 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fleet Sizing for the Flash Delivery Problem from Multiple Depots a Case Study in Amsterdam
Nov 07, 2023
In this paper, we present a novel approach for fleet sizing in the context of flash delivery, a time-sensitive delivery service that requires the fulfilment of customer requests in minutes. Our approach effectively combines individual delivery requests into groups and generates optimized operational plans that can be executed by a single vehicle or autonomous robot. The groups are formed using a modified routing approach for the flash delivery problem. Combining the groups into operational plans is done by solving an integer linear problem. To evaluate the effectiveness of our approach, we compare it against three alternative methods: fixed vehicle routing, non-pooled deliveries and a strategy encouraging the pooling of requests. The results demonstrate the value of our proposed approach, showcasing its ability to optimize the fleet and improve operational efficiency. Our experimental analysis is based on a real-world dataset provided by a Dutch retailer, allowing us to gain valuable insights into the design of flash delivery operations and to analyze the effect of the maximum allowed delay, the number of stores to pick up goods from and the employed cost functions.
Meta-Adapter: An Online Few-shot Learner for Vision-Language Model
Nov 07, 2023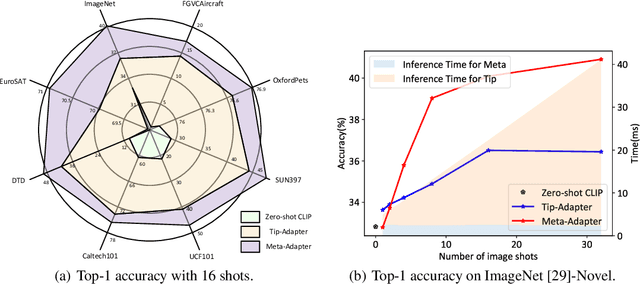
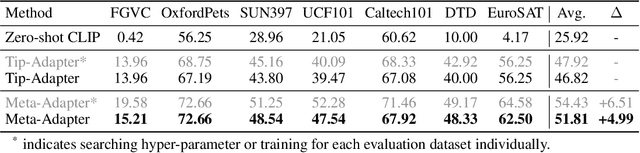
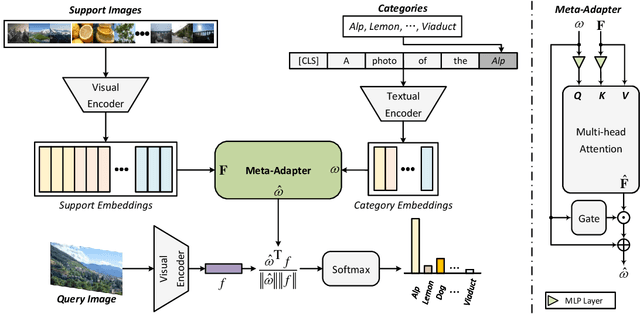
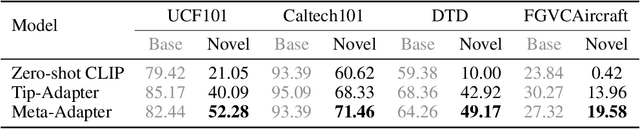
The contrastive vision-language pre-training, known as CLIP, demonstrates remarkable potential in perceiving open-world visual concepts, enabling effective zero-shot image recognition. Nevertheless, few-shot learning methods based on CLIP typically require offline fine-tuning of the parameters on few-shot samples, resulting in longer inference time and the risk of over-fitting in certain domains. To tackle these challenges, we propose the Meta-Adapter, a lightweight residual-style adapter, to refine the CLIP features guided by the few-shot samples in an online manner. With a few training samples, our method can enable effective few-shot learning capabilities and generalize to unseen data or tasks without additional fine-tuning, achieving competitive performance and high efficiency. Without bells and whistles, our approach outperforms the state-of-the-art online few-shot learning method by an average of 3.6\% on eight image classification datasets with higher inference speed. Furthermore, our model is simple and flexible, serving as a plug-and-play module directly applicable to downstream tasks. Without further fine-tuning, Meta-Adapter obtains notable performance improvements in open-vocabulary object detection and segmentation tasks.
Model-Free Source Seeking by a Novel Single-Integrator with Attenuating Oscillations and Better Convergence: Robotic Experiments
Nov 07, 2023The classic extremum seeking control (ESC) system has been used, including in experiments, for over a decade as a mean for model-free, real-time method to steer systems, such as mobile robots, to the source of a scalar physical distribution (signal) using only local measurements of said signal. This is referred to in literature as the (source seeking) problem. Similarly, control-affine ESC systems, which are simpler in structure such as single-integrator, have been used for source seeking as well; however, they were rarely experimented on. Both classic ESC and control-affine ESC methods suffer from persistent oscillations even after the system approaches the source they are seeking. In this paper, we implement, and verify by novel robotic experiments, recent results on control-affine ESC, which enable source seeking with attenuating oscillations. We propose a simple, amended single-integrator design which we use in our experiments. The experiments were conducted for a light source seeking problem. Results imply that the proposed design has significant potential as it also demonstrated much better convergence. We hope this paper encourages expansion of the proposed design in other fields, problems and experiments.
Co-training and Co-distillation for Quality Improvement and Compression of Language Models
Nov 07, 2023Knowledge Distillation (KD) compresses computationally expensive pre-trained language models (PLMs) by transferring their knowledge to smaller models, allowing their use in resource-constrained or real-time settings. However, most smaller models fail to surpass the performance of the original larger model, resulting in sacrificing performance to improve inference speed. To address this issue, we propose Co-Training and Co-Distillation (CTCD), a novel framework that improves performance and inference speed together by co-training two models while mutually distilling knowledge. The CTCD framework successfully achieves this based on two significant findings: 1) Distilling knowledge from the smaller model to the larger model during co-training improves the performance of the larger model. 2) The enhanced performance of the larger model further boosts the performance of the smaller model. The CTCD framework shows promise as it can be combined with existing techniques like architecture design or data augmentation, replacing one-way KD methods, to achieve further performance improvement. Extensive ablation studies demonstrate the effectiveness of CTCD, and the small model distilled by CTCD outperforms the original larger model by a significant margin of 1.66 on the GLUE benchmark.
Rethinking Residual Connection in Training Large-Scale Spiking Neural Networks
Nov 09, 2023Spiking Neural Network (SNN) is known as the most famous brain-inspired model, but the non-differentiable spiking mechanism makes it hard to train large-scale SNNs. To facilitate the training of large-scale SNNs, many training methods are borrowed from Artificial Neural Networks (ANNs), among which deep residual learning is the most commonly used. But the unique features of SNNs make prior intuition built upon ANNs not available for SNNs. Although there are a few studies that have made some pioneer attempts on the topology of Spiking ResNet, the advantages of different connections remain unclear. To tackle this issue, we analyze the merits and limitations of various residual connections and empirically demonstrate our ideas with extensive experiments. Then, based on our observations, we abstract the best-performing connections into densely additive (DA) connection, extend such a concept to other topologies, and propose four architectures for training large-scale SNNs, termed DANet, which brings up to 13.24% accuracy gain on ImageNet. Besides, in order to present a detailed methodology for designing the topology of large-scale SNNs, we further conduct in-depth discussions on their applicable scenarios in terms of their performance on various scales of datasets and demonstrate their advantages over prior architectures. At a low training expense, our best-performing ResNet-50/101/152 obtain 73.71%/76.13%/77.22% top-1 accuracy on ImageNet with 4 time steps. We believe that this work shall give more insights for future works to design the topology of their networks and promote the development of large-scale SNNs. The code will be publicly available.
Deep Learning Architecture for Network-Efficiency at the Edge
Nov 09, 2023The growing number of AI-driven applications in the mobile devices has led to solutions that integrate deep learning models with the available edge-cloud resources; due to multiple benefits such as reduction in on-device energy consumption, improved latency, improved network usage, and certain privacy improvements, split learning, where deep learning models are split away from the mobile device and computed in a distributed manner, has become an extensively explored topic. Combined with compression-aware methods where learning adapts to compression of communicated data, the benefits of this approach have further improved and could serve as an alternative to established approaches like federated learning methods. In this work, we develop an adaptive compression-aware split learning method ('deprune') to improve and train deep learning models so that they are much more network-efficient (use less network resources and are faster), which would make them ideal to deploy in weaker devices with the help of edge-cloud resources. This method is also extended ('prune') to very quickly train deep learning models, through a transfer learning approach, that trades off little accuracy for much more network-efficient inference abilities. We show that the 'deprune' method can reduce network usage by 4x when compared with a split-learning approach (that does not use our method) without loss of accuracy, while also improving accuracy over compression-aware split-learning by 4 percent. Lastly, we show that the 'prune' method can reduce the training time for certain models by up to 6x without affecting the accuracy when compared against a compression-aware split-learning approach.
FMViT: A multiple-frequency mixing Vision Transformer
Nov 09, 2023The transformer model has gained widespread adoption in computer vision tasks in recent times. However, due to the quadratic time and memory complexity of self-attention, which is proportional to the number of input tokens, most existing Vision Transformers (ViTs) encounter challenges in achieving efficient performance in practical industrial deployment scenarios, such as TensorRT and CoreML, where traditional CNNs excel. Although some recent attempts have been made to design CNN-Transformer hybrid architectures to tackle this problem, their overall performance has not met expectations. To tackle these challenges, we propose an efficient hybrid ViT architecture named FMViT. This approach enhances the model's expressive power by blending high-frequency features and low-frequency features with varying frequencies, enabling it to capture both local and global information effectively. Additionally, we introduce deploy-friendly mechanisms such as Convolutional Multigroup Reparameterization (gMLP), Lightweight Multi-head Self-Attention (RLMHSA), and Convolutional Fusion Block (CFB) to further improve the model's performance and reduce computational overhead. Our experiments demonstrate that FMViT surpasses existing CNNs, ViTs, and CNNTransformer hybrid architectures in terms of latency/accuracy trade-offs for various vision tasks. On the TensorRT platform, FMViT outperforms Resnet101 by 2.5% (83.3% vs. 80.8%) in top-1 accuracy on the ImageNet dataset while maintaining similar inference latency. Moreover, FMViT achieves comparable performance with EfficientNet-B5, but with a 43% improvement in inference speed. On CoreML, FMViT outperforms MobileOne by 2.6% in top-1 accuracy on the ImageNet dataset, with inference latency comparable to MobileOne (78.5% vs. 75.9%). Our code can be found at https://github.com/tany0699/FMViT.
Leveraging Artificial Intelligence Technology for Mapping Research to Sustainable Development Goals: A Case Study
Nov 09, 2023The number of publications related to the Sustainable Development Goals (SDGs) continues to grow. These publications cover a diverse spectrum of research, from humanities and social sciences to engineering and health. Given the imperative of funding bodies to monitor outcomes and impacts, linking publications to relevant SDGs is critical but remains time-consuming and difficult given the breadth and complexity of the SDGs. A publication may relate to several goals (interconnection feature of goals), and therefore require multidisciplinary knowledge to tag accurately. Machine learning approaches are promising and have proven particularly valuable for tasks such as manual data labeling and text classification. In this study, we employed over 82,000 publications from an Australian university as a case study. We utilized a similarity measure to map these publications onto Sustainable Development Goals (SDGs). Additionally, we leveraged the OpenAI GPT model to conduct the same task, facilitating a comparative analysis between the two approaches. Experimental results show that about 82.89% of the results obtained by the similarity measure overlap (at least one tag) with the outputs of the GPT model. The adopted model (similarity measure) can complement GPT model for SDG classification. Furthermore, deep learning methods, which include the similarity measure used here, are more accessible and trusted for dealing with sensitive data without the use of commercial AI services or the deployment of expensive computing resources to operate large language models. Our study demonstrates how a crafted combination of the two methods can achieve reliable results for mapping research to the SDGs.
Hashing Neural Video Decomposition with Multiplicative Residuals in Space-Time
Sep 25, 2023We present a video decomposition method that facilitates layer-based editing of videos with spatiotemporally varying lighting and motion effects. Our neural model decomposes an input video into multiple layered representations, each comprising a 2D texture map, a mask for the original video, and a multiplicative residual characterizing the spatiotemporal variations in lighting conditions. A single edit on the texture maps can be propagated to the corresponding locations in the entire video frames while preserving other contents' consistencies. Our method efficiently learns the layer-based neural representations of a 1080p video in 25s per frame via coordinate hashing and allows real-time rendering of the edited result at 71 fps on a single GPU. Qualitatively, we run our method on various videos to show its effectiveness in generating high-quality editing effects. Quantitatively, we propose to adopt feature-tracking evaluation metrics for objectively assessing the consistency of video editing. Project page: https://lightbulb12294.github.io/hashing-nvd/
Rule Learning as Machine Translation using the Atomic Knowledge Bank
Nov 05, 2023Machine learning models, and in particular language models, are being applied to various tasks that require reasoning. While such models are good at capturing patterns their ability to reason in a trustable and controlled manner is frequently questioned. On the other hand, logic-based rule systems allow for controlled inspection and already established verification methods. However it is well-known that creating such systems manually is time-consuming and prone to errors. We explore the capability of transformers to translate sentences expressing rules in natural language into logical rules. We see reasoners as the most reliable tools for performing logical reasoning and focus on translating language into the format expected by such tools. We perform experiments using the DKET dataset from the literature and create a dataset for language to logic translation based on the Atomic knowledge bank.