 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Emotional Impact of Game Duration: A Framework for Understanding Player Emotions in Extended Gameplay Sessions
Mar 31, 2024
Video games have played a crucial role in entertainment since their development in the 1970s, becoming even more prominent during the lockdown period when people were looking for ways to entertain them. However, at that time, players were unaware of the significant impact that playtime could have on their feelings. This has made it challenging for designers and developers to create new games since they have to control the emotional impact that these games will take on players. Thus, the purpose of this study is to look at how a player's emotions are affected by the duration of the game. In order to achieve this goal, a framework for emotion detection is created. According to the experiment's results, the volunteers' general ability to express emotions increased from 20 to 60 minutes. In comparison to shorter gameplay sessions, the experiment found that extended gameplay sessions did significantly affect the player's emotions. According to the results, it was recommended that in order to lessen the potential emotional impact that playing computer and video games may have in the future, game producers should think about creating shorter, entertaining games.
Budget-aware Query Tuning: An AutoML Perspective
Mar 29, 2024Modern database systems rely on cost-based query optimizers to come up with good execution plans for input queries. Such query optimizers rely on cost models to estimate the costs of candidate query execution plans. A cost model represents a function from a set of cost units to query execution cost, where each cost unit specifies the unit cost of executing a certain type of query processing operation (such as table scan or join). These cost units are traditionally viewed as constants, whose values only depend on the platform configuration where the database system runs on top of but are invariant for queries processed by the database system. In this paper, we challenge this classic view by thinking of these cost units as variables instead. We show that, by varying the cost-unit values one can obtain query plans that significantly outperform the default query plans returned by the query optimizer when viewing the cost units as constants. We term this cost-unit tuning process "query tuning" (QT) and show that it is similar to the well-known hyper-parameter optimization (HPO) problem in AutoML. As a result, any state-of-the-art HPO technologies can be applied to QT. We study the QT problem in the context of anytime tuning, which is desirable in practice by constraining the total time spent on QT within a given budget -- we call this problem budget-aware query tuning. We further extend our study from tuning a single query to tuning a workload with multiple queries, and we call this generalized problem budget-aware workload tuning (WT), which aims for minimizing the execution time of the entire workload. WT is more challenging as one needs to further prioritize individual query tuning within the given time budget. We propose solutions to both QT and WT and experimental evaluation using both benchmark and real workloads demonstrates the efficacy of our proposed solutions.
Time Weaver: A Conditional Time Series Generation Model
Mar 05, 2024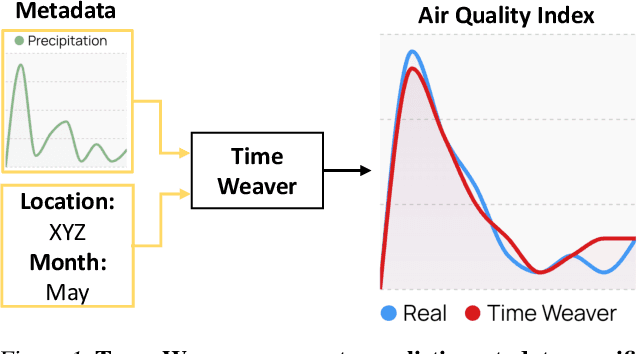
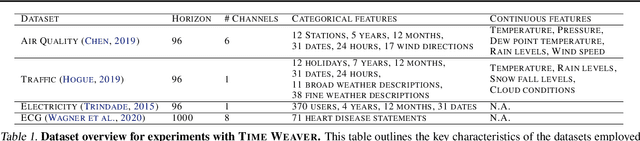
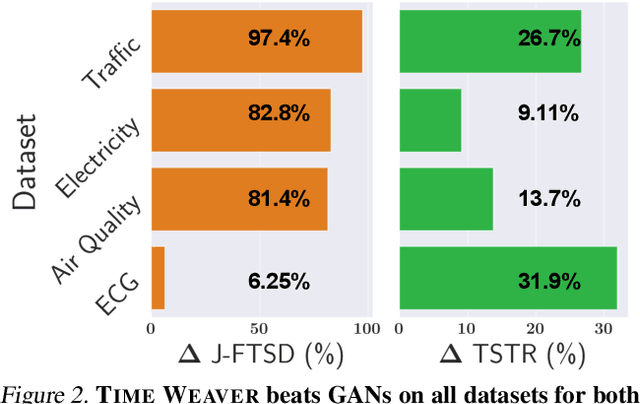
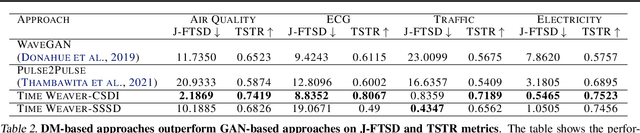
Imagine generating a city's electricity demand pattern based on weather, the presence of an electric vehicle, and location, which could be used for capacity planning during a winter freeze. Such real-world time series are often enriched with paired heterogeneous contextual metadata (weather, location, etc.). Current approaches to time series generation often ignore this paired metadata, and its heterogeneity poses several practical challenges in adapting existing conditional generation approaches from the image, audio, and video domains to the time series domain. To address this gap, we introduce Time Weaver, a novel diffusion-based model that leverages the heterogeneous metadata in the form of categorical, continuous, and even time-variant variables to significantly improve time series generation. Additionally, we show that naive extensions of standard evaluation metrics from the image to the time series domain are insufficient. These metrics do not penalize conditional generation approaches for their poor specificity in reproducing the metadata-specific features in the generated time series. Thus, we innovate a novel evaluation metric that accurately captures the specificity of conditional generation and the realism of the generated time series. We show that Time Weaver outperforms state-of-the-art benchmarks, such as Generative Adversarial Networks (GANs), by up to 27% in downstream classification tasks on real-world energy, medical, air quality, and traffic data sets.
Configurable Safety Tuning of Language Models with Synthetic Preference Data
Mar 30, 2024State-of-the-art language model fine-tuning techniques, such as Direct Preference Optimization (DPO), restrict user control by hard-coding predefined behaviors into the model. To address this, we propose a novel method, Configurable Safety Tuning (CST), that augments DPO using synthetic preference data to facilitate flexible safety configuration of LLMs at inference time. CST overcomes the constraints of vanilla DPO by introducing a system prompt specifying safety configurations, enabling LLM deployers to disable/enable safety preferences based on their need, just changing the system prompt. Our experimental evaluations indicate that CST successfully manages different safety configurations and retains the original functionality of LLMs, showing it is a robust method for configurable deployment. Data and models available at https://github.com/vicgalle/configurable-safety-tuning
FetalDiffusion: Pose-Controllable 3D Fetal MRI Synthesis with Conditional Diffusion Model
Mar 29, 2024The quality of fetal MRI is significantly affected by unpredictable and substantial fetal motion, leading to the introduction of artifacts even when fast acquisition sequences are employed. The development of 3D real-time fetal pose estimation approaches on volumetric EPI fetal MRI opens up a promising avenue for fetal motion monitoring and prediction. Challenges arise in fetal pose estimation due to limited number of real scanned fetal MR training images, hindering model generalization when the acquired fetal MRI lacks adequate pose. In this study, we introduce FetalDiffusion, a novel approach utilizing a conditional diffusion model to generate 3D synthetic fetal MRI with controllable pose. Additionally, an auxiliary pose-level loss is adopted to enhance model performance. Our work demonstrates the success of this proposed model by producing high-quality synthetic fetal MRI images with accurate and recognizable fetal poses, comparing favorably with in-vivo real fetal MRI. Furthermore, we show that the integration of synthetic fetal MR images enhances the fetal pose estimation model's performance, particularly when the number of available real scanned data is limited resulting in 15.4% increase in PCK and 50.2% reduced in mean error. All experiments are done on a single 32GB V100 GPU. Our method holds promise for improving real-time tracking models, thereby addressing fetal motion issues more effectively.
MTMMC: A Large-Scale Real-World Multi-Modal Camera Tracking Benchmark
Mar 29, 2024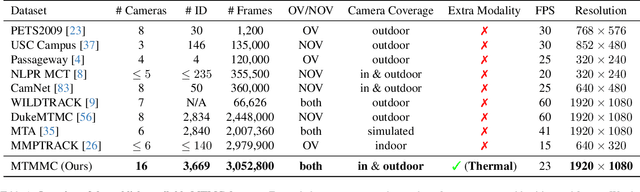
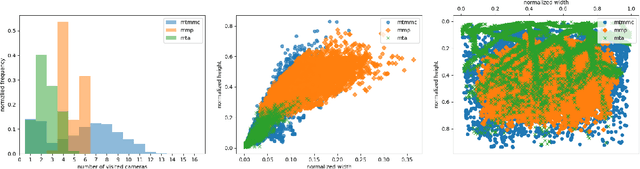

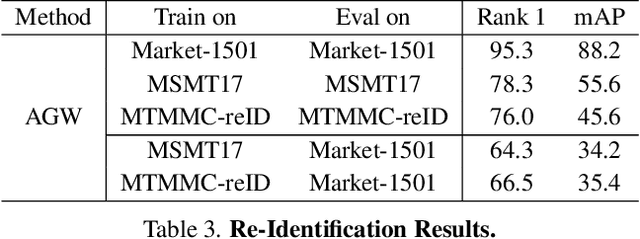
Multi-target multi-camera tracking is a crucial task that involves identifying and tracking individuals over time using video streams from multiple cameras. This task has practical applications in various fields, such as visual surveillance, crowd behavior analysis, and anomaly detection. However, due to the difficulty and cost of collecting and labeling data, existing datasets for this task are either synthetically generated or artificially constructed within a controlled camera network setting, which limits their ability to model real-world dynamics and generalize to diverse camera configurations. To address this issue, we present MTMMC, a real-world, large-scale dataset that includes long video sequences captured by 16 multi-modal cameras in two different environments - campus and factory - across various time, weather, and season conditions. This dataset provides a challenging test-bed for studying multi-camera tracking under diverse real-world complexities and includes an additional input modality of spatially aligned and temporally synchronized RGB and thermal cameras, which enhances the accuracy of multi-camera tracking. MTMMC is a super-set of existing datasets, benefiting independent fields such as person detection, re-identification, and multiple object tracking. We provide baselines and new learning setups on this dataset and set the reference scores for future studies. The datasets, models, and test server will be made publicly available.
How Much are LLMs Contaminated? A Comprehensive Survey and the LLMSanitize Library
Mar 31, 2024With the rise of Large Language Models (LLMs) in recent years, new opportunities are emerging, but also new challenges, and contamination is quickly becoming critical. Business applications and fundraising in AI have reached a scale at which a few percentage points gained on popular question-answering benchmarks could translate into dozens of millions of dollars, placing high pressure on model integrity. At the same time, it is becoming harder and harder to keep track of the data that LLMs have seen; if not impossible with closed-source models like GPT-4 and Claude-3 not divulging any information on the training set. As a result, contamination becomes a critical issue: LLMs' performance may not be reliable anymore, as the high performance may be at least partly due to their previous exposure to the data. This limitation jeopardizes the entire progress in the field of NLP, yet, there remains a lack of methods on how to efficiently address contamination, or a clear consensus on prevention, mitigation and classification of contamination. In this paper, we survey all recent work on contamination with LLMs, and help the community track contamination levels of LLMs by releasing an open-source Python library named LLMSanitize implementing major contamination detection algorithms, which link is: https://github.com/ntunlp/LLMSanitize.
On the Estimation of Image-matching Uncertainty in Visual Place Recognition
Mar 31, 2024In Visual Place Recognition (VPR) the pose of a query image is estimated by comparing the image to a map of reference images with known reference poses. As is typical for image retrieval problems, a feature extractor maps the query and reference images to a feature space, where a nearest neighbor search is then performed. However, till recently little attention has been given to quantifying the confidence that a retrieved reference image is a correct match. Highly certain but incorrect retrieval can lead to catastrophic failure of VPR-based localization pipelines. This work compares for the first time the main approaches for estimating the image-matching uncertainty, including the traditional retrieval-based uncertainty estimation, more recent data-driven aleatoric uncertainty estimation, and the compute-intensive geometric verification. We further formulate a simple baseline method, ``SUE'', which unlike the other methods considers the freely-available poses of the reference images in the map. Our experiments reveal that a simple L2-distance between the query and reference descriptors is already a better estimate of image-matching uncertainty than current data-driven approaches. SUE outperforms the other efficient uncertainty estimation methods, and its uncertainty estimates complement the computationally expensive geometric verification approach. Future works for uncertainty estimation in VPR should consider the baselines discussed in this work.
Human-Robot Co-Transportation with Human Uncertainty-Aware MPC and Pose Optimization
Mar 31, 2024This paper proposes a new control algorithm for human-robot co-transportation based on a robot manipulator equipped with a mobile base and a robotic arm. The primary focus is to adapt to human uncertainties through the robot's whole-body dynamics and pose optimization. We introduce an augmented Model Predictive Control (MPC) formulation that explicitly models human uncertainties and contains extra variables than regular MPC to optimize the pose of the robotic arm. The core of our methodology involves a two-step iterative design: At each planning horizon, we select the best pose of the robotic arm (joint angle combination) from a candidate set, aiming to achieve the lowest estimated control cost. This selection is based on solving an uncertainty-aware Discrete Algebraic Ricatti Equation (DARE), which also informs the optimal control inputs for both the mobile base and the robotic arm. To validate the effectiveness of the proposed approach, we provide theoretical derivation for the uncertainty-aware DARE and perform simulated and proof-of-concept hardware experiments using a Fetch robot under varying conditions, including different nominal trajectories and noise levels. The results reveal that our proposed approach outperforms baseline algorithms, maintaining similar execution time with that do not consider human uncertainty or do not perform pose optimization.
Spikewhisper: Temporal Spike Backdoor Attacks on Federated Neuromorphic Learning over Low-power Devices
Mar 27, 2024Federated neuromorphic learning (FedNL) leverages event-driven spiking neural networks and federated learning frameworks to effectively execute intelligent analysis tasks over amounts of distributed low-power devices but also perform vulnerability to poisoning attacks. The threat of backdoor attacks on traditional deep neural networks typically comes from time-invariant data. However, in FedNL, unknown threats may be hidden in time-varying spike signals. In this paper, we start to explore a novel vulnerability of FedNL-based systems with the concept of time division multiplexing, termed Spikewhisper, which allows attackers to evade detection as much as possible, as multiple malicious clients can imperceptibly poison with different triggers at different timeslices. In particular, the stealthiness of Spikewhisper is derived from the time-domain divisibility of global triggers, in which each malicious client pastes only one local trigger to a certain timeslice in the neuromorphic sample, and also the polarity and motion of each local trigger can be configured by attackers. Extensive experiments based on two different neuromorphic datasets demonstrate that the attack success rate of Spikewispher is higher than the temporally centralized attacks. Besides, it is validated that the effect of Spikewispher is sensitive to the trigger duration.