 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exact Inference for Continuous-Time Gaussian Process Dynamics
Sep 05, 2023

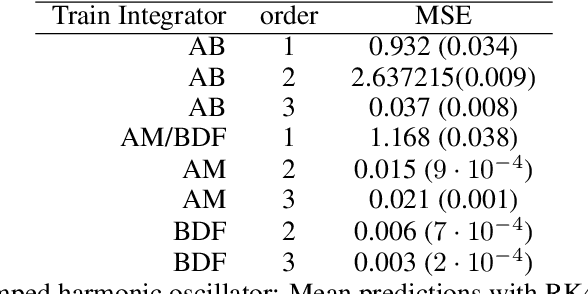
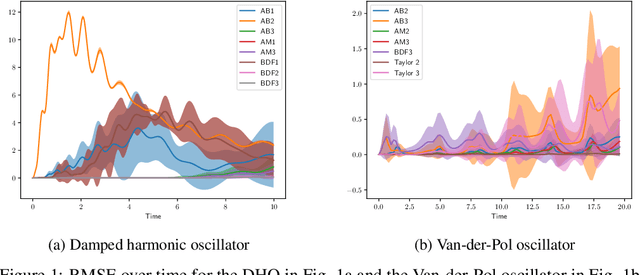
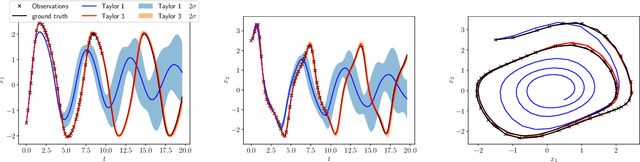
Physical systems can often be described via a continuous-time dynamical system. In practice, the true system is often unknown and has to be learned from measurement data. Since data is typically collected in discrete time, e.g. by sensors, most methods in Gaussian process (GP) dynamics model learning are trained on one-step ahead predictions. This can become problematic in several scenarios, e.g. if measurements are provided at irregularly-sampled time steps or physical system properties have to be conserved. Thus, we aim for a GP model of the true continuous-time dynamics. Higher-order numerical integrators provide the necessary tools to address this problem by discretizing the dynamics function with arbitrary accuracy. Many higher-order integrators require dynamics evaluations at intermediate time steps making exact GP inference intractable. In previous work, this problem is often tackled by approximating the GP posterior with variational inference. However, exact GP inference is preferable in many scenarios, e.g. due to its mathematical guarantees. In order to make direct inference tractable, we propose to leverage multistep and Taylor integrators. We demonstrate how to derive flexible inference schemes for these types of integrators. Further, we derive tailored sampling schemes that allow to draw consistent dynamics functions from the learned posterior. This is crucial to sample consistent predictions from the dynamics model. We demonstrate empirically and theoretically that our approach yields an accurate representation of the continuous-time system.
The Background Also Matters: Background-Aware Motion-Guided Objects Discovery
Nov 05, 2023Recent works have shown that objects discovery can largely benefit from the inherent motion information in video data. However, these methods lack a proper background processing, resulting in an over-segmentation of the non-object regions into random segments. This is a critical limitation given the unsupervised setting, where object segments and noise are not distinguishable. To address this limitation we propose BMOD, a Background-aware Motion-guided Objects Discovery method. Concretely, we leverage masks of moving objects extracted from optical flow and design a learning mechanism to extend them to the true foreground composed of both moving and static objects. The background, a complementary concept of the learned foreground class, is then isolated in the object discovery process. This enables a joint learning of the objects discovery task and the object/non-object separation. The conducted experiments on synthetic and real-world datasets show that integrating our background handling with various cutting-edge methods brings each time a considerable improvement. Specifically, we improve the objects discovery performance with a large margin, while establishing a strong baseline for object/non-object separation.
An adaptive standardisation model for Day-Ahead electricity price forecasting
Nov 05, 2023The study of Day-Ahead prices in the electricity market is one of the most popular problems in time series forecasting. Previous research has focused on employing increasingly complex learning algorithms to capture the sophisticated dynamics of the market. However, there is a threshold where increased complexity fails to yield substantial improvements. In this work, we propose an alternative approach by introducing an adaptive standardisation to mitigate the effects of dataset shifts that commonly occur in the market. By doing so, learning algorithms can prioritize uncovering the true relationship between the target variable and the explanatory variables. We investigate four distinct markets, including two novel datasets, previously unexplored in the literature. These datasets provide a more realistic representation of the current market context, that conventional datasets do not show. The results demonstrate a significant improvement across all four markets, using learning algorithms that are less complex yet widely accepted in the literature. This significant advancement unveils opens up new lines of research in this field, highlighting the potential of adaptive transformations in enhancing the performance of forecasting models.
Exploring Deep Learning Image Super-Resolution for Iris Recognition
Nov 02, 2023In this work we test the ability of deep learning methods to provide an end-to-end mapping between low and high resolution images applying it to the iris recognition problem. Here, we propose the use of two deep learning single-image super-resolution approaches: Stacked Auto-Encoders (SAE) and Convolutional Neural Networks (CNN) with the most possible lightweight structure to achieve fast speed, preserve local information and reduce artifacts at the same time. We validate the methods with a database of 1.872 near-infrared iris images with quality assessment and recognition experiments showing the superiority of deep learning approaches over the compared algorithms.
Predictive Control for Autonomous Driving with Uncertain, Multi-modal Predictions
Oct 31, 2023We propose a Stochastic MPC (SMPC) formulation for path planning with autonomous vehicles in scenarios involving multiple agents with multi-modal predictions. The multi-modal predictions capture the uncertainty of urban driving in distinct modes/maneuvers (e.g., yield, keep speed) and driving trajectories (e.g., speed, turning radius), which are incorporated for multi-modal collision avoidance chance constraints for path planning. In the presence of multi-modal uncertainties, it is challenging to reliably compute feasible path planning solutions at real-time frequencies ($\geq$ 10 Hz). Our main technological contribution is a convex SMPC formulation that simultaneously (1) optimizes over parameterized feedback policies and (2) allocates risk levels for each mode of the prediction. The use of feedback policies and risk allocation enhances the feasibility and performance of the SMPC formulation against multi-modal predictions with large uncertainty. We evaluate our approach via simulations and road experiments with a full-scale vehicle interacting in closed-loop with virtual vehicles. We consider distinct, multi-modal driving scenarios: 1) Negotiating a traffic light and a fast, tailgating agent, 2) Executing an unprotected left turn at a traffic intersection, and 3) Changing lanes in the presence of multiple agents. For all of these scenarios, our approach reliably computes multi-modal solutions to the path-planning problem at real-time frequencies.
Keeping in Time: Adding Temporal Context to Sentiment Analysis Models
Sep 24, 2023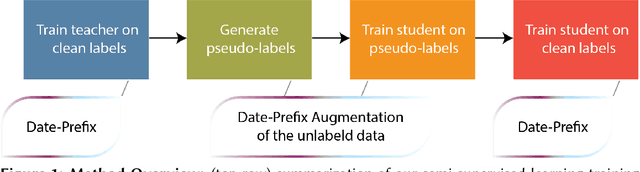

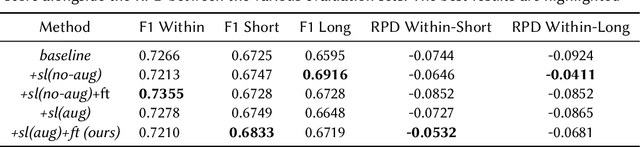
This paper presents a state-of-the-art solution to the LongEval CLEF 2023 Lab Task 2: LongEval-Classification. The goal of this task is to improve and preserve the performance of sentiment analysis models across shorter and longer time periods. Our framework feeds date-prefixed textual inputs to a pre-trained language model, where the timestamp is included in the text. We show date-prefixed samples better conditions model outputs on the temporal context of the respective texts. Moreover, we further boost performance by performing self-labeling on unlabeled data to train a student model. We augment the self-labeling process using a novel augmentation strategy leveraging the date-prefixed formatting of our samples. We demonstrate concrete performance gains on the LongEval-Classification evaluation set over non-augmented self-labeling. Our framework achieves a 2nd place ranking with an overall score of 0.6923 and reports the best Relative Performance Drop (RPD) of -0.0656 over the short evaluation set.
MixtureGrowth: Growing Neural Networks by Recombining Learned Parameters
Nov 07, 2023Most deep neural networks are trained under fixed network architectures and require retraining when the architecture changes. If expanding the network's size is needed, it is necessary to retrain from scratch, which is expensive. To avoid this, one can grow from a small network by adding random weights over time to gradually achieve the target network size. However, this naive approach falls short in practice as it brings too much noise to the growing process. Prior work tackled this issue by leveraging the already learned weights and training data for generating new weights through conducting a computationally expensive analysis step. In this paper, we introduce MixtureGrowth, a new approach to growing networks that circumvents the initialization overhead in prior work. Before growing, each layer in our model is generated with a linear combination of parameter templates. Newly grown layer weights are generated by using a new linear combination of existing templates for a layer. On one hand, these templates are already trained for the task, providing a strong initialization. On the other, the new coefficients provide flexibility for the added layer weights to learn something new. We show that our approach boosts top-1 accuracy over the state-of-the-art by 2-2.5% on CIFAR-100 and ImageNet datasets, while achieving comparable performance with fewer FLOPs to a larger network trained from scratch. Code is available at https://github.com/chaudatascience/mixturegrowth.
Harnessing Manycore Processors with Distributed Memory for Accelerated Training of Sparse and Recurrent Models
Nov 07, 2023Current AI training infrastructure is dominated by single instruction multiple data (SIMD) and systolic array architectures, such as Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs), that excel at accelerating parallel workloads and dense vector matrix multiplications. Potentially more efficient neural network models utilizing sparsity and recurrence cannot leverage the full power of SIMD processor and are thus at a severe disadvantage compared to today's prominent parallel architectures like Transformers and CNNs, thereby hindering the path towards more sustainable AI. To overcome this limitation, we explore sparse and recurrent model training on a massively parallel multiple instruction multiple data (MIMD) architecture with distributed local memory. We implement a training routine based on backpropagation through time (BPTT) for the brain-inspired class of Spiking Neural Networks (SNNs) that feature binary sparse activations. We observe a massive advantage in using sparse activation tensors with a MIMD processor, the Intelligence Processing Unit (IPU) compared to GPUs. On training workloads, our results demonstrate 5-10x throughput gains compared to A100 GPUs and up to 38x gains for higher levels of activation sparsity, without a significant slowdown in training convergence or reduction in final model performance. Furthermore, our results show highly promising trends for both single and multi IPU configurations as we scale up to larger model sizes. Our work paves the way towards more efficient, non-standard models via AI training hardware beyond GPUs, and competitive large scale SNN models.
Perceptual Quality Improvement in Videoconferencing using Keyframes-based GAN
Nov 07, 2023In the latest years, videoconferencing has taken a fundamental role in interpersonal relations, both for personal and business purposes. Lossy video compression algorithms are the enabling technology for videoconferencing, as they reduce the bandwidth required for real-time video streaming. However, lossy video compression decreases the perceived visual quality. Thus, many techniques for reducing compression artifacts and improving video visual quality have been proposed in recent years. In this work, we propose a novel GAN-based method for compression artifacts reduction in videoconferencing. Given that, in this context, the speaker is typically in front of the camera and remains the same for the entire duration of the transmission, we can maintain a set of reference keyframes of the person from the higher-quality I-frames that are transmitted within the video stream and exploit them to guide the visual quality improvement; a novel aspect of this approach is the update policy that maintains and updates a compact and effective set of reference keyframes. First, we extract multi-scale features from the compressed and reference frames. Then, our architecture combines these features in a progressive manner according to facial landmarks. This allows the restoration of the high-frequency details lost after the video compression. Experiments show that the proposed approach improves visual quality and generates photo-realistic results even with high compression rates. Code and pre-trained networks are publicly available at https://github.com/LorenzoAgnolucci/Keyframes-GAN.
Improved Topological Preservation in 3D Axon Segmentation and Centerline Detection using Geometric Assessment-driven Topological Smoothing (GATS)
Nov 07, 2023Automated axon tracing via fully supervised learning requires large amounts of 3D brain imagery, which is time consuming and laborious to obtain. It also requires expertise. Thus, there is a need for more efficient segmentation and centerline detection techniques to use in conjunction with automated annotation tools. Topology-preserving methods ensure that segmented components maintain geometric connectivity, which is especially meaningful for applications where volumetric data is used, and these methods often make use of morphological thinning algorithms as the thinned outputs can be useful for both segmentation and centerline detection of curvilinear structures. Current morphological thinning approaches used in conjunction with topology-preserving methods are prone to over-thinning and require manual configuration of hyperparameters. We propose an automated approach for morphological smoothing using geometric assessment of the radius of tubular structures in brain microscopy volumes, and apply average pooling to prevent over-thinning. We use this approach to formulate a loss function, which we call Geo-metric Assessment-driven Topological Smoothing loss, or GATS. Our approach increased segmentation and center-line detection evaluation metrics by 2%-5% across multiple datasets, and improved the Betti error rates by 9%. Our ablation study showed that geometric assessment of tubular structures achieved higher segmentation and centerline detection scores, and using average pooling for morphological smoothing in place of thinning algorithms reduced the Betti errors. We observed increased topological preservation during automated annotation of 3D axons volumes from models trained with GATS.