefulness perceptions. We conducted experiments on two publicly available user behavior datasets and the findings reveal that, compared to cases where no decoy is present, the probability of a document being clicked could be improved and its usefulness score could be higher, should there be a decoy associated with the document.
Tight Time-Space Lower Bounds for Constant-Pass Learning
Oct 12, 2023In his breakthrough paper, Raz showed that any parity learning algorithm requires either quadratic memory or an exponential number of samples [FOCS'16, JACM'19]. A line of work that followed extended this result to a large class of learning problems. Until recently, all these results considered learning in the streaming model, where each sample is drawn independently, and the learner is allowed a single pass over the stream of samples. Garg, Raz, and Tal [CCC'19] considered a stronger model, allowing multiple passes over the stream. In the $2$-pass model, they showed that learning parities of size $n$ requires either a memory of size $n^{1.5}$ or at least $2^{\sqrt{n}}$ samples. (Their result also generalizes to other learning problems.) In this work, for any constant $q$, we prove tight memory-sample lower bounds for any parity learning algorithm that makes $q$ passes over the stream of samples. We show that such a learner requires either $\Omega(n^{2})$ memory size or at least $2^{\Omega(n)}$ samples. Beyond establishing a tight lower bound, this is the first non-trivial lower bound for $q$-pass learning for any $q\ge 3$. Similar to prior work, our results extend to any learning problem with many nearly-orthogonal concepts. We complement the lower bound with an upper bound, showing that parity learning with $q$ passes can be done efficiently with $O(n^2/\log q)$ memory.
Recursion in Recursion: Two-Level Nested Recursion for Length Generalization with Scalability
Nov 08, 2023Binary Balanced Tree RvNNs (BBT-RvNNs) enforce sequence composition according to a preset balanced binary tree structure. Thus, their non-linear recursion depth is just $\log_2 n$ ($n$ being the sequence length). Such logarithmic scaling makes BBT-RvNNs efficient and scalable on long sequence tasks such as Long Range Arena (LRA). However, such computational efficiency comes at a cost because BBT-RvNNs cannot solve simple arithmetic tasks like ListOps. On the flip side, RvNNs (e.g., Beam Tree RvNN) that do succeed on ListOps (and other structure-sensitive tasks like formal logical inference) are generally several times more expensive than even RNNs. In this paper, we introduce a novel framework -- Recursion in Recursion (RIR) to strike a balance between the two sides - getting some of the benefits from both worlds. In RIR, we use a form of two-level nested recursion - where the outer recursion is a $k$-ary balanced tree model with another recursive model (inner recursion) implementing its cell function. For the inner recursion, we choose Beam Tree RvNNs (BT-RvNN). To adjust BT-RvNNs within RIR we also propose a novel strategy of beam alignment. Overall, this entails that the total recursive depth in RIR is upper-bounded by $k \log_k n$. Our best RIR-based model is the first model that demonstrates high ($\geq 90\%$) length-generalization performance on ListOps while at the same time being scalable enough to be trainable on long sequence inputs from LRA. Moreover, in terms of accuracy in the LRA language tasks, it performs competitively with Structured State Space Models (SSMs) without any special initialization - outperforming Transformers by a large margin. On the other hand, while SSMs can marginally outperform RIR on LRA, they (SSMs) fail to length-generalize on ListOps. Our code is available at: \url{https://github.com/JRC1995/BeamRecursionFamily/}.