 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Opportunities of Green Computing: A Survey
Nov 09, 2023
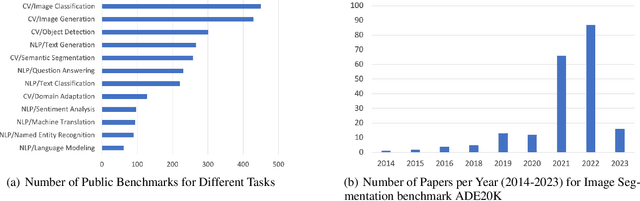
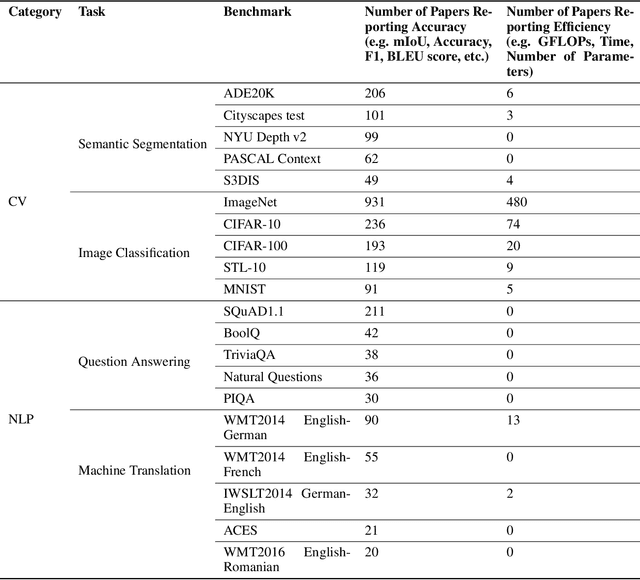
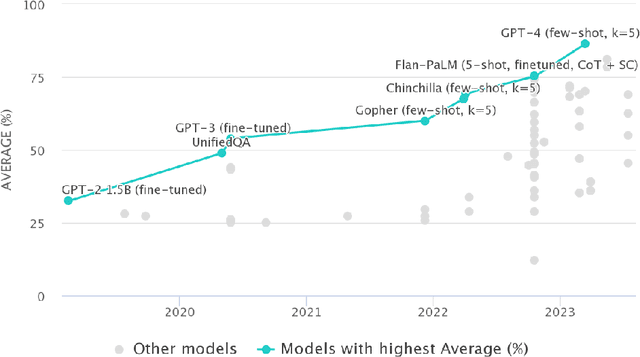
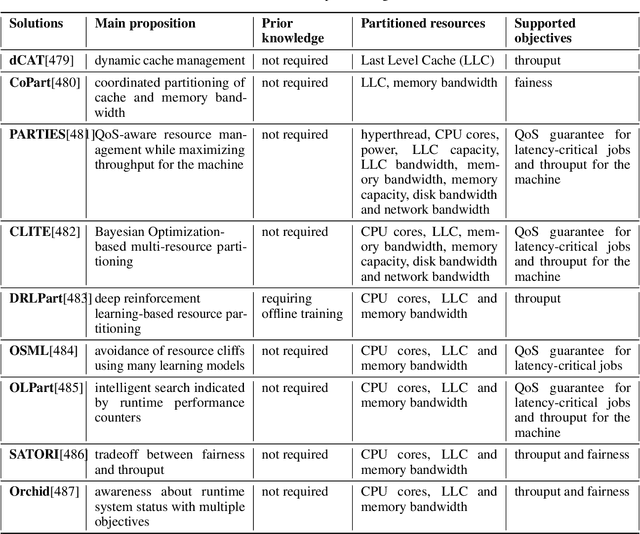
Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
Test-Time Compensated Representation Learning for Extreme Traffic Forecasting
Sep 16, 2023Traffic forecasting is a challenging task due to the complex spatio-temporal correlations among traffic series. In this paper, we identify an underexplored problem in multivariate traffic series prediction: extreme events. Road congestion and rush hours can result in low correlation in vehicle speeds at various intersections during adjacent time periods. Existing methods generally predict future series based on recent observations and entirely discard training data during the testing phase, rendering them unreliable for forecasting highly nonlinear multivariate time series. To tackle this issue, we propose a test-time compensated representation learning framework comprising a spatio-temporal decomposed data bank and a multi-head spatial transformer model (CompFormer). The former component explicitly separates all training data along the temporal dimension according to periodicity characteristics, while the latter component establishes a connection between recent observations and historical series in the data bank through a spatial attention matrix. This enables the CompFormer to transfer robust features to overcome anomalous events while using fewer computational resources. Our modules can be flexibly integrated with existing forecasting methods through end-to-end training, and we demonstrate their effectiveness on the METR-LA and PEMS-BAY benchmarks. Extensive experimental results show that our method is particularly important in extreme events, and can achieve significant improvements over six strong baselines, with an overall improvement of up to 28.2%.
Evaluating Explanation Methods for Multivariate Time Series Classification
Sep 07, 2023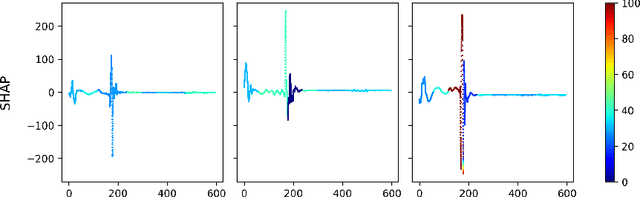

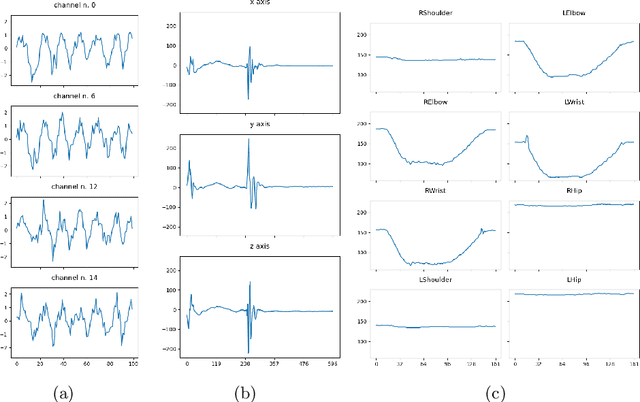
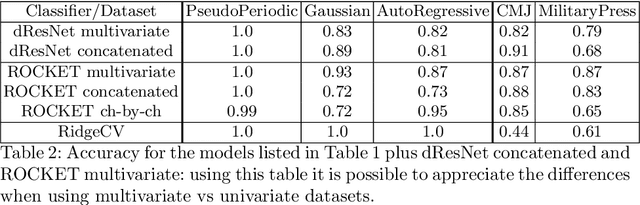
Multivariate time series classification is an important computational task arising in applications where data is recorded over time and over multiple channels. For example, a smartwatch can record the acceleration and orientation of a person's motion, and these signals are recorded as multivariate time series. We can classify this data to understand and predict human movement and various properties such as fitness levels. In many applications classification alone is not enough, we often need to classify but also understand what the model learns (e.g., why was a prediction given, based on what information in the data). The main focus of this paper is on analysing and evaluating explanation methods tailored to Multivariate Time Series Classification (MTSC). We focus on saliency-based explanation methods that can point out the most relevant channels and time series points for the classification decision. We analyse two popular and accurate multivariate time series classifiers, ROCKET and dResNet, as well as two popular explanation methods, SHAP and dCAM. We study these methods on 3 synthetic datasets and 2 real-world datasets and provide a quantitative and qualitative analysis of the explanations provided. We find that flattening the multivariate datasets by concatenating the channels works as well as using multivariate classifiers directly and adaptations of SHAP for MTSC work quite well. Additionally, we also find that the popular synthetic datasets we used are not suitable for time series analysis.
Likelihood Ratio Confidence Sets for Sequential Decision Making
Nov 08, 2023Certifiable, adaptive uncertainty estimates for unknown quantities are an essential ingredient of sequential decision-making algorithms. Standard approaches rely on problem-dependent concentration results and are limited to a specific combination of parameterization, noise family, and estimator. In this paper, we revisit the likelihood-based inference principle and propose to use likelihood ratios to construct any-time valid confidence sequences without requiring specialized treatment in each application scenario. Our method is especially suitable for problems with well-specified likelihoods, and the resulting sets always maintain the prescribed coverage in a model-agnostic manner. The size of the sets depends on a choice of estimator sequence in the likelihood ratio. We discuss how to provably choose the best sequence of estimators and shed light on connections to online convex optimization with algorithms such as Follow-the-Regularized-Leader. To counteract the initially large bias of the estimators, we propose a reweighting scheme that also opens up deployment in non-parametric settings such as RKHS function classes. We provide a non-asymptotic analysis of the likelihood ratio confidence sets size for generalized linear models, using insights from convex duality and online learning. We showcase the practical strength of our method on generalized linear bandit problems, survival analysis, and bandits with various additive noise distributions.
CAIS-DMA: A Decision-Making Assistant for Collaborative AI Systems
Nov 08, 2023A Collaborative Artificial Intelligence System (CAIS) is a cyber-physical system that learns actions in collaboration with humans in a shared environment to achieve a common goal. In particular, a CAIS is equipped with an AI model to support the decision-making process of this collaboration. When an event degrades the performance of CAIS (i.e., a disruptive event), this decision-making process may be hampered or even stopped. Thus, it is of paramount importance to monitor the learning of the AI model, and eventually support its decision-making process in such circumstances. This paper introduces a new methodology to automatically support the decision-making process in CAIS when the system experiences performance degradation after a disruptive event. To this aim, we develop a framework that consists of three components: one manages or simulates CAIS's environment and disruptive events, the second automates the decision-making process, and the third provides a visual analysis of CAIS behavior. Overall, our framework automatically monitors the decision-making process, intervenes whenever a performance degradation occurs, and recommends the next action. We demonstrate our framework by implementing an example with a real-world collaborative robot, where the framework recommends the next action that balances between minimizing the recovery time (i.e., resilience), and minimizing the energy adverse effects (i.e., greenness).
Video Instance Matting
Nov 08, 2023Conventional video matting outputs one alpha matte for all instances appearing in a video frame so that individual instances are not distinguished. While video instance segmentation provides time-consistent instance masks, results are unsatisfactory for matting applications, especially due to applied binarization. To remedy this deficiency, we propose Video Instance Matting~(VIM), that is, estimating alpha mattes of each instance at each frame of a video sequence. To tackle this challenging problem, we present MSG-VIM, a Mask Sequence Guided Video Instance Matting neural network, as a novel baseline model for VIM. MSG-VIM leverages a mixture of mask augmentations to make predictions robust to inaccurate and inconsistent mask guidance. It incorporates temporal mask and temporal feature guidance to improve the temporal consistency of alpha matte predictions. Furthermore, we build a new benchmark for VIM, called VIM50, which comprises 50 video clips with multiple human instances as foreground objects. To evaluate performances on the VIM task, we introduce a suitable metric called Video Instance-aware Matting Quality~(VIMQ). Our proposed model MSG-VIM sets a strong baseline on the VIM50 benchmark and outperforms existing methods by a large margin. The project is open-sourced at https://github.com/SHI-Labs/VIM.
Cross-Domain Waveform Design for 6G Integrated Sensing and Communication
Nov 08, 2023Orthogonal frequency division multiplexing (OFDM) is one of the representative integrated sensing and communication (ISAC) waveforms, where sensing and communications tend to be assigned with different resource elements (REs) due to their diverse design requirements. This motivates optimization of resource allocation/waveform design across time, frequency, power and delay-Doppler domains. Therefore, this article proposes two cross-domain waveform optimization strategies for OFDM-based ISAC systems, following communication-centric and sensing-centric criteria, respectively. For the communication-centric design, to maximize the achievable data rate, a fraction of REs are optimally allocated for communications according to prior knowledge of the communication channel. The remaining REs are then employed for sensing, where the sidelobe level and peak to average power ratio are suppressed by optimizing its power-frequency and phase-frequency characteristics. For the sensing-centric design, a `locally' perfect auto-correlation property is ensured by adjusting the unit cells of the ambiguity function within its region of interest (RoI). Afterwards, the irrelevant cells beyond RoI, which can readily determine the sensing power allocation, are optimized with the communication power allocation to enhance the achievable data rate. Numerical results demonstrate the superiority of the proposed communication-centric and sensing-centric waveform designs for ISAC applications.
Massive Editing for Large Language Models via Meta Learning
Nov 08, 2023While large language models (LLMs) have enabled learning knowledge from the pre-training corpora, the acquired knowledge may be fundamentally incorrect or outdated over time, which necessitates rectifying the knowledge of the language model (LM) after the training. A promising approach involves employing a hyper-network to generate parameter shift, whereas existing hyper-networks suffer from inferior scalability in synchronous editing operation amount. To mitigate the problem, we propose the MAssive Language Model Editing Network (MALMEN), which formulates the parameter shift aggregation as the least square problem, subsequently updating the LM parameters using the normal equation. To accommodate editing multiple facts simultaneously with limited memory budgets, we separate the computation on the hyper-network and LM, enabling arbitrary batch size on both neural networks. Our method is evaluated by editing up to thousands of facts on LMs with different architectures, i.e., BERT-base, GPT-2, T5-XL (2.8B), and GPT-J (6B), across various knowledge-intensive NLP tasks, i.e., closed book fact-checking and question answering. Remarkably, MALMEN is capable of editing hundreds of times more facts than strong baselines with the identical hyper-network architecture and outperforms editor specifically designed for GPT. Our code is available at https://github.com/ChenmienTan/malmen.
Deep learning as a tool for quantum error reduction in quantum image processing
Nov 08, 2023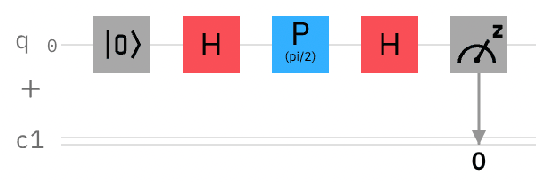
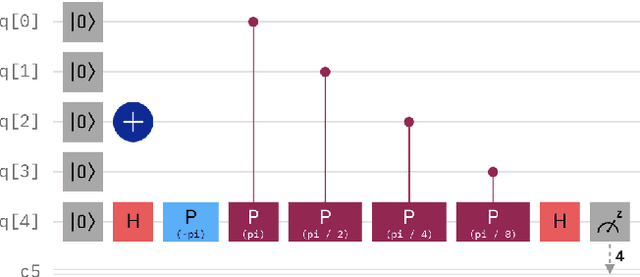

Despite the limited availability and quantum volume of quantum computers, quantum image representation is a widely researched area. Currently developed methods use quantum entanglement to encode information about pixel positions. These methods range from using the angle parameter of the rotation gate (e.g., the Flexible Representation of Quantum Images, FRQI), sequences of qubits (e.g., Novel Enhanced Quantum Representation, NEQR), or the angle parameter of the phase shift gates (e.g., Local Phase Image Quantum Encoding, LPIQE) for storing color information. All these methods are significantly affected by decoherence and other forms of quantum noise, which is an inseparable part of quantum computing in the noisy intermediate-scale quantum era. These phenomena can highly influence the measurements and result in extracted images that are visually dissimilar to the originals. Because this process is at its foundation quantum, the computational reversal of this process is possible. There are many methods for error correction, mitigation, and reduction, but all of them use quantum computer time or additional qubits to achieve the desired result. We report the successful use of a generative adversarial network trained for image-to-image translation, in conjunction with Phase Distortion Unraveling error reduction method, for reducing overall error in images encoded using LPIQE.
TACNET: Temporal Audio Source Counting Network
Nov 04, 2023In this paper, we introduce the Temporal Audio Source Counting Network (TaCNet), an innovative architecture that addresses limitations in audio source counting tasks. TaCNet operates directly on raw audio inputs, eliminating complex preprocessing steps and simplifying the workflow. Notably, it excels in real-time speaker counting, even with truncated input windows. Our extensive evaluation, conducted using the LibriCount dataset, underscores TaCNet's exceptional performance, positioning it as a state-of-the-art solution for audio source counting tasks. With an average accuracy of 74.18 percentage over 11 classes, TaCNet demonstrates its effectiveness across diverse scenarios, including applications involving Chinese and Persian languages. This cross-lingual adaptability highlights its versatility and potential impact.