 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bayesian Neural Controlled Differential Equations for Treatment Effect Estimation
Oct 26, 2023
Treatment effect estimation in continuous time is crucial for personalized medicine. However, existing methods for this task are limited to point estimates of the potential outcomes, whereas uncertainty estimates have been ignored. Needless to say, uncertainty quantification is crucial for reliable decision-making in medical applications. To fill this gap, we propose a novel Bayesian neural controlled differential equation (BNCDE) for treatment effect estimation in continuous time. In our BNCDE, the time dimension is modeled through a coupled system of neural controlled differential equations and neural stochastic differential equations, where the neural stochastic differential equations allow for tractable variational Bayesian inference. Thereby, for an assigned sequence of treatments, our BNCDE provides meaningful posterior predictive distributions of the potential outcomes. To the best of our knowledge, ours is the first tailored neural method to provide uncertainty estimates of treatment effects in continuous time. As such, our method is of direct practical value for promoting reliable decision-making in medicine.
4D-Editor: Interactive Object-level Editing in Dynamic Neural Radiance Fields via Semantic Distillation
Nov 06, 2023This paper targets interactive object-level editing (e.g., deletion, recoloring, transformation, composition) in dynamic scenes. Recently, some methods aiming for flexible editing static scenes represented by neural radiance field (NeRF) have shown impressive synthesis quality, while similar capabilities in time-variant dynamic scenes remain limited. To solve this problem, we propose 4D-Editor, an interactive semantic-driven editing framework, allowing editing multiple objects in a dynamic NeRF with user strokes on a single frame. We propose an extension to the original dynamic NeRF by incorporating a hybrid semantic feature distillation to maintain spatial-temporal consistency after editing. In addition, we design Recursive Selection Refinement that significantly boosts object segmentation accuracy within a dynamic NeRF to aid the editing process. Moreover, we develop Multi-view Reprojection Inpainting to fill holes caused by incomplete scene capture after editing. Extensive experiments and editing examples on real-world demonstrate that 4D-Editor achieves photo-realistic editing on dynamic NeRFs. Project page: https://patrickddj.github.io/4D-Editor
HRTF Estimation in the Wild
Nov 06, 2023Head Related Transfer Functions (HRTFs) play a crucial role in creating immersive spatial audio experiences. However, HRTFs differ significantly from person to person, and traditional methods for estimating personalized HRTFs are expensive, time-consuming, and require specialized equipment. We imagine a world where your personalized HRTF can be determined by capturing data through earbuds in everyday environments. In this paper, we propose a novel approach for deriving personalized HRTFs that only relies on in-the-wild binaural recordings and head tracking data. By analyzing how sounds change as the user rotates their head through different environments with different noise sources, we can accurately estimate their personalized HRTF. Our results show that our predicted HRTFs closely match ground-truth HRTFs measured in an anechoic chamber. Furthermore, listening studies demonstrate that our personalized HRTFs significantly improve sound localization and reduce front-back confusion in virtual environments. Our approach offers an efficient and accessible method for deriving personalized HRTFs and has the potential to greatly improve spatial audio experiences.
InterVLS: Interactive Model Understanding and Improvement with Vision-Language Surrogates
Nov 06, 2023Deep learning models are widely used in critical applications, highlighting the need for pre-deployment model understanding and improvement. Visual concept-based methods, while increasingly used for this purpose, face challenges: (1) most concepts lack interpretability, (2) existing methods require model knowledge, often unavailable at run time. Additionally, (3) there lacks a no-code method for post-understanding model improvement. Addressing these, we present InterVLS. The system facilitates model understanding by discovering text-aligned concepts, measuring their influence with model-agnostic linear surrogates. Employing visual analytics, InterVLS offers concept-based explanations and performance insights. It enables users to adjust concept influences to update a model, facilitating no-code model improvement. We evaluate InterVLS in a user study, illustrating its functionality with two scenarios. Results indicates that InterVLS is effective to help users identify influential concepts to a model, gain insights and adjust concept influence to improve the model. We conclude with a discussion based on our study results.
Context Unlocks Emotions: Text-based Emotion Classification Dataset Auditing with Large Language Models
Nov 06, 2023The lack of contextual information in text data can make the annotation process of text-based emotion classification datasets challenging. As a result, such datasets often contain labels that fail to consider all the relevant emotions in the vocabulary. This misalignment between text inputs and labels can degrade the performance of machine learning models trained on top of them. As re-annotating entire datasets is a costly and time-consuming task that cannot be done at scale, we propose to use the expressive capabilities of large language models to synthesize additional context for input text to increase its alignment with the annotated emotional labels. In this work, we propose a formal definition of textual context to motivate a prompting strategy to enhance such contextual information. We provide both human and empirical evaluation to demonstrate the efficacy of the enhanced context. Our method improves alignment between inputs and their human-annotated labels from both an empirical and human-evaluated standpoint.
GQKVA: Efficient Pre-training of Transformers by Grouping Queries, Keys, and Values
Nov 06, 2023Massive transformer-based models face several challenges, including slow and computationally intensive pre-training and over-parametrization. This paper addresses these challenges by proposing a versatile method called GQKVA, which generalizes query, key, and value grouping techniques. GQKVA is designed to speed up transformer pre-training while reducing the model size. Our experiments with various GQKVA variants highlight a clear trade-off between performance and model size, allowing for customized choices based on resource and time limitations. Our findings also indicate that the conventional multi-head attention approach is not always the best choice, as there are lighter and faster alternatives available. We tested our method on ViT, which achieved an approximate 0.3% increase in accuracy while reducing the model size by about 4% in the task of image classification. Additionally, our most aggressive model reduction experiment resulted in a reduction of approximately 15% in model size, with only around a 1% drop in accuracy.
A Robust Bi-Directional Algorithm For People Count In Crowded Areas
Nov 06, 2023People counting system in crowded places has become a very useful practical application that can be accomplished in various ways which include many traditional methods using sensors. Examining the case of real time scenarios, the algorithm espoused should be steadfast and accurate. People counting algorithm presented in this paper, is centered on blob assessment, devoted to yield the count of the people through a path along with the direction of traversal. The system depicted is often ensconced at the entrance of a building so that the unmitigated frequency of visitors can be recorded. The core premise of this work is to extricate count of people inflow and outflow pertaining to a particular area. The tot-up achieved can be exploited for purpose of statistics in the circumstances of any calamity occurrence in that zone. Relying upon the count totaled, the population in that vicinity can be assimilated in order to take on relevant measures to rescue the people.
A Low-cost Strategic Monitoring Approach for Scalable and Interpretable Error Detection in Deep Neural Networks
Oct 31, 2023We present a highly compact run-time monitoring approach for deep computer vision networks that extracts selected knowledge from only a few (down to merely two) hidden layers, yet can efficiently detect silent data corruption originating from both hardware memory and input faults. Building on the insight that critical faults typically manifest as peak or bulk shifts in the activation distribution of the affected network layers, we use strategically placed quantile markers to make accurate estimates about the anomaly of the current inference as a whole. Importantly, the detector component itself is kept algorithmically transparent to render the categorization of regular and abnormal behavior interpretable to a human. Our technique achieves up to ~96% precision and ~98% recall of detection. Compared to state-of-the-art anomaly detection techniques, this approach requires minimal compute overhead (as little as 0.3% with respect to non-supervised inference time) and contributes to the explainability of the model.
Traj-LO: In Defense of LiDAR-Only Odometry Using an Effective Continuous-Time Trajectory
Sep 25, 2023LiDAR Odometry is an essential component in many robotic applications. Unlike the mainstreamed approaches that focus on improving the accuracy by the additional inertial sensors, this letter explores the capability of LiDAR-only odometry through a continuous-time perspective. Firstly, the measurements of LiDAR are regarded as streaming points continuously captured at high frequency. Secondly, the LiDAR movement is parameterized by a simple yet effective continuous-time trajectory. Therefore, our proposed Traj-LO approach tries to recover the spatial-temporal consistent movement of LiDAR by tightly coupling the geometric information from LiDAR points and kinematic constraints from trajectory smoothness. This framework is generalized for different kinds of LiDAR as well as multi-LiDAR systems. Extensive experiments on the public datasets demonstrate the robustness and effectiveness of our proposed LiDAR-only approach, even in scenarios where the kinematic state exceeds the IMU's measuring range. Our implementation is open-sourced on GitHub.
Generating Hierarchical Structures for Improved Time Series Classification Using Stochastic Splitting Functions
Sep 21, 2023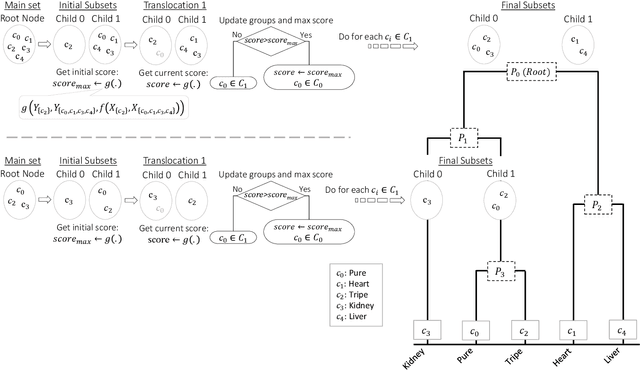

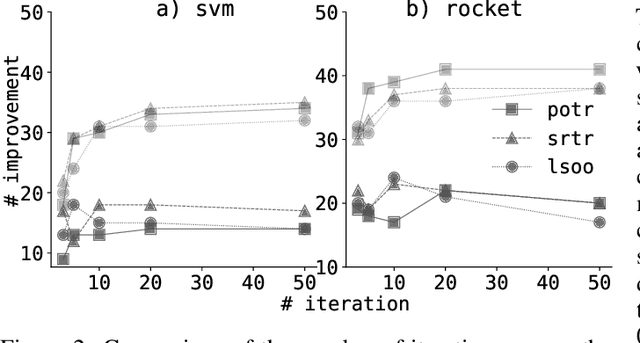
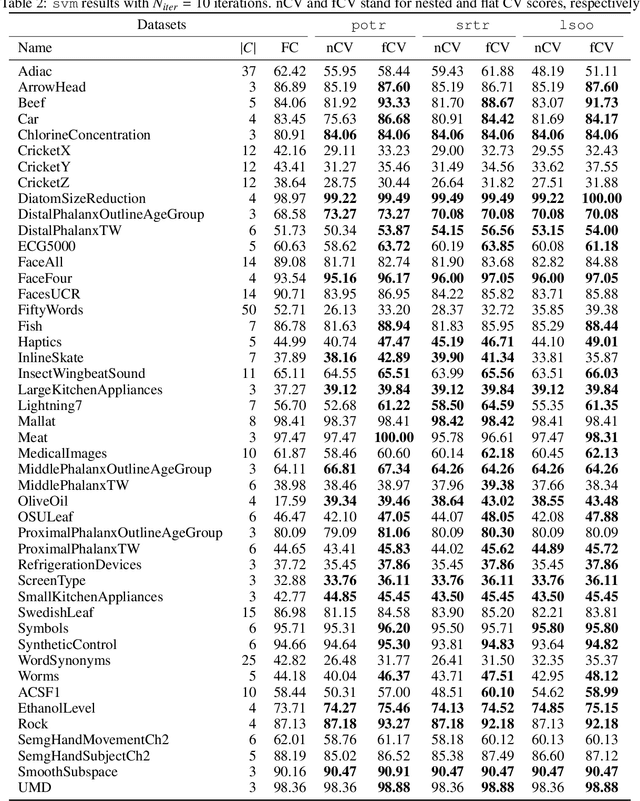
This study introduces a novel hierarchical divisive clustering approach with stochastic splitting functions (SSFs) to enhance classification performance in multi-class datasets through hierarchical classification (HC). The method has the unique capability of generating hierarchy without requiring explicit information, making it suitable for datasets lacking prior knowledge of hierarchy. By systematically dividing classes into two subsets based on their discriminability according to the classifier, the proposed approach constructs a binary tree representation of hierarchical classes. The approach is evaluated on 46 multi-class time series datasets using popular classifiers (svm and rocket) and SSFs (potr, srtr, and lsoo). The results reveal that the approach significantly improves classification performance in approximately half and a third of the datasets when using rocket and svm as the classifier, respectively. The study also explores the relationship between dataset features and HC performance. While the number of classes and flat classification (FC) score show consistent significance, variations are observed with different splitting functions. Overall, the proposed approach presents a promising strategy for enhancing classification by generating hierarchical structure in multi-class time series datasets. Future research directions involve exploring different splitting functions, classifiers, and hierarchy structures, as well as applying the approach to diverse domains beyond time series data. The source code is made openly available to facilitate reproducibility and further exploration of the method.