 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data Augmentations in Deep Weight Spaces
Nov 15, 2023
Learning in weight spaces, where neural networks process the weights of other deep neural networks, has emerged as a promising research direction with applications in various fields, from analyzing and editing neural fields and implicit neural representations, to network pruning and quantization. Recent works designed architectures for effective learning in that space, which takes into account its unique, permutation-equivariant, structure. Unfortunately, so far these architectures suffer from severe overfitting and were shown to benefit from large datasets. This poses a significant challenge because generating data for this learning setup is laborious and time-consuming since each data sample is a full set of network weights that has to be trained. In this paper, we address this difficulty by investigating data augmentations for weight spaces, a set of techniques that enable generating new data examples on the fly without having to train additional input weight space elements. We first review several recently proposed data augmentation schemes %that were proposed recently and divide them into categories. We then introduce a novel augmentation scheme based on the Mixup method. We evaluate the performance of these techniques on existing benchmarks as well as new benchmarks we generate, which can be valuable for future studies.
A* search algorithm for an optimal investment problem in vehicle-sharing systems
Nov 15, 2023We study an optimal investment problem that arises in the context of the vehicle-sharing system. Given a set of locations to build stations, we need to determine i) the sequence of stations to be built and the number of vehicles to acquire in order to obtain the target state where all stations are built, and ii) the number of vehicles to acquire and their allocation in order to maximize the total profit returned by operating the system when some or all stations are open. The profitability associated with operating open stations, measured over a specific time period, is represented as a linear optimization problem applied to a collection of open stations. With operating capital, the owner of the system can open new stations. This property introduces a set-dependent aspect to the duration required for opening a new station, and the optimal investment problem can be viewed as a variant of the Traveling Salesman Problem (TSP) with set-dependent cost. We propose an A* search algorithm to address this particular variant of the TSP. Computational experiments highlight the benefits of the proposed algorithm in comparison to the widely recognized Dijkstra algorithm and propose future research to explore new possibilities and applications for both exact and approximate A* algorithms.
Disentangling the Potential Impacts of Papers into Diffusion, Conformity, and Contribution Values
Nov 15, 2023The potential impact of an academic paper is determined by various factors, including its popularity and contribution. Existing models usually estimate original citation counts based on static graphs and fail to differentiate values from nuanced perspectives. In this study, we propose a novel graph neural network to Disentangle the Potential impacts of Papers into Diffusion, Conformity, and Contribution values (called DPPDCC). Given a target paper, DPPDCC encodes temporal and structural features within the constructed dynamic heterogeneous graph. Particularly, to capture the knowledge flow, we emphasize the importance of comparative and co-cited/citing information between papers and aggregate snapshots evolutionarily. To unravel popularity, we contrast augmented graphs to extract the essence of diffusion and predict the accumulated citation binning to model conformity. We further apply orthogonal constraints to encourage distinct modeling of each perspective and preserve the inherent value of contribution. To evaluate models' generalization for papers published at various times, we reformulate the problem by partitioning data based on specific time points to mirror real-world conditions. Extensive experimental results on three datasets demonstrate that DPPDCC significantly outperforms baselines for previously, freshly, and immediately published papers. Further analyses confirm its robust capabilities. We will make our datasets and codes publicly available.
Pinpoint, Not Criticize: Refining Large Language Models via Fine-Grained Actionable Feedback
Nov 15, 2023Recent improvements in text generation have leveraged human feedback to improve the quality of the generated output. However, human feedback is not always available, especially during inference. In this work, we propose an inference time optimization method FITO to use fine-grained actionable feedback in the form of error type, error location and severity level that are predicted by a learned error pinpoint model for iterative refinement. FITO starts with an initial output, then iteratively incorporates the feedback via a refinement model that generates an improved output conditioned on the feedback. Given the uncertainty of consistent refined samples at iterative steps, we formulate iterative refinement into a local search problem and develop a simulated annealing based algorithm that balances exploration of the search space and optimization for output quality. We conduct experiments on three text generation tasks, including machine translation, long-form question answering (QA) and topical summarization. We observe 0.8 and 0.7 MetricX gain on Chinese-English and English-German translation, 4.5 and 1.8 ROUGE-L gain at long form QA and topic summarization respectively, with a single iteration of refinement. With our simulated annealing algorithm, we see further quality improvements, including up to 1.7 MetricX improvements over the baseline approach.
On the Foundation of Distributionally Robust Reinforcement Learning
Nov 15, 2023Motivated by the need for a robust policy in the face of environment shifts between training and the deployment, we contribute to the theoretical foundation of distributionally robust reinforcement learning (DRRL). This is accomplished through a comprehensive modeling framework centered around distributionally robust Markov decision processes (DRMDPs). This framework obliges the decision maker to choose an optimal policy under the worst-case distributional shift orchestrated by an adversary. By unifying and extending existing formulations, we rigorously construct DRMDPs that embraces various modeling attributes for both the decision maker and the adversary. These attributes include adaptability granularity, exploring history-dependent, Markov, and Markov time-homogeneous decision maker and adversary dynamics. Additionally, we delve into the flexibility of shifts induced by the adversary, examining SA and S-rectangularity. Within this DRMDP framework, we investigate conditions for the existence or absence of the dynamic programming principle (DPP). From an algorithmic standpoint, the existence of DPP holds significant implications, as the vast majority of existing data and computationally efficiency RL algorithms are reliant on the DPP. To study its existence, we comprehensively examine combinations of controller and adversary attributes, providing streamlined proofs grounded in a unified methodology. We also offer counterexamples for settings in which a DPP with full generality is absent.
Multistage Collaborative Knowledge Distillation from Large Language Models
Nov 15, 2023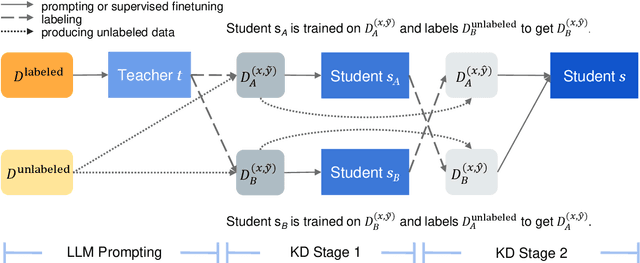
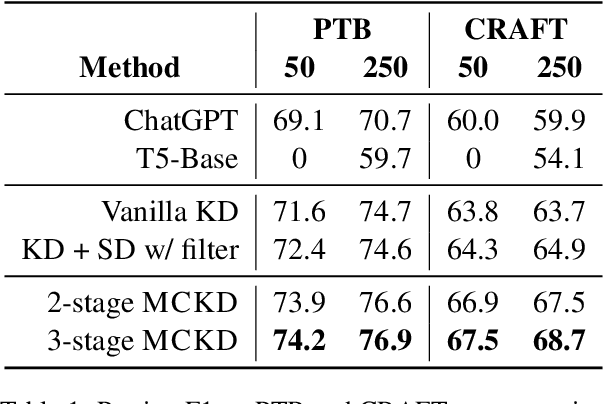
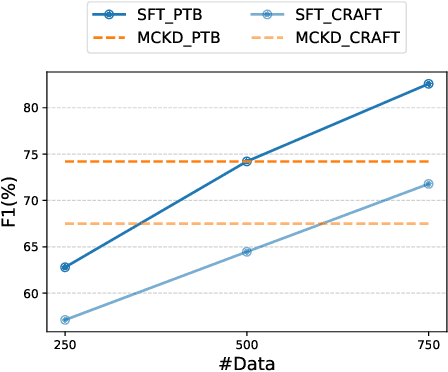
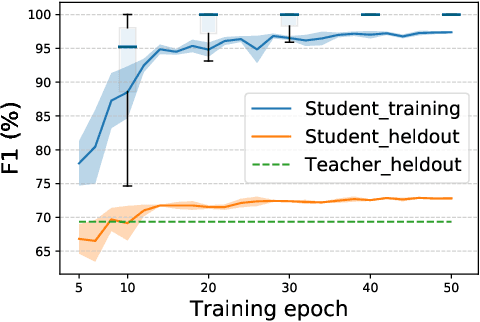
We study semi-supervised sequence prediction tasks where labeled data are too scarce to effectively finetune a model and at the same time few-shot prompting of a large language model (LLM) has suboptimal performance. This happens when a task, such as parsing, is expensive to annotate and also unfamiliar to a pretrained LLM. In this paper, we present a discovery that student models distilled from a prompted LLM can often generalize better than their teacher on such tasks. Leveraging this finding, we propose a new distillation method, multistage collaborative knowledge distillation from an LLM (MCKD), for such tasks. MCKD first prompts an LLM using few-shot in-context learning to produce pseudolabels for unlabeled data. Then, at each stage of distillation, a pair of students are trained on disjoint partitions of the pseudolabeled data. Each student subsequently produces new and improved pseudolabels for the unseen partition to supervise the next round of student(s) with. We show the benefit of multistage cross-partition labeling on two constituency parsing tasks. On CRAFT biomedical parsing, 3-stage MCKD with 50 labeled examples matches the performance of supervised finetuning with 500 examples and outperforms the prompted LLM and vanilla KD by 7.5% and 3.7% parsing F1, respectively.
Multiple-Question Multiple-Answer Text-VQA
Nov 15, 2023We present Multiple-Question Multiple-Answer (MQMA), a novel approach to do text-VQA in encoder-decoder transformer models. The text-VQA task requires a model to answer a question by understanding multi-modal content: text (typically from OCR) and an associated image. To the best of our knowledge, almost all previous approaches for text-VQA process a single question and its associated content to predict a single answer. In order to answer multiple questions from the same image, each question and content are fed into the model multiple times. In contrast, our proposed MQMA approach takes multiple questions and content as input at the encoder and predicts multiple answers at the decoder in an auto-regressive manner at the same time. We make several novel architectural modifications to standard encoder-decoder transformers to support MQMA. We also propose a novel MQMA denoising pre-training task which is designed to teach the model to align and delineate multiple questions and content with associated answers. MQMA pre-trained model achieves state-of-the-art results on multiple text-VQA datasets, each with strong baselines. Specifically, on OCR-VQA (+2.5%), TextVQA (+1.4%), ST-VQA (+0.6%), DocVQA (+1.1%) absolute improvements over the previous state-of-the-art approaches.
Nondestructive, quantitative viability analysis of 3D tissue cultures using machine learning image segmentation
Nov 15, 2023Ascertaining the collective viability of cells in different cell culture conditions has typically relied on averaging colorimetric indicators and is often reported out in simple binary readouts. Recent research has combined viability assessment techniques with image-based deep-learning models to automate the characterization of cellular properties. However, further development of viability measurements to assess the continuity of possible cellular states and responses to perturbation across cell culture conditions is needed. In this work, we demonstrate an image processing algorithm for quantifying cellular viability in 3D cultures without the need for assay-based indicators. We show that our algorithm performs similarly to a pair of human experts in whole-well images over a range of days and culture matrix compositions. To demonstrate potential utility, we perform a longitudinal study investigating the impact of a known therapeutic on pancreatic cancer spheroids. Using images taken with a high content imaging system, the algorithm successfully tracks viability at the individual spheroid and whole-well level. The method we propose reduces analysis time by 97% in comparison to the experts. Because the method is independent of the microscope or imaging system used, this approach lays the foundation for accelerating progress in and for improving the robustness and reproducibility of 3D culture analysis across biological and clinical research.
User-level Differentially Private Stochastic Convex Optimization: Efficient Algorithms with Optimal Rates
Nov 07, 2023We study differentially private stochastic convex optimization (DP-SCO) under user-level privacy, where each user may hold multiple data items. Existing work for user-level DP-SCO either requires super-polynomial runtime [Ghazi et al. (2023)] or requires the number of users to grow polynomially with the dimensionality of the problem with additional strict assumptions [Bassily et al. (2023)]. We develop new algorithms for user-level DP-SCO that obtain optimal rates for both convex and strongly convex functions in polynomial time and require the number of users to grow only logarithmically in the dimension. Moreover, our algorithms are the first to obtain optimal rates for non-smooth functions in polynomial time. These algorithms are based on multiple-pass DP-SGD, combined with a novel private mean estimation procedure for concentrated data, which applies an outlier removal step before estimating the mean of the gradients.
Consistent Aggregation of Objectives with Diverse Time Preferences Requires Non-Markovian Rewards
Sep 30, 2023As the capabilities of artificial agents improve, they are being increasingly deployed to service multiple diverse objectives and stakeholders. However, the composition of these objectives is often performed ad hoc, with no clear justification. This paper takes a normative approach to multi-objective agency: from a set of intuitively appealing axioms, it is shown that Markovian aggregation of Markovian reward functions is not possible when the time preference (discount factor) for each objective may vary. It follows that optimal multi-objective agents must admit rewards that are non-Markovian with respect to the individual objectives. To this end, a practical non-Markovian aggregation scheme is proposed, which overcomes the impossibility with only one additional parameter for each objective. This work offers new insights into sequential, multi-objective agency and intertemporal choice, and has practical implications for the design of AI systems deployed to serve multiple generations of principals with varying time preference.