 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sum Rate Maximization under AoI Constraints for RIS-Assisted mmWave Communications
Nov 13, 2023
The concept of age of information (AoI) has been proposed to quantify information freshness, which is crucial for time-sensitive applications. However, in millimeter wave (mmWave) communication systems, the link blockage caused by obstacles and the severe path loss greatly impair the freshness of information received by the user equipments (UEs). In this paper, we focus on reconfigurable intelligent surface (RIS)-assisted mmWave communications, where beamforming is performed at transceivers to provide directional beam gain and a RIS is deployed to combat link blockage. We aim to maximize the system sum rate while satisfying the information freshness requirements of UEs by jointly optimizing the beamforming at transceivers, the discrete RIS reflection coefficients, and the UE scheduling strategy. To facilitate a practical solution, we decompose the problem into two subproblems. For the first per-UE data rate maximization problem, we further decompose it into a beamforming optimization subproblem and a RIS reflection coefficient optimization subproblem. Considering the difficulty of channel estimation, we utilize the hierarchical search method for the former and the local search method for the latter, and then adopt the block coordinate descent (BCD) method to alternately solve them. For the second scheduling strategy design problem, a low-complexity heuristic scheduling algorithm is designed. Simulation results show that the proposed algorithm can effectively improve the system sum rate while satisfying the information freshness requirements of all UEs.
Multi-Sensor Terrestrial SLAM for Real-Time, Large-Scale, and GNSS-Interrupted Forest Mapping
Oct 02, 2023Forests, as critical components of our ecosystem, demand effective monitoring and management. However, conducting real-time forest inventory in large-scale and GNSS-interrupted forest environments has long been a formidable challenge. In this paper, we present a novel solution that leverages robotics and sensor-fusion technologies to overcome these challenges and enable real-time forest inventory with higher accuracy and efficiency. The proposed solution consists of a new SLAM algorithm to create an accurate 3D map of large-scale forest stands with detailed estimation about the number of trees and the corresponding DBH, solely with the consecutive scans of a 3D lidar and an imu. This method utilized a hierarchical unsupervised clustering algorithm to detect the trees and measure the DBH from the lidar point cloud. The algorithm can run simultaneously as the data is being recorded or afterwards on the recorded dataset. Furthermore, due to the proposed fast feature extraction and transform estimation modules, the recorded data can be fed to the SLAM with higher frequency than common SLAM algorithms. The performance of the proposed solution was tested through filed data collection with hand-held sensor platform as well as a mobile forestry robot. The accuracy of the results was also compared to the state-of-the-art SLAM solutions.
Multi-Agent Reinforcement Learning for the Low-Level Control of a Quadrotor UAV
Nov 10, 2023This paper presents multi-agent reinforcement learning frameworks for the low-level control of a quadrotor UAV. While single-agent reinforcement learning has been successfully applied to quadrotors, training a single monolithic network is often data-intensive and time-consuming. To address this, we decompose the quadrotor dynamics into the translational dynamics and the yawing dynamics, and assign a reinforcement learning agent to each part for efficient training and performance improvements. The proposed multi-agent framework for quadrotor low-level control that leverages the underlying structures of the quadrotor dynamics is a unique contribution. Further, we introduce regularization terms to mitigate steady-state errors and to avoid aggressive control inputs. Through benchmark studies with sim-to-sim transfer, it is illustrated that the proposed multi-agent reinforcement learning substantially improves the convergence rate of the training and the stability of the controlled dynamics.
Sum-max Submodular Bandits
Nov 10, 2023Many online decision-making problems correspond to maximizing a sequence of submodular functions. In this work, we introduce sum-max functions, a subclass of monotone submodular functions capturing several interesting problems, including best-of-$K$-bandits, combinatorial bandits, and the bandit versions on facility location, $M$-medians, and hitting sets. We show that all functions in this class satisfy a key property that we call pseudo-concavity. This allows us to prove $\big(1 - \frac{1}{e}\big)$-regret bounds for bandit feedback in the nonstochastic setting of the order of $\sqrt{MKT}$ (ignoring log factors), where $T$ is the time horizon and $M$ is a cardinality constraint. This bound, attained by a simple and efficient algorithm, significantly improves on the $\widetilde{O}\big(T^{2/3}\big)$ regret bound for online monotone submodular maximization with bandit feedback.
DEYOv3: DETR with YOLO for Real-time Object Detection
Sep 22, 2023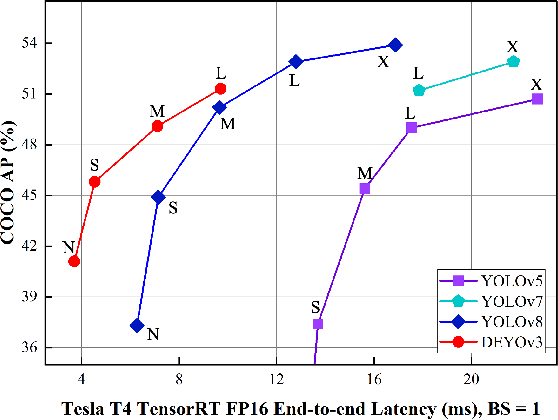
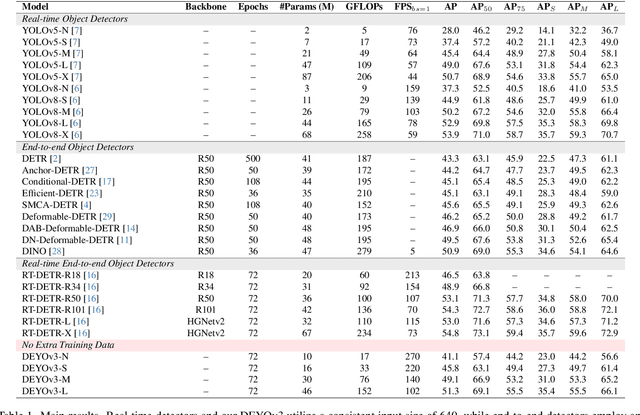


Recently, end-to-end object detectors have gained significant attention from the research community due to their outstanding performance. However, DETR typically relies on supervised pretraining of the backbone on ImageNet, which limits the practical application of DETR and the design of the backbone, affecting the model's potential generalization ability. In this paper, we propose a new training method called step-by-step training. Specifically, in the first stage, the one-to-many pre-trained YOLO detector is used to initialize the end-to-end detector. In the second stage, the backbone and encoder are consistent with the DETR-like model, but only the detector needs to be trained from scratch. Due to this training method, the object detector does not need the additional dataset (ImageNet) to train the backbone, which makes the design of the backbone more flexible and dramatically reduces the training cost of the detector, which is helpful for the practical application of the object detector. At the same time, compared with the DETR-like model, the step-by-step training method can achieve higher accuracy than the traditional training method of the DETR-like model. With the aid of this novel training method, we propose a brand-new end-to-end real-time object detection model called DEYOv3. DEYOv3-N achieves 41.1% on COCO val2017 and 270 FPS on T4 GPU, while DEYOv3-L achieves 51.3% AP and 102 FPS. Without the use of additional training data, DEYOv3 surpasses all existing real-time object detectors in terms of both speed and accuracy. It is worth noting that for models of N, S, and M scales, the training on the COCO dataset can be completed using a single 24GB RTX3090 GPU. Code will be released at https://github.com/ouyanghaodong/DEYOv3.
Finite Time Analysis of Constrained Actor Critic and Constrained Natural Actor Critic Algorithms
Oct 25, 2023Actor Critic methods have found immense applications on a wide range of Reinforcement Learning tasks especially when the state-action space is large. In this paper, we consider actor critic and natural actor critic algorithms with function approximation for constrained Markov decision processes (C-MDP) involving inequality constraints and carry out a non-asymptotic analysis for both of these algorithms in a non-i.i.d (Markovian) setting. We consider the long-run average cost criterion where both the objective and the constraint functions are suitable policy-dependent long-run averages of certain prescribed cost functions. We handle the inequality constraints using the Lagrange multiplier method. We prove that these algorithms are guaranteed to find a first-order stationary point (i.e., $\Vert \nabla L(\theta,\gamma)\Vert_2^2 \leq \epsilon$) of the performance (Lagrange) function $L(\theta,\gamma)$, with a sample complexity of $\mathcal{\tilde{O}}(\epsilon^{-2.5})$ in the case of both Constrained Actor Critic (C-AC) and Constrained Natural Actor Critic (C-NAC) algorithms.We also show the results of experiments on a few different grid world settings and observe good empirical performance using both of these algorithms. In particular, for large grid sizes, Constrained Natural Actor Critic shows slightly better results than Constrained Actor Critic while the latter is slightly better for a small grid size.
IR-UWB Radar-based Situational Awareness System for Smartphone-Distracted Pedestrians
Nov 02, 2023With the widespread adoption of smartphones, ensuring pedestrian safety on roads has become a critical concern due to smartphone distraction. This paper proposes a novel and real-time assistance system called UWB-assisted Safe Walk (UASW) for obstacle detection and warns users about real-time situations. The proposed method leverages Impulse Radio Ultra-Wideband (IR-UWB) radar embedded in the smartphone, which provides excellent range resolution and high noise resilience using short pulses. We implemented UASW specifically for Android smartphones with IR-UWB connectivity. The framework uses complex Channel Impulse Response (CIR) data to integrate rule-based obstacle detection with artificial neural network (ANN) based obstacle classification. The performance of the proposed UASW system is analyzed using real-time collected data. The results show that the proposed system achieves an obstacle detection accuracy of up to 97% and obstacle classification accuracy of up to 95% with an inference delay of 26.8 ms. The results highlight the effectiveness of UASW in assisting smartphone-distracted pedestrians and improving their situational awareness.
Topology of Surface Electromyogram Signals: Hand Gesture Decoding on Riemannian Manifolds
Nov 14, 2023Decoding gestures from the upper limb using noninvasive surface electromyogram (sEMG) signals is of keen interest for the rehabilitation of amputees, artificial supernumerary limb augmentation, gestural control of computers, and virtual/augmented realities. We show that sEMG signals recorded across an array of sensor electrodes in multiple spatial locations around the forearm evince a rich geometric pattern of global motor unit (MU) activity that can be leveraged to distinguish different hand gestures. We demonstrate a simple technique to analyze spatial patterns of muscle MU activity within a temporal window and show that distinct gestures can be classified in both supervised and unsupervised manners. Specifically, we construct symmetric positive definite (SPD) covariance matrices to represent the spatial distribution of MU activity in a time window of interest, calculated as pairwise covariance of electrical signals measured across different electrodes. This allows us to understand and manipulate multivariate sEMG timeseries on a more natural subspace -the Riemannian manifold. Furthermore, it directly addresses signal variability across individuals and sessions, which remains a major challenge in the field. sEMG signals measured at a single electrode lack contextual information such as how various anatomical and physiological factors influence the signals and how their combined effect alters the evident interaction among neighboring muscles. As we show here, analyzing spatial patterns using covariance matrices on Riemannian manifolds allows us to robustly model complex interactions across spatially distributed MUs and provides a flexible and transparent framework to quantify differences in sEMG signals across individuals. The proposed method is novel in the study of sEMG signals and its performance exceeds the current benchmarks while maintaining exceptional computational efficiency.
Instant3D: Instant Text-to-3D Generation
Nov 14, 2023Text-to-3D generation, which aims to synthesize vivid 3D objects from text prompts, has attracted much attention from the computer vision community. While several existing works have achieved impressive results for this task, they mainly rely on a time-consuming optimization paradigm. Specifically, these methods optimize a neural field from scratch for each text prompt, taking approximately one hour or more to generate one object. This heavy and repetitive training cost impedes their practical deployment. In this paper, we propose a novel framework for fast text-to-3D generation, dubbed Instant3D. Once trained, Instant3D is able to create a 3D object for an unseen text prompt in less than one second with a single run of a feedforward network. We achieve this remarkable speed by devising a new network that directly constructs a 3D triplane from a text prompt. The core innovation of our Instant3D lies in our exploration of strategies to effectively inject text conditions into the network. Furthermore, we propose a simple yet effective activation function, the scaled-sigmoid, to replace the original sigmoid function, which speeds up the training convergence by more than ten times. Finally, to address the Janus (multi-head) problem in 3D generation, we propose an adaptive Perp-Neg algorithm that can dynamically adjust its concept negation scales according to the severity of the Janus problem during training, effectively reducing the multi-head effect. Extensive experiments on a wide variety of benchmark datasets demonstrate that the proposed algorithm performs favorably against the state-of-the-art methods both qualitatively and quantitatively, while achieving significantly better efficiency. The project page is at https://ming1993li.github.io/Instant3DProj.
Mobility-Induced Graph Learning for WiFi Positioning
Nov 14, 2023A smartphone-based user mobility tracking could be effective in finding his/her location, while the unpredictable error therein due to low specification of built-in inertial measurement units (IMUs) rejects its standalone usage but demands the integration to another positioning technique like WiFi positioning. This paper aims to propose a novel integration technique using a graph neural network called Mobility-INduced Graph LEarning (MINGLE), which is designed based on two types of graphs made by capturing different user mobility features. Specifically, considering sequential measurement points (MPs) as nodes, a user's regular mobility pattern allows us to connect neighbor MPs as edges, called time-driven mobility graph (TMG). Second, a user's relatively straight transition at a constant pace when moving from one position to another can be captured by connecting the nodes on each path, called a direction-driven mobility graph (DMG). Then, we can design graph convolution network (GCN)-based cross-graph learning, where two different GCN models for TMG and DMG are jointly trained by feeding different input features created by WiFi RTTs yet sharing their weights. Besides, the loss function includes a mobility regularization term such that the differences between adjacent location estimates should be less variant due to the user's stable moving pace. Noting that the regularization term does not require ground-truth location, MINGLE can be designed under semi- and self-supervised learning frameworks. The proposed MINGLE's effectiveness is extensively verified through field experiments, showing a better positioning accuracy than benchmarks, say root mean square errors (RMSEs) being 1.398 (m) and 1.073 (m) for self- and semi-supervised learning cases, respectively.