 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A time-causal and time-recursive analogue of the Gabor transform
Aug 28, 2023
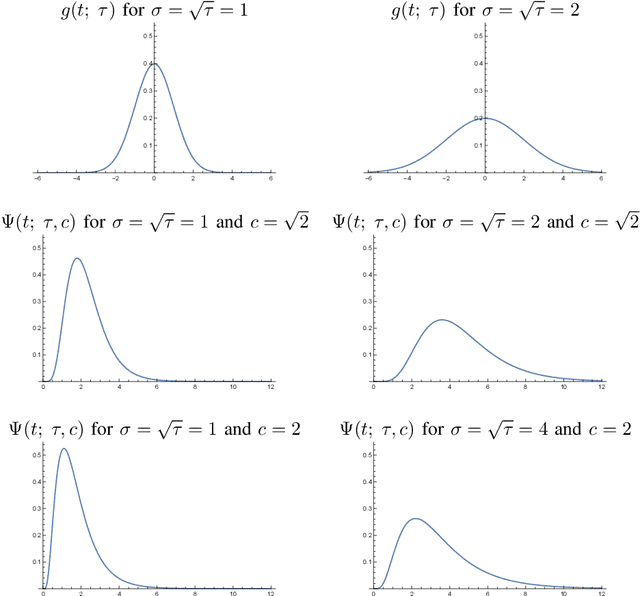
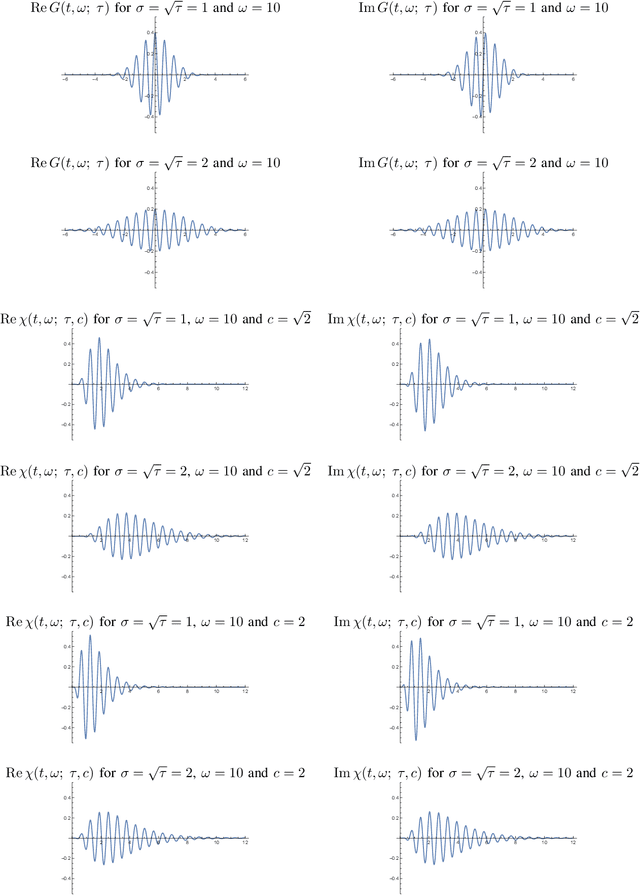
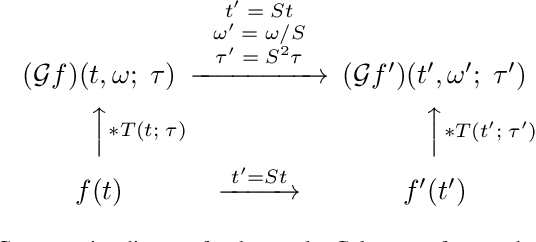
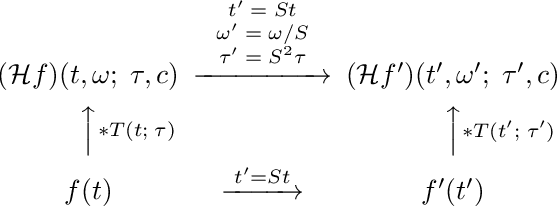
This paper presents a time-causal analogue of the Gabor filter, as well as a both time-causal and time-recursive analogue of the Gabor transform, where the proposed time-causal representations obey both temporal scale covariance and a cascade property with a simplifying kernel over temporal scales. The motivation behind these constructions is to enable theoretically well-founded time-frequency analysis over multiple temporal scales for real-time situations, or for physical or biological modelling situations, when the future cannot be accessed, and the non-causal access to future in Gabor filtering is therefore not viable for a time-frequency analysis of the system. We develop the theory for these representations, obtained by replacing the Gaussian kernel in Gabor filtering with a time-causal kernel, referred to as the time-causal limit kernel, which guarantees simplification properties from finer to coarser levels of scales in a time-causal situation, similar as the Gaussian kernel can be shown to guarantee over a non-causal temporal domain. In these ways, the proposed time-frequency representations guarantee well-founded treatment over multiple scales, in situations when the characteristic scales in the signals, or physical or biological phenomena, to be analyzed may vary substantially, and additionally all steps in the time-frequency analysis have to be fully time-causal.
A Computationally Efficient Sparsified Online Newton Method
Nov 16, 2023Second-order methods hold significant promise for enhancing the convergence of deep neural network training; however, their large memory and computational demands have limited their practicality. Thus there is a need for scalable second-order methods that can efficiently train large models. In this paper, we introduce the Sparsified Online Newton (SONew) method, a memory-efficient second-order algorithm that yields a sparsified yet effective preconditioner. The algorithm emerges from a novel use of the LogDet matrix divergence measure; we combine it with sparsity constraints to minimize regret in the online convex optimization framework. Empirically, we test our method on large scale benchmarks of up to 1B parameters. We achieve up to 30% faster convergence, 3.4% relative improvement in validation performance, and 80% relative improvement in training loss, in comparison to memory efficient optimizers including first order methods. Powering the method is a surprising fact -- imposing structured sparsity patterns, like tridiagonal and banded structure, requires little to no overhead, making it as efficient and parallelizable as first-order methods. In wall-clock time, tridiagonal SONew is only about 3% slower per step than first-order methods but gives overall gains due to much faster convergence. In contrast, one of the state-of-the-art (SOTA) memory-intensive second-order methods, Shampoo, is unable to scale to large benchmarks. Additionally, while Shampoo necessitates significant engineering efforts to scale to large benchmarks, SONew offers a more straightforward implementation, increasing its practical appeal. SONew code is available at: https://github.com/devvrit/SONew
Adaptive Shells for Efficient Neural Radiance Field Rendering
Nov 16, 2023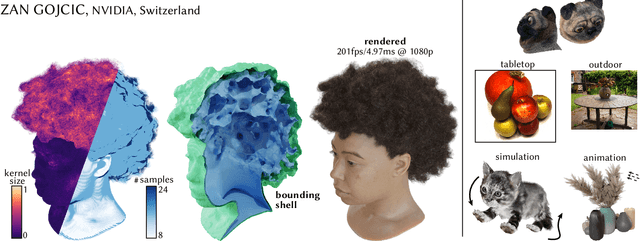
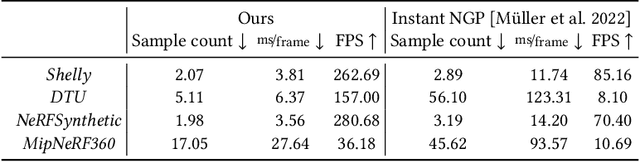

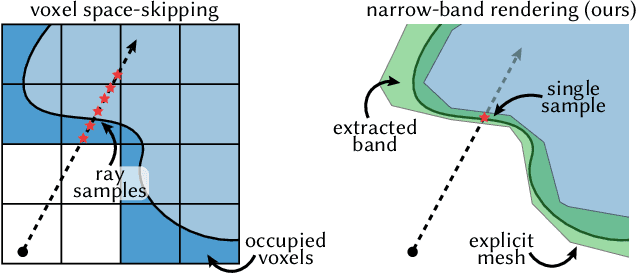
Neural radiance fields achieve unprecedented quality for novel view synthesis, but their volumetric formulation remains expensive, requiring a huge number of samples to render high-resolution images. Volumetric encodings are essential to represent fuzzy geometry such as foliage and hair, and they are well-suited for stochastic optimization. Yet, many scenes ultimately consist largely of solid surfaces which can be accurately rendered by a single sample per pixel. Based on this insight, we propose a neural radiance formulation that smoothly transitions between volumetric- and surface-based rendering, greatly accelerating rendering speed and even improving visual fidelity. Our method constructs an explicit mesh envelope which spatially bounds a neural volumetric representation. In solid regions, the envelope nearly converges to a surface and can often be rendered with a single sample. To this end, we generalize the NeuS formulation with a learned spatially-varying kernel size which encodes the spread of the density, fitting a wide kernel to volume-like regions and a tight kernel to surface-like regions. We then extract an explicit mesh of a narrow band around the surface, with width determined by the kernel size, and fine-tune the radiance field within this band. At inference time, we cast rays against the mesh and evaluate the radiance field only within the enclosed region, greatly reducing the number of samples required. Experiments show that our approach enables efficient rendering at very high fidelity. We also demonstrate that the extracted envelope enables downstream applications such as animation and simulation.
MetaDreamer: Efficient Text-to-3D Creation With Disentangling Geometry and Texture
Nov 16, 2023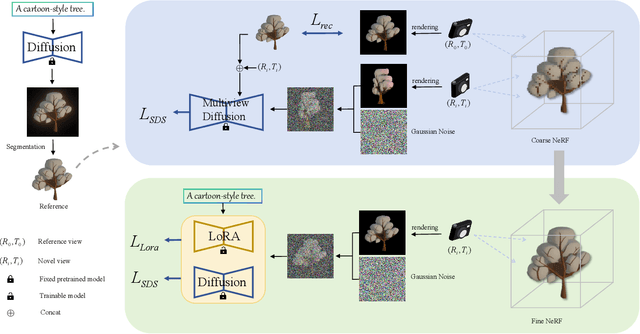
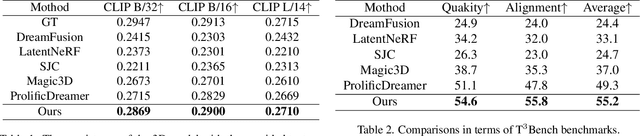


Generative models for 3D object synthesis have seen significant advancements with the incorporation of prior knowledge distilled from 2D diffusion models. Nevertheless, challenges persist in the form of multi-view geometric inconsistencies and slow generation speeds within the existing 3D synthesis frameworks. This can be attributed to two factors: firstly, the deficiency of abundant geometric a priori knowledge in optimization, and secondly, the entanglement issue between geometry and texture in conventional 3D generation methods.In response, we introduce MetaDreammer, a two-stage optimization approach that leverages rich 2D and 3D prior knowledge. In the first stage, our emphasis is on optimizing the geometric representation to ensure multi-view consistency and accuracy of 3D objects. In the second stage, we concentrate on fine-tuning the geometry and optimizing the texture, thereby achieving a more refined 3D object. Through leveraging 2D and 3D prior knowledge in two stages, respectively, we effectively mitigate the interdependence between geometry and texture. MetaDreamer establishes clear optimization objectives for each stage, resulting in significant time savings in the 3D generation process. Ultimately, MetaDreamer can generate high-quality 3D objects based on textual prompts within 20 minutes, and to the best of our knowledge, it is the most efficient text-to-3D generation method. Furthermore, we introduce image control into the process, enhancing the controllability of 3D generation. Extensive empirical evidence confirms that our method is not only highly efficient but also achieves a quality level that is at the forefront of current state-of-the-art 3D generation techniques.
Slide-SAM: Medical SAM Meets Sliding Window
Nov 16, 2023Segment Anything Model (SAM) achieves remarkable results in 2D image segmentation of natural images. However, the huge gap between medical images and natural images prevents it directly applied to medical image segmentation tasks. Especially in 3D medical image, SAM cannot learn the contextual relationship between slices, which limites application in real scenarios. In addition, recent research shows that applying 2D SAM to 3D images requires prompting the entire volume, which is time and label comsuming. In order to solve the above problems, we introduced Slide-SAM which extended SAM to 3D medical images. Specifically, you only need to use a single slice prompt to segement the entire volume, which greatly reduces the prompt workload for professionals. Secondly, unlike traditional 3D medical image segmentation, we are free from the influence of computing resources and can still use high resolution (H$ \times $W = 1024$ \times $1024) for training in 3D images to achieve optimal learning for small targets. This is to combine the entire 3D volume is beyond the reach of training. Finally, we collected a large number of 3D images from large-scale 3D public and private datasets, and extended SAM to 3D medical image segmentation involving bounding box and point prompts. Finally, we perform a comprehensive evaluation and analysis investigating the performance of Slide-SAM in medical image segmentation of different modalities, anatomy, and organs. We have verified Slide-SAM's segmentation capabilities on multiple datasets, achieving the most advanced 3D segmentation performance while maintaining the minimum prompt. Code will be open source soon.
FedFusion: Manifold Driven Federated Learning for Multi-satellite and Multi-modality Fusion
Nov 16, 2023Multi-satellite, multi-modality in-orbit fusion is a challenging task as it explores the fusion representation of complex high-dimensional data under limited computational resources. Deep neural networks can reveal the underlying distribution of multi-modal remote sensing data, but the in-orbit fusion of multimodal data is more difficult because of the limitations of different sensor imaging characteristics, especially when the multimodal data follows non-independent identically distribution (Non-IID) distributions. To address this problem while maintaining classification performance, this paper proposes a manifold-driven multi-modality fusion framework, FedFusion, which randomly samples local data on each client to jointly estimate the prominent manifold structure of shallow features of each client and explicitly compresses the feature matrices into a low-rank subspace through cascading and additive approaches, which is used as the feature input of the subsequent classifier. Considering the physical space limitations of the satellite constellation, we developed a multimodal federated learning module designed specifically for manifold data in a deep latent space. This module achieves iterative updating of the sub-network parameters of each client through global weighted averaging, constructing a framework that can represent compact representations of each client. The proposed framework surpasses existing methods in terms of performance on three multimodal datasets, achieving a classification average accuracy of 94.35$\%$ while compressing communication costs by a factor of 4. Furthermore, extensive numerical evaluations of real-world satellite images were conducted on the orbiting edge computing architecture based on Jetson TX2 industrial modules, which demonstrated that FedFusion significantly reduced training time by 48.4 minutes (15.18%) while optimizing accuracy.}
2D-RC: Two-Dimensional Neural Network Approach for OTFS Symbol Detection
Nov 14, 2023Orthogonal time frequency space (OTFS) is a promising modulation scheme for wireless communication in high-mobility scenarios. Recently, a reservoir computing (RC) based approach has been introduced for online subframe-based symbol detection in the OTFS system, where only a limited number of over-the-air (OTA) pilot symbols are utilized for training. However, this approach does not leverage the domain knowledge specific to the OTFS system. This paper introduces a novel two-dimensional RC (2D-RC) method that incorporates the structural knowledge of the OTFS system into the design for online symbol detection on a subframe basis. Specifically, as the channel response acts as a two-dimensional (2D) operation over the transmitted information symbols in the delay-Doppler (DD) domain, the 2D-RC is designed to have a 2D structure to equalize the channel. With the introduced architecture, the 2D-RC can benefit from the predictable channel representation in the DD domain. Moreover, unlike the previous work that requires multiple RCs to learn the channel feature, the 2D-RC only requires a single neural network for detection. Experimental results demonstrate the effectiveness of the 2D-RC approach across different OTFS system variants and modulation orders.
Calibration of an Elastic Humanoid Upper Body and Efficient Compensation for Motion Planning
Nov 14, 2023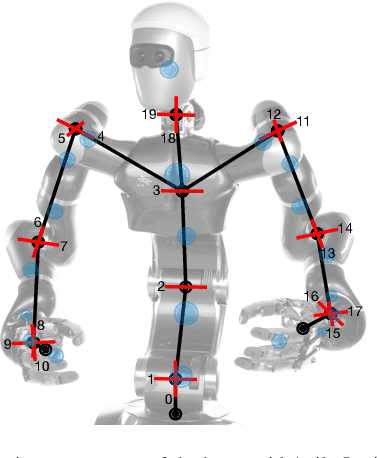
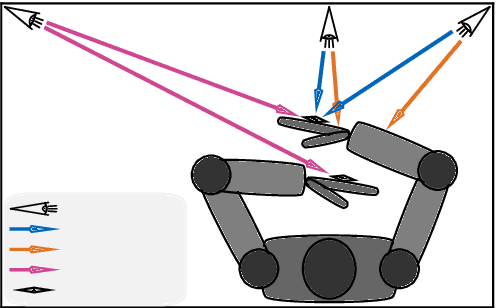
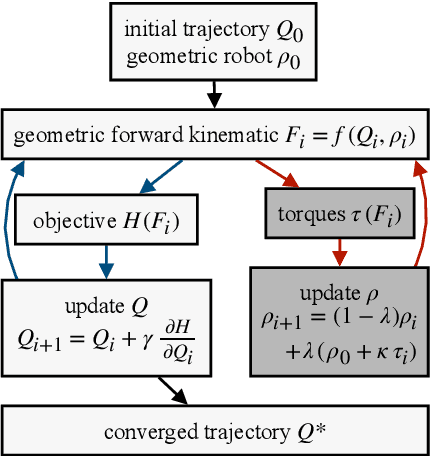
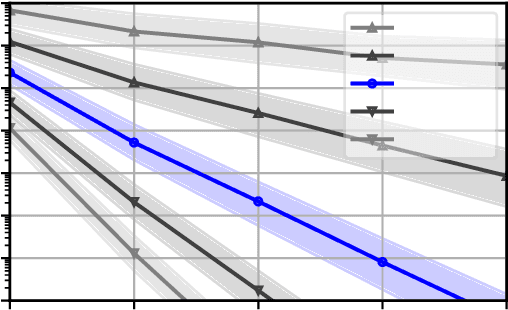
High absolute accuracy is an essential prerequisite for a humanoid robot to autonomously and robustly perform manipulation tasks while avoiding obstacles. We present for the first time a kinematic model for a humanoid upper body incorporating joint and transversal elasticities. These elasticities lead to significant deformations due to the robot's own weight, and the resulting model is implicitly defined via a torque equilibrium. We successfully calibrate this model for DLR's humanoid Agile Justin, including all Denavit-Hartenberg parameters and elasticities. The calibration is formulated as a combined least-squares problem with priors and based on measurements of the end effector positions of both arms via an external tracking system. The absolute position error is massively reduced from 21mm to 3.1mm on average in the whole workspace. Using this complex and implicit kinematic model in motion planning is challenging. We show that for optimization-based path planning, integrating the iterative solution of the implicit model into the optimization loop leads to an elegant and highly efficient solution. For mildly elastic robots like Agile Justin, there is no performance impact, and even for a simulated highly flexible robot with 20 times higher elasticities, the runtime increases by only 30%.
A Wolf in Sheep's Clothing: Generalized Nested Jailbreak Prompts can Fool Large Language Models Easily
Nov 14, 2023Large Language Models (LLMs), such as ChatGPT and GPT-4, are designed to provide useful and safe responses. However, adversarial prompts known as 'jailbreaks' can circumvent safeguards, leading LLMs to generate harmful content. Exploring jailbreak prompts can help to better reveal the weaknesses of LLMs and further steer us to secure them. Unfortunately, existing jailbreak methods either suffer from intricate manual design or require optimization on another white-box model, compromising generalization or jailbreak efficiency. In this paper, we generalize jailbreak prompt attacks into two aspects: (1) Prompt Rewriting and (2) Scenario Nesting. Based on this, we propose ReNeLLM, an automatic framework that leverages LLMs themselves to generate effective jailbreak prompts. Extensive experiments demonstrate that ReNeLLM significantly improves the attack success rate while greatly reducing the time cost compared to existing baselines. Our study also reveals the inadequacy of current defense methods in safeguarding LLMs. Finally, we offer detailed analysis and discussion from the perspective of prompt execution priority on the failure of LLMs' defense. We hope that our research can catalyze both the academic community and LLMs vendors towards the provision of safer and more regulated Large Language Models.
Self-Evolved Diverse Data Sampling for Efficient Instruction Tuning
Nov 14, 2023Enhancing the instruction-following ability of Large Language Models (LLMs) primarily demands substantial instruction-tuning datasets. However, the sheer volume of these imposes a considerable computational burden and annotation cost. To investigate a label-efficient instruction tuning method that allows the model itself to actively sample subsets that are equally or even more effective, we introduce a self-evolving mechanism DiverseEvol. In this process, a model iteratively augments its training subset to refine its own performance, without requiring any intervention from humans or more advanced LLMs. The key to our data sampling technique lies in the enhancement of diversity in the chosen subsets, as the model selects new data points most distinct from any existing ones according to its current embedding space. Extensive experiments across three datasets and benchmarks demonstrate the effectiveness of DiverseEvol. Our models, trained on less than 8% of the original dataset, maintain or improve performance compared with finetuning on full data. We also provide empirical evidence to analyze the importance of diversity in instruction data and the iterative scheme as opposed to one-time sampling. Our code is publicly available at https://github.com/OFA-Sys/DiverseEvol.git.