 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Clustering of Urban Traffic Patterns by K-Means and Dynamic Time Warping: Case Study
Sep 18, 2023
Clustering of urban traffic patterns is an essential task in many different areas of traffic management and planning. In this paper, two significant applications in the clustering of urban traffic patterns are described. The first application estimates the missing speed values using the speed of road segments with similar traffic patterns to colorify map tiles. The second one is the estimation of essential road segments for generating addresses for a local point on the map, using the similarity patterns of different road segments. The speed time series extracts the traffic pattern in different road segments. In this paper, we proposed the time series clustering algorithm based on K-Means and Dynamic Time Warping. The case study of our proposed algorithm is based on the Snapp application's driver speed time series data. The results of the two applications illustrate that the proposed method can extract similar urban traffic patterns.
Preliminary Analysis on Second-Order Convergence for Biased Policy Gradient Methods
Nov 05, 2023Although the convergence of policy gradient algorithms to first-order stationary points is well-established, the objective functions of reinforcement learning problems are typically highly nonconvex. Therefore, recent work has focused on two extensions: ``global" convergence guarantees under regularity assumptions on the function structure, and second-order guarantees for escaping saddle points and convergence to true local minima. Our work expands on the latter approach, avoiding the restrictive assumptions of the former that may not apply to general objective functions. Existing results on vanilla policy gradient only consider an unbiased gradient estimator, but practical implementations under the infinite-horizon discounted setting, including both Monte-Carlo methods and actor-critic methods, involve gradient descent updates with a biased gradient estimator. We present preliminary results on the convergence of biased policy gradient algorithms to second-order stationary points, leveraging proof techniques from nonconvex optimization. In our next steps we aim to provide the first finite-time second-order convergence analysis for actor-critic algorithms.
Newvision: application for helping blind people using deep learning
Nov 05, 2023As able-bodied people, we often take our vision for granted. For people who are visually impaired, however, their disability can have a significant impact on their daily lives. We are developing proprietary headgear that will help visually impaired people navigate their surroundings, identify objects and people, read text, and avoid obstacles. The headgear will use a combination of computer vision, distance estimation with ultrasonic sensors, voice recognition, and voice assistants to provide users with real-time information about their environment. Users will be able to interact with the headgear through voice commands, such as ''What is that?'' to identify an object or ''Navigate to the front door'' to find their way around. The headgear will then provide the user with a verbal description of the object or spoken navigation instructions. We believe that this headgear has the potential to make a significant difference in the lives of visually impaired people, allowing them to live more independently and participate more fully in society.
VR-NeRF: High-Fidelity Virtualized Walkable Spaces
Nov 05, 2023We present an end-to-end system for the high-fidelity capture, model reconstruction, and real-time rendering of walkable spaces in virtual reality using neural radiance fields. To this end, we designed and built a custom multi-camera rig to densely capture walkable spaces in high fidelity and with multi-view high dynamic range images in unprecedented quality and density. We extend instant neural graphics primitives with a novel perceptual color space for learning accurate HDR appearance, and an efficient mip-mapping mechanism for level-of-detail rendering with anti-aliasing, while carefully optimizing the trade-off between quality and speed. Our multi-GPU renderer enables high-fidelity volume rendering of our neural radiance field model at the full VR resolution of dual 2K$\times$2K at 36 Hz on our custom demo machine. We demonstrate the quality of our results on our challenging high-fidelity datasets, and compare our method and datasets to existing baselines. We release our dataset on our project website.
SMURF-THP: Score Matching-based UnceRtainty quantiFication for Transformer Hawkes Process
Oct 25, 2023Transformer Hawkes process models have shown to be successful in modeling event sequence data. However, most of the existing training methods rely on maximizing the likelihood of event sequences, which involves calculating some intractable integral. Moreover, the existing methods fail to provide uncertainty quantification for model predictions, e.g., confidence intervals for the predicted event's arrival time. To address these issues, we propose SMURF-THP, a score-based method for learning Transformer Hawkes process and quantifying prediction uncertainty. Specifically, SMURF-THP learns the score function of events' arrival time based on a score-matching objective that avoids the intractable computation. With such a learned score function, we can sample arrival time of events from the predictive distribution. This naturally allows for the quantification of uncertainty by computing confidence intervals over the generated samples. We conduct extensive experiments in both event type prediction and uncertainty quantification of arrival time. In all the experiments, SMURF-THP outperforms existing likelihood-based methods in confidence calibration while exhibiting comparable prediction accuracy.
APRICOT: Acuity Prediction in Intensive Care Unit (ICU): Predicting Stability, Transitions, and Life-Sustaining Therapies
Nov 03, 2023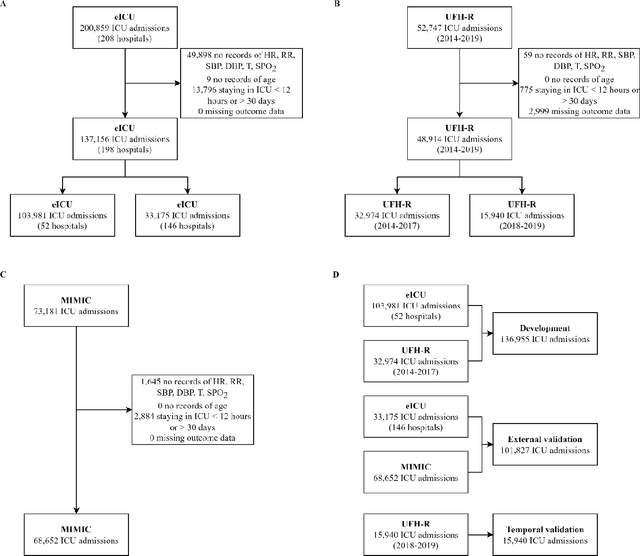
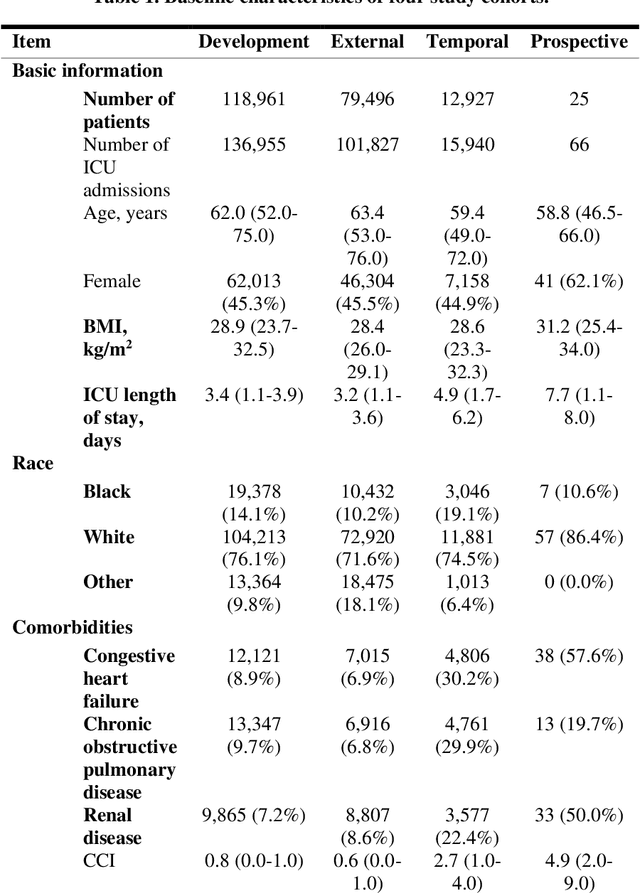
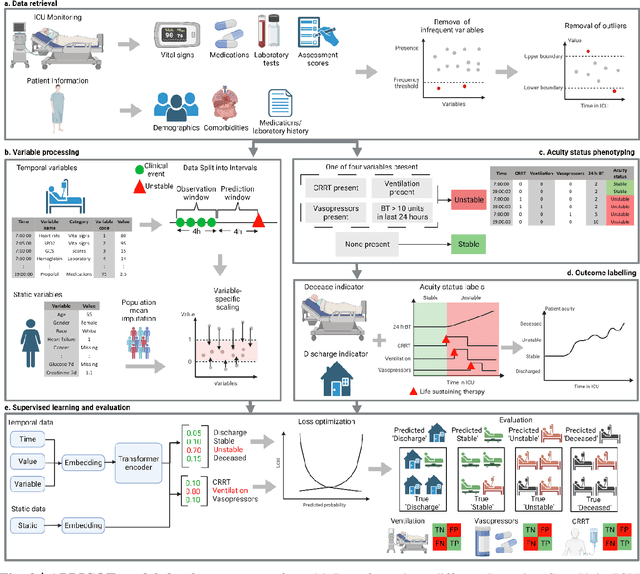
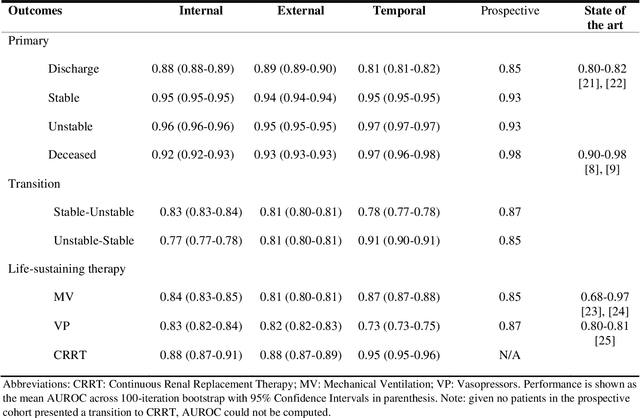
The acuity state of patients in the intensive care unit (ICU) can quickly change from stable to unstable, sometimes leading to life-threatening conditions. Early detection of deteriorating conditions can result in providing more timely interventions and improved survival rates. Current approaches rely on manual daily assessments. Some data-driven approaches have been developed, that use mortality as a proxy of acuity in the ICU. However, these methods do not integrate acuity states to determine the stability of a patient or the need for life-sustaining therapies. In this study, we propose APRICOT (Acuity Prediction in Intensive Care Unit), a Transformer-based neural network to predict acuity state in real-time in ICU patients. We develop and extensively validate externally, temporally, and prospectively the APRICOT model on three large datasets: University of Florida Health (UFH), eICU Collaborative Research Database (eICU), and Medical Information Mart for Intensive Care (MIMIC)-IV. The performance of APRICOT shows comparable results to state-of-the-art mortality prediction models (external AUROC 0.93-0.93, temporal AUROC 0.96-0.98, and prospective AUROC 0.98) as well as acuity prediction models (external AUROC 0.80-0.81, temporal AUROC 0.77-0.78, and prospective AUROC 0.87). Furthermore, APRICOT can make predictions for the need for life-sustaining therapies, showing comparable results to state-of-the-art ventilation prediction models (external AUROC 0.80-0.81, temporal AUROC 0.87-0.88, and prospective AUROC 0.85), and vasopressor prediction models (external AUROC 0.82-0.83, temporal AUROC 0.73-0.75, prospective AUROC 0.87). This tool allows for real-time acuity monitoring of a patient and can provide helpful information to clinicians to make timely interventions. Furthermore, the model can suggest life-sustaining therapies that the patient might need in the next hours in the ICU.
Time-to-Pattern: Information-Theoretic Unsupervised Learning for Scalable Time Series Summarization
Aug 26, 2023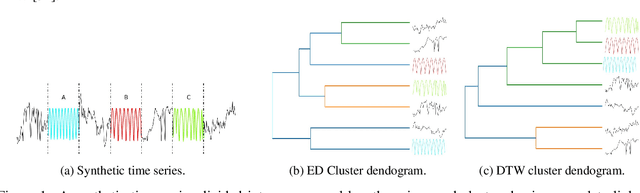
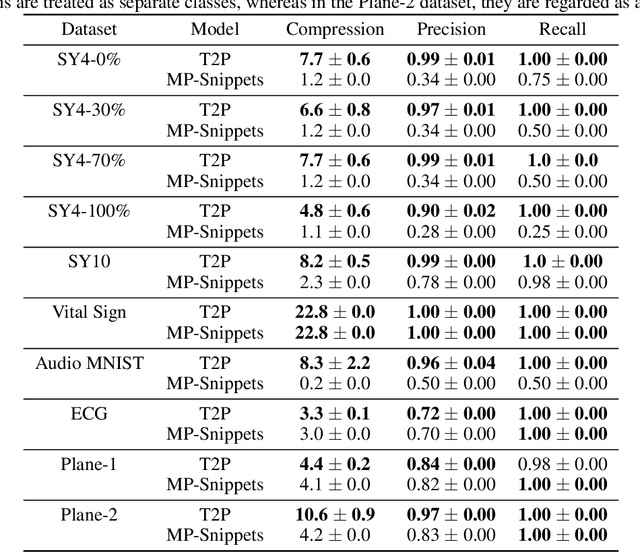
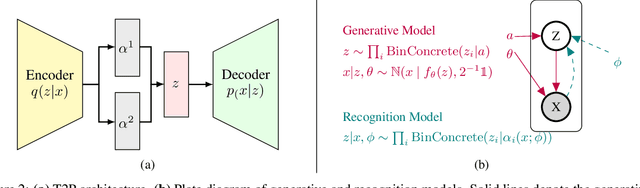

Data summarization is the process of generating interpretable and representative subsets from a dataset. Existing time series summarization approaches often search for recurring subsequences using a set of manually devised similarity functions to summarize the data. However, such approaches are fraught with limitations stemming from an exhaustive search coupled with a heuristic definition of series similarity. Such approaches affect the diversity and comprehensiveness of the generated data summaries. To mitigate these limitations, we introduce an approach to time series summarization, called Time-to-Pattern (T2P), which aims to find a set of diverse patterns that together encode the most salient information, following the notion of minimum description length. T2P is implemented as a deep generative model that learns informative embeddings of the discrete time series on a latent space specifically designed to be interpretable. Our synthetic and real-world experiments reveal that T2P discovers informative patterns, even in noisy and complex settings. Furthermore, our results also showcase the improved performance of T2P over previous work in pattern diversity and processing scalability, which conclusively demonstrate the algorithm's effectiveness for time series summarization.
VET: Visual Error Tomography for Point Cloud Completion and High-Quality Neural Rendering
Nov 08, 2023In the last few years, deep neural networks opened the doors for big advances in novel view synthesis. Many of these approaches are based on a (coarse) proxy geometry obtained by structure from motion algorithms. Small deficiencies in this proxy can be fixed by neural rendering, but larger holes or missing parts, as they commonly appear for thin structures or for glossy regions, still lead to distracting artifacts and temporal instability. In this paper, we present a novel neural-rendering-based approach to detect and fix such deficiencies. As a proxy, we use a point cloud, which allows us to easily remove outlier geometry and to fill in missing geometry without complicated topological operations. Keys to our approach are (i) a differentiable, blending point-based renderer that can blend out redundant points, as well as (ii) the concept of Visual Error Tomography (VET), which allows us to lift 2D error maps to identify 3D-regions lacking geometry and to spawn novel points accordingly. Furthermore, (iii) by adding points as nested environment maps, our approach allows us to generate high-quality renderings of the surroundings in the same pipeline. In our results, we show that our approach can improve the quality of a point cloud obtained by structure from motion and thus increase novel view synthesis quality significantly. In contrast to point growing techniques, the approach can also fix large-scale holes and missing thin structures effectively. Rendering quality outperforms state-of-the-art methods and temporal stability is significantly improved, while rendering is possible at real-time frame rates.
FreeNoise: Tuning-Free Longer Video Diffusion via Noise Rescheduling
Oct 27, 2023With the availability of large-scale video datasets and the advances of diffusion models, text-driven video generation has achieved substantial progress. However, existing video generation models are typically trained on a limited number of frames, resulting in the inability to generate high-fidelity long videos during inference. Furthermore, these models only support single-text conditions, whereas real-life scenarios often require multi-text conditions as the video content changes over time. To tackle these challenges, this study explores the potential of extending the text-driven capability to generate longer videos conditioned on multiple texts. 1) We first analyze the impact of initial noise in video diffusion models. Then building upon the observation of noise, we propose FreeNoise, a tuning-free and time-efficient paradigm to enhance the generative capabilities of pretrained video diffusion models while preserving content consistency. Specifically, instead of initializing noises for all frames, we reschedule a sequence of noises for long-range correlation and perform temporal attention over them by window-based function. 2) Additionally, we design a novel motion injection method to support the generation of videos conditioned on multiple text prompts. Extensive experiments validate the superiority of our paradigm in extending the generative capabilities of video diffusion models. It is noteworthy that compared with the previous best-performing method which brought about 255% extra time cost, our method incurs only negligible time cost of approximately 17%. Generated video samples are available at our website: http://haonanqiu.com/projects/FreeNoise.html.
Signal Processing Meets SGD: From Momentum to Filter
Nov 06, 2023In the field of deep learning, Stochastic Gradient Descent (SGD) and its momentum-based variants are the predominant choices for optimization algorithms. Despite all that, these momentum strategies, which accumulate historical gradients by using a fixed $\beta$ hyperparameter to smooth the optimization processing, often neglect the potential impact of the variance of historical gradients on the current gradient estimation. In the gradient variance during training, fluctuation indicates the objective function does not meet the Lipschitz continuity condition at all time, which raises the troublesome optimization problem. This paper aims to explore the potential benefits of reducing the variance of historical gradients to make optimizer converge to flat solutions. Moreover, we proposed a new optimization method based on reducing the variance. We employed the Wiener filter theory to enhance the first moment estimation of SGD, notably introducing an adaptive weight to optimizer. Specifically, the adaptive weight dynamically changes along with temporal fluctuation of gradient variance during deep learning model training. Experimental results demonstrated our proposed adaptive weight optimizer, SGDF (Stochastic Gradient Descent With Filter), can achieve satisfactory performance compared with state-of-the-art optimizers.