 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Estimator-Coupled Reinforcement Learning for Robust Purely Tactile In-Hand Manipulation
Nov 07, 2023
This paper identifies and addresses the problems with naively combining (reinforcement) learning-based controllers and state estimators for robotic in-hand manipulation. Specifically, we tackle the challenging task of purely tactile, goal-conditioned, dextrous in-hand reorientation with the hand pointing downwards. Due to the limited sensing available, many control strategies that are feasible in simulation when having full knowledge of the object's state do not allow for accurate state estimation. Hence, separately training the controller and the estimator and combining the two at test time leads to poor performance. We solve this problem by coupling the control policy to the state estimator already during training in simulation. This approach leads to more robust state estimation and overall higher performance on the task while maintaining an interpretability advantage over end-to-end policy learning. With our GPU-accelerated implementation, learning from scratch takes a median training time of only 6.5 hours on a single, low-cost GPU. In simulation experiments with the DLR-Hand II and for four significantly different object shapes, we provide an in-depth analysis of the performance of our approach. We demonstrate the successful sim2real transfer by rotating the four objects to all 24 orientations in the $\pi/2$ discretization of SO(3), which has never been achieved for such a diverse set of shapes. Finally, our method can reorient a cube consecutively to nine goals (median), which was beyond the reach of previous methods in this challenging setting.
A Hybrid Joint Source-Channel Coding Scheme for Mobile Multi-hop Networks
Nov 13, 2023We propose a novel hybrid joint source-channel coding (JSCC) scheme for robust image transmission over multi-hop networks. In the considered scenario, a mobile user wants to deliver an image to its destination over a mobile cellular network. We assume a practical setting, where the links between the nodes belonging to the mobile core network are stable and of high quality, while the link between the mobile user and the first node (e.g., the access point) is potentially time-varying with poorer quality. In recent years, neural network based JSCC schemes (called DeepJSCC) have emerged as promising solutions to overcome the limitations of separation-based fully digital schemes. However, relying on analog transmission, DeepJSCC suffers from noise accumulation over multi-hop networks. Moreover, most of the hops within the mobile core network may be high-capacity wireless connections, calling for digital approaches. To this end, we propose a hybrid solution, where DeepJSCC is adopted for the first hop, while the received signal at the first relay is digitally compressed and forwarded through the mobile core network. We show through numerical simulations that the proposed scheme is able to outperform both the fully analog and fully digital schemes. Thanks to DeepJSCC it can avoid the cliff effect over the first hop, while also avoiding noise forwarding over the mobile core network thank to digital transmission. We believe this work paves the way for the practical deployment of DeepJSCC solutions in 6G and future wireless networks.
Vision-Language Integration in Multimodal Video Transformers (Partially) Aligns with the Brain
Nov 13, 2023Integrating information from multiple modalities is arguably one of the essential prerequisites for grounding artificial intelligence systems with an understanding of the real world. Recent advances in video transformers that jointly learn from vision, text, and sound over time have made some progress toward this goal, but the degree to which these models integrate information from modalities still remains unclear. In this work, we present a promising approach for probing a pre-trained multimodal video transformer model by leveraging neuroscientific evidence of multimodal information processing in the brain. Using brain recordings of participants watching a popular TV show, we analyze the effects of multi-modal connections and interactions in a pre-trained multi-modal video transformer on the alignment with uni- and multi-modal brain regions. We find evidence that vision enhances masked prediction performance during language processing, providing support that cross-modal representations in models can benefit individual modalities. However, we don't find evidence of brain-relevant information captured by the joint multi-modal transformer representations beyond that captured by all of the individual modalities. We finally show that the brain alignment of the pre-trained joint representation can be improved by fine-tuning using a task that requires vision-language inferences. Overall, our results paint an optimistic picture of the ability of multi-modal transformers to integrate vision and language in partially brain-relevant ways but also show that improving the brain alignment of these models may require new approaches.
Assessing the Interpretability of Programmatic Policies with Large Language Models
Nov 12, 2023Although the synthesis of programs encoding policies often carries the promise of interpretability, systematic evaluations to assess the interpretability of these policies were never performed, likely because of the complexity of such an evaluation. In this paper, we introduce a novel metric that uses large-language models (LLM) to assess the interpretability of programmatic policies. For our metric, an LLM is given both a program and a description of its associated programming language. The LLM then formulates a natural language explanation of the program. This explanation is subsequently fed into a second LLM, which tries to reconstruct the program from the natural language explanation. Our metric measures the behavioral similarity between the reconstructed program and the original. We validate our approach using obfuscated programs that are used to solve classic programming problems. We also assess our metric with programmatic policies synthesized for playing a real-time strategy game, comparing the interpretability scores of programmatic policies synthesized by an existing system to lightly obfuscated versions of the same programs. Our LLM-based interpretability score consistently ranks less interpretable programs lower and more interpretable ones higher. These findings suggest that our metric could serve as a reliable and inexpensive tool for evaluating the interpretability of programmatic policies.
A Study of Quantisation-aware Training on Time Series Transformer Models for Resource-constrained FPGAs
Oct 04, 2023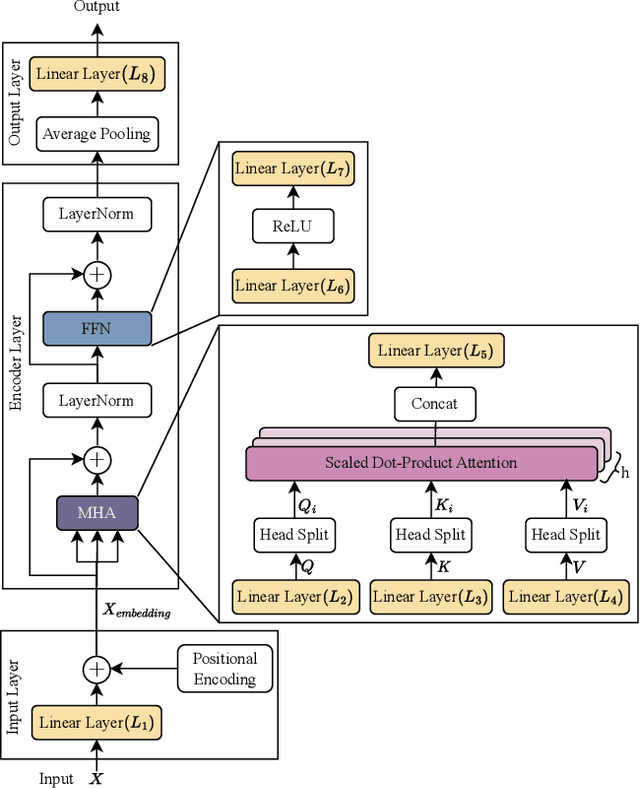
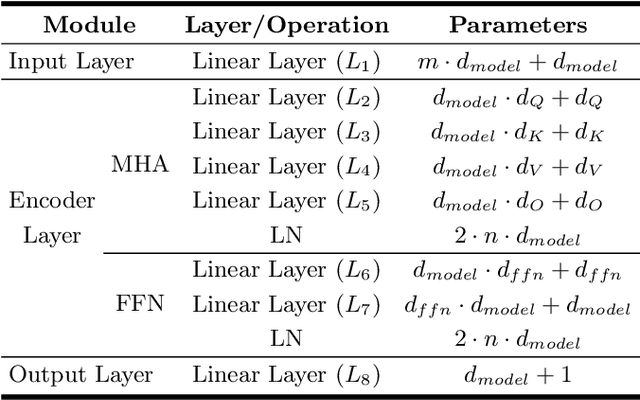


This study explores the quantisation-aware training (QAT) on time series Transformer models. We propose a novel adaptive quantisation scheme that dynamically selects between symmetric and asymmetric schemes during the QAT phase. Our approach demonstrates that matching the quantisation scheme to the real data distribution can reduce computational overhead while maintaining acceptable precision. Moreover, our approach is robust when applied to real-world data and mixed-precision quantisation, where most objects are quantised to 4 bits. Our findings inform model quantisation and deployment decisions while providing a foundation for advancing quantisation techniques.
Test-Time Self-Adaptive Small Language Models for Question Answering
Oct 20, 2023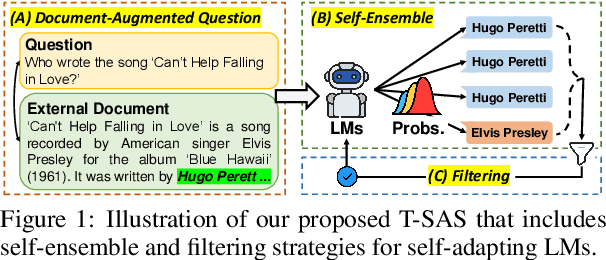
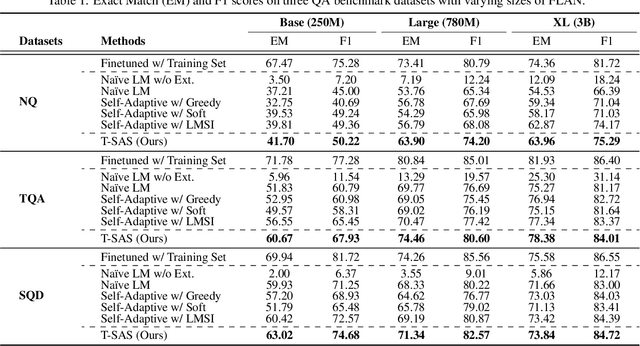
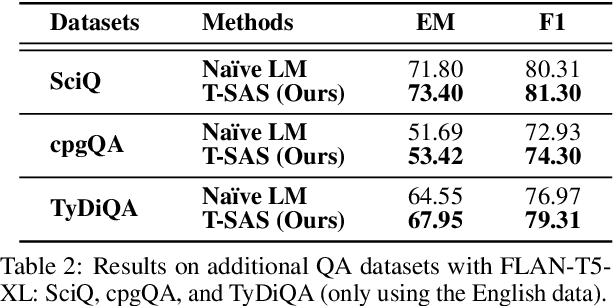
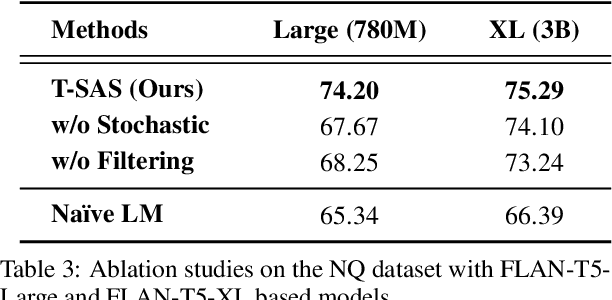
Recent instruction-finetuned large language models (LMs) have achieved notable performances in various tasks, such as question-answering (QA). However, despite their ability to memorize a vast amount of general knowledge across diverse tasks, they might be suboptimal on specific tasks due to their limited capacity to transfer and adapt knowledge to target tasks. Moreover, further finetuning LMs with labeled datasets is often infeasible due to their absence, but it is also questionable if we can transfer smaller LMs having limited knowledge only with unlabeled test data. In this work, we show and investigate the capabilities of smaller self-adaptive LMs, only with unlabeled test data. In particular, we first stochastically generate multiple answers, and then ensemble them while filtering out low-quality samples to mitigate noise from inaccurate labels. Our proposed self-adaption strategy demonstrates significant performance improvements on benchmark QA datasets with higher robustness across diverse prompts, enabling LMs to stay stable. Code is available at: https://github.com/starsuzi/T-SAS.
DPATD: Dual-Phase Audio Transformer for Denoising
Oct 30, 2023Recent high-performance transformer-based speech enhancement models demonstrate that time domain methods could achieve similar performance as time-frequency domain methods. However, time-domain speech enhancement systems typically receive input audio sequences consisting of a large number of time steps, making it challenging to model extremely long sequences and train models to perform adequately. In this paper, we utilize smaller audio chunks as input to achieve efficient utilization of audio information to address the above challenges. We propose a dual-phase audio transformer for denoising (DPATD), a novel model to organize transformer layers in a deep structure to learn clean audio sequences for denoising. DPATD splits the audio input into smaller chunks, where the input length can be proportional to the square root of the original sequence length. Our memory-compressed explainable attention is efficient and converges faster compared to the frequently used self-attention module. Extensive experiments demonstrate that our model outperforms state-of-the-art methods.
Model-based Clustering of Individuals' Ecological Momentary Assessment Time-series Data for Improving Forecasting Performance
Oct 11, 2023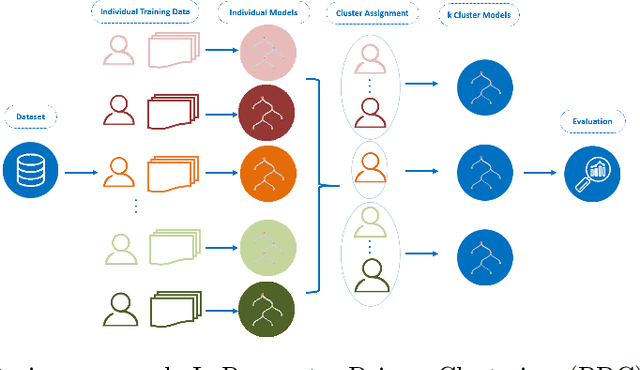
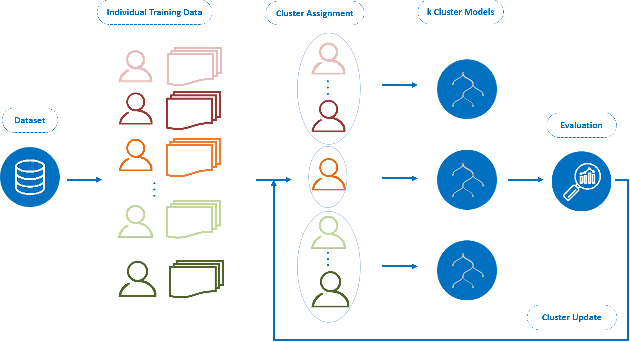
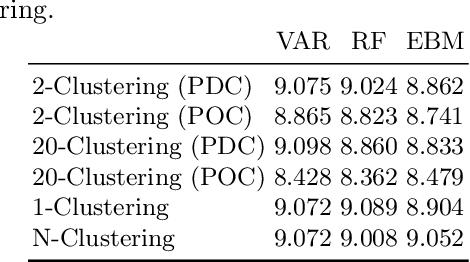
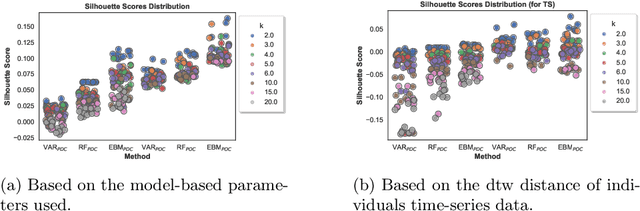
Through Ecological Momentary Assessment (EMA) studies, a number of time-series data is collected across multiple individuals, continuously monitoring various items of emotional behavior. Such complex data is commonly analyzed in an individual level, using personalized models. However, it is believed that additional information of similar individuals is likely to enhance these models leading to better individuals' description. Thus, clustering is investigated with an aim to group together the most similar individuals, and subsequently use this information in group-based models in order to improve individuals' predictive performance. More specifically, two model-based clustering approaches are examined, where the first is using model-extracted parameters of personalized models, whereas the second is optimized on the model-based forecasting performance. Both methods are then analyzed using intrinsic clustering evaluation measures (e.g. Silhouette coefficients) as well as the performance of a downstream forecasting scheme, where each forecasting group-model is devoted to describe all individuals belonging to one cluster. Among these, clustering based on performance shows the best results, in terms of all examined evaluation measures. As another level of evaluation, those group-models' performance is compared to three baseline scenarios, the personalized, the all-in-one group and the random group-based concept. According to this comparison, the superiority of clustering-based methods is again confirmed, indicating that the utilization of group-based information could be effectively enhance the overall performance of all individuals' data.
Shallow learning enables real-time inference of molecular composition changes from broadband-near-infrared spectroscopy of brain tissue
Oct 02, 2023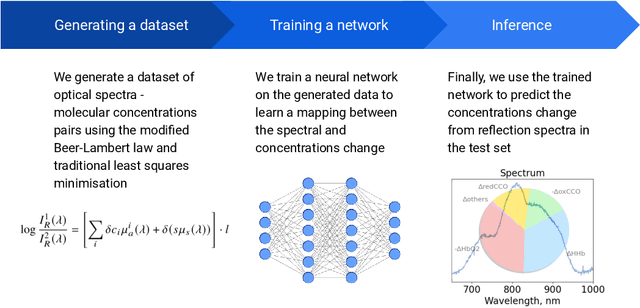
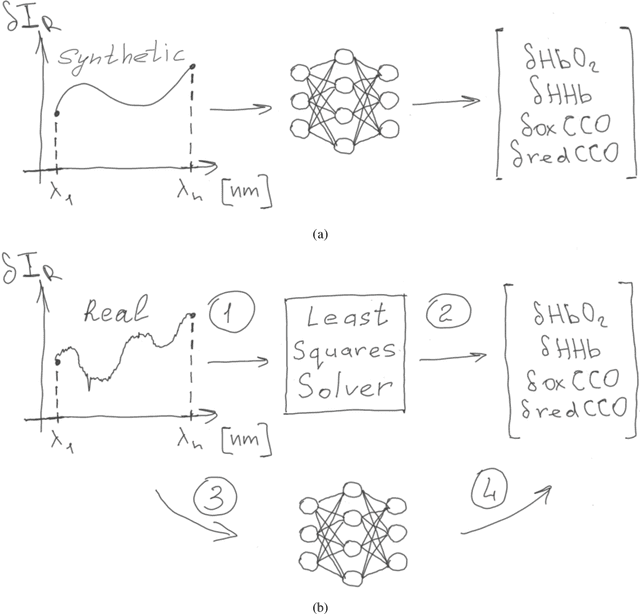
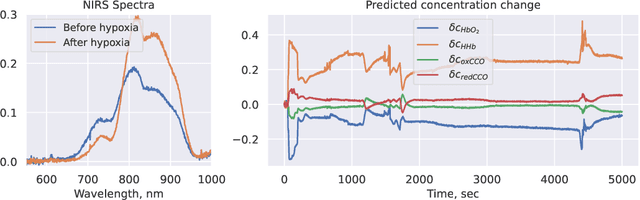
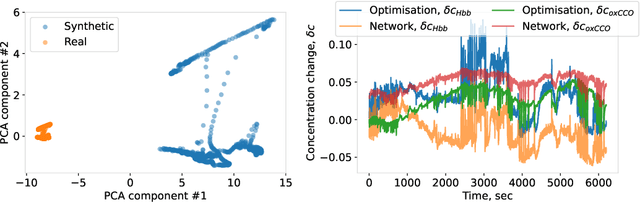
Spectroscopy-based imaging modalities such as near-infrared spectroscopy (NIRS) and hyperspectral imaging (HSI) represent a promising alternative for low-cost, non-invasive, and fast monitoring of functional and structural properties of living tissue. Particularly, the possibility of extracting the molecular composition of the tissue from the optical spectra in real-time deems the spectroscopy techniques as unique diagnostic tools. However, due to the highly limited availability of paired optical and molecular profiling studies, building a mapping between a spectral signature and a corresponding set of molecular concentrations is still an unsolved problem. Moreover, there are no yet established methods to streamline inference of the biochemical composition from the optical spectrum for real-time applications such as surgical monitoring. In this paper, we develop a technique for fast inference of changes in the molecular composition of brain tissue. We base our method on the Beer-Lambert law to analytically connect the spectra with concentrations and use a deep-learning approach to significantly speed up the concentration inference compared to traditional optimization methods. We test our approach on real data obtained from the broadband NIRS study of piglets' brains. The results demonstrate that the proposed method enables real-time molecular composition inference while maintaining the accuracy of traditional optimization.
A Systematic Review for Transformer-based Long-term Series Forecasting
Oct 31, 2023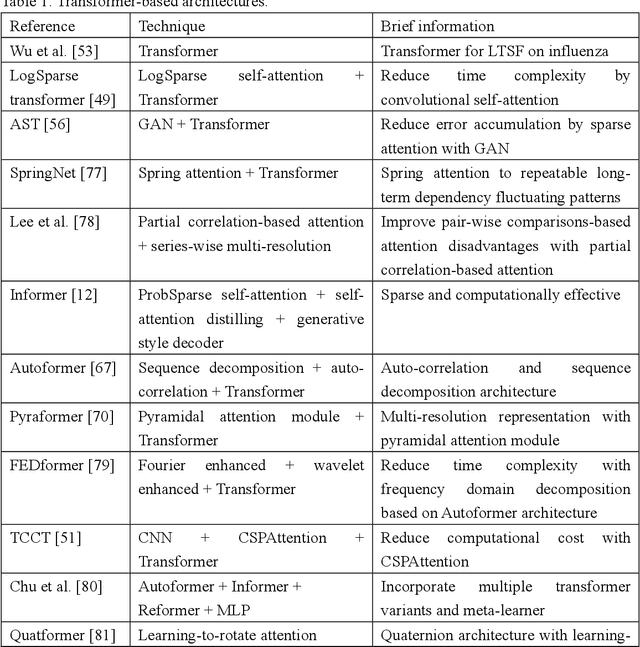
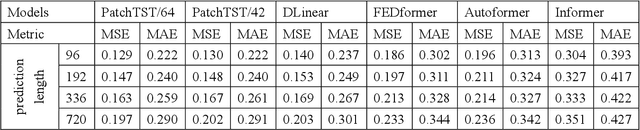

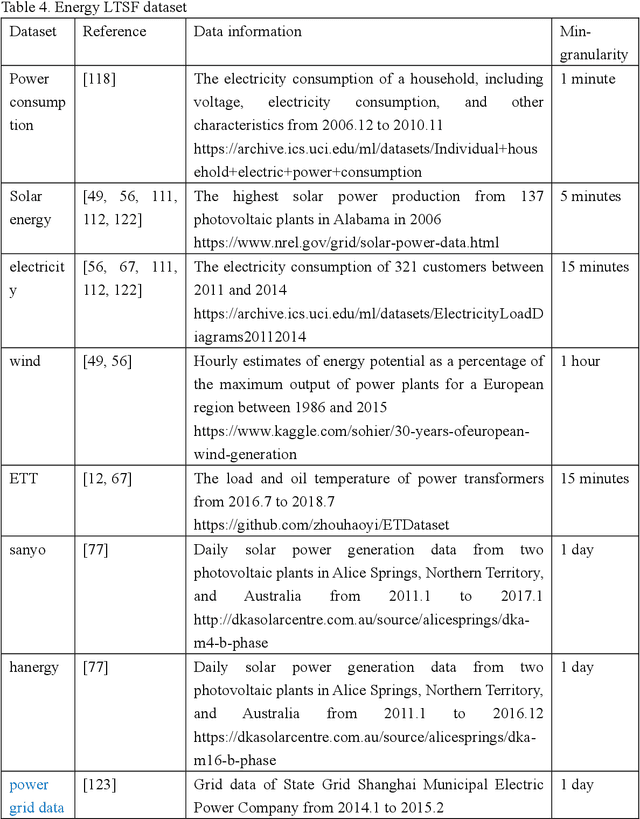
The emergence of deep learning has yielded noteworthy advancements in time series forecasting (TSF). Transformer architectures, in particular, have witnessed broad utilization and adoption in TSF tasks. Transformers have proven to be the most successful solution to extract the semantic correlations among the elements within a long sequence. Various variants have enabled transformer architecture to effectively handle long-term time series forecasting (LTSF) tasks. In this article, we first present a comprehensive overview of transformer architectures and their subsequent enhancements developed to address various LTSF tasks. Then, we summarize the publicly available LTSF datasets and relevant evaluation metrics. Furthermore, we provide valuable insights into the best practices and techniques for effectively training transformers in the context of time-series analysis. Lastly, we propose potential research directions in this rapidly evolving field.