 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast Chain-of-Thought: A Glance of Future from Parallel Decoding Leads to Answers Faster
Nov 14, 2023
In this work, we propose FastCoT, a model-agnostic framework based on parallel decoding without any further training of an auxiliary model or modification to the LLM itself. FastCoT uses a size-varying context window whose size changes with position to conduct parallel decoding and auto-regressive decoding simultaneously, thus fully utilizing GPU computation resources. In FastCoT, the parallel decoding part provides the LLM with a quick glance of the future composed of approximate tokens, which could lead to faster answers compared to regular autoregressive decoding used by causal transformers. We also provide an implementation of parallel decoding within LLM, which supports KV-cache generation and batch processing. Through extensive experiments, we demonstrate that FastCoT saves inference time by nearly 20% with only a negligible performance drop compared to the regular approach. Additionally, we show that the context window size exhibits considerable robustness for different tasks.
Labeling Indoor Scenes with Fusion of Out-of-the-Box Perception Models
Nov 17, 2023The image annotation stage is a critical and often the most time-consuming part required for training and evaluating object detection and semantic segmentation models. Deployment of the existing models in novel environments often requires detecting novel semantic classes not present in the training data. Furthermore, indoor scenes contain significant viewpoint variations, which need to be handled properly by trained perception models. We propose to leverage the recent advancements in state-of-the-art models for bottom-up segmentation (SAM), object detection (Detic), and semantic segmentation (MaskFormer), all trained on large-scale datasets. We aim to develop a cost-effective labeling approach to obtain pseudo-labels for semantic segmentation and object instance detection in indoor environments, with the ultimate goal of facilitating the training of lightweight models for various downstream tasks. We also propose a multi-view labeling fusion stage, which considers the setting where multiple views of the scenes are available and can be used to identify and rectify single-view inconsistencies. We demonstrate the effectiveness of the proposed approach on the Active Vision dataset and the ADE20K dataset. We evaluate the quality of our labeling process by comparing it with human annotations. Also, we demonstrate the effectiveness of the obtained labels in downstream tasks such as object goal navigation and part discovery. In the context of object goal navigation, we depict enhanced performance using this fusion approach compared to a zero-shot baseline that utilizes large monolithic vision-language pre-trained models.
Learning transformer-based heterogeneously salient graph representation for multimodal fusion classification of hyperspectral image and LiDAR data
Nov 17, 2023Data collected by different modalities can provide a wealth of complementary information, such as hyperspectral image (HSI) to offer rich spectral-spatial properties, synthetic aperture radar (SAR) to provide structural information about the Earth's surface, and light detection and ranging (LiDAR) to cover altitude information about ground elevation. Therefore, a natural idea is to combine multimodal images for refined and accurate land-cover interpretation. Although many efforts have been attempted to achieve multi-source remote sensing image classification, there are still three issues as follows: 1) indiscriminate feature representation without sufficiently considering modal heterogeneity, 2) abundant features and complex computations associated with modeling long-range dependencies, and 3) overfitting phenomenon caused by sparsely labeled samples. To overcome the above barriers, a transformer-based heterogeneously salient graph representation (THSGR) approach is proposed in this paper. First, a multimodal heterogeneous graph encoder is presented to encode distinctively non-Euclidean structural features from heterogeneous data. Then, a self-attention-free multi-convolutional modulator is designed for effective and efficient long-term dependency modeling. Finally, a mean forward is put forward in order to avoid overfitting. Based on the above structures, the proposed model is able to break through modal gaps to obtain differentiated graph representation with competitive time cost, even for a small fraction of training samples. Experiments and analyses on three benchmark datasets with various state-of-the-art (SOTA) methods show the performance of the proposed approach.
Breaking Boundaries: Balancing Performance and Robustness in Deep Wireless Traffic Forecasting
Nov 17, 2023Balancing the trade-off between accuracy and robustness is a long-standing challenge in time series forecasting. While most of existing robust algorithms have achieved certain suboptimal performance on clean data, sustaining the same performance level in the presence of data perturbations remains extremely hard. In this paper, we study a wide array of perturbation scenarios and propose novel defense mechanisms against adversarial attacks using real-world telecom data. We compare our strategy against two existing adversarial training algorithms under a range of maximal allowed perturbations, defined using $\ell_{\infty}$-norm, $\in [0.1,0.4]$. Our findings reveal that our hybrid strategy, which is composed of a classifier to detect adversarial examples, a denoiser to eliminate noise from the perturbed data samples, and a standard forecaster, achieves the best performance on both clean and perturbed data. Our optimal model can retain up to $92.02\%$ the performance of the original forecasting model in terms of Mean Squared Error (MSE) on clean data, while being more robust than the standard adversarially trained models on perturbed data. Its MSE is 2.71$\times$ and 2.51$\times$ lower than those of comparing methods on normal and perturbed data, respectively. In addition, the components of our models can be trained in parallel, resulting in better computational efficiency. Our results indicate that we can optimally balance the trade-off between the performance and robustness of forecasting models by improving the classifier and denoiser, even in the presence of sophisticated and destructive poisoning attacks.
Anytime-Constrained Reinforcement Learning
Nov 09, 2023We introduce and study constrained Markov Decision Processes (cMDPs) with anytime constraints. An anytime constraint requires the agent to never violate its budget at any point in time, almost surely. Although Markovian policies are no longer sufficient, we show that there exist optimal deterministic policies augmented with cumulative costs. In fact, we present a fixed-parameter tractable reduction from anytime-constrained cMDPs to unconstrained MDPs. Our reduction yields planning and learning algorithms that are time and sample-efficient for tabular cMDPs so long as the precision of the costs is logarithmic in the size of the cMDP. However, we also show that computing non-trivial approximately optimal policies is NP-hard in general. To circumvent this bottleneck, we design provable approximation algorithms that efficiently compute or learn an approximately feasible policy with optimal value so long as the maximum supported cost is bounded by a polynomial in the cMDP or by the absolute budget. Given our hardness results, our approximation guarantees are the best possible in terms of tractability under worst-case analysis.
Towards Generic Anomaly Detection and Understanding: Large-scale Visual-linguistic Model (GPT-4V) Takes the Lead
Nov 16, 2023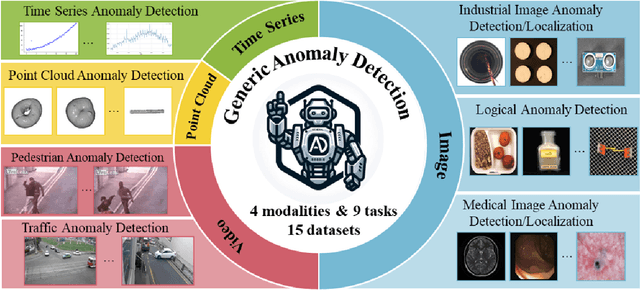
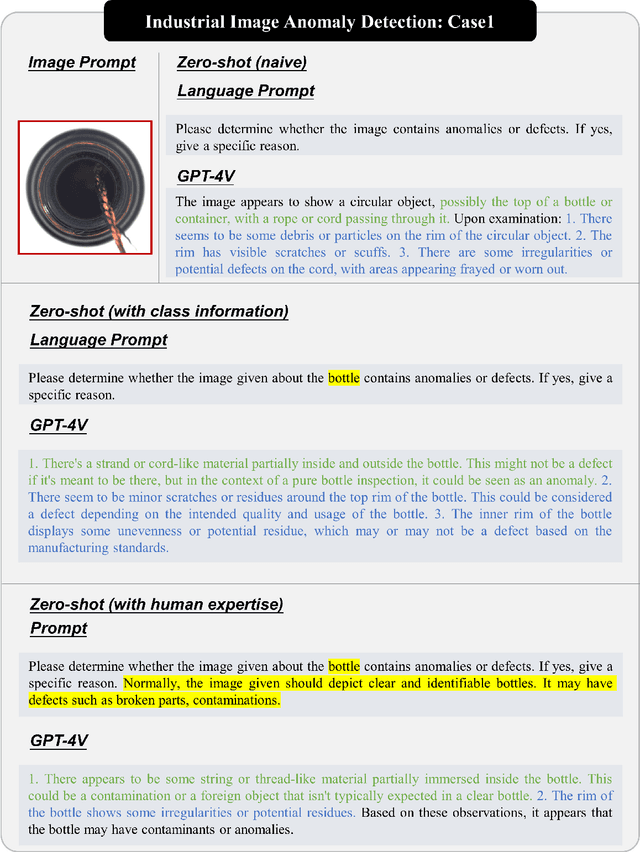

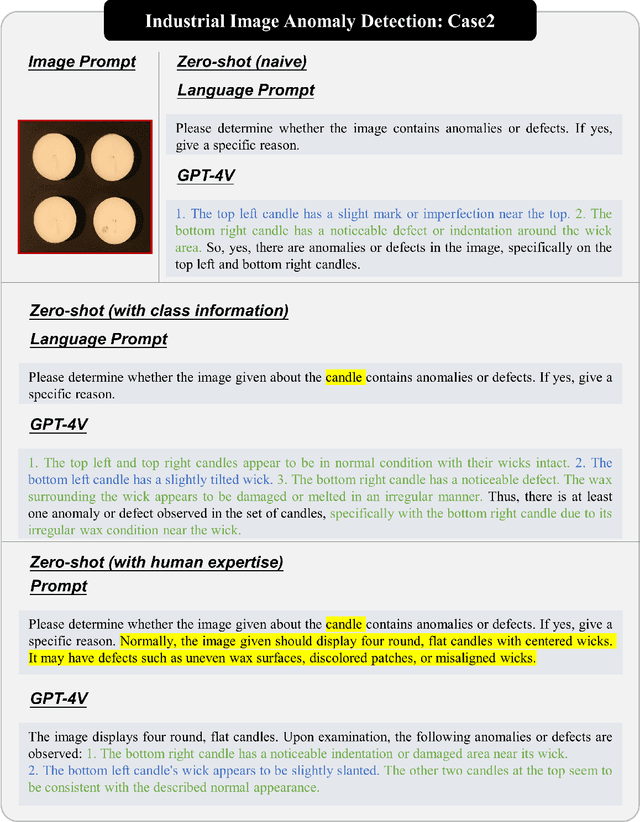
Anomaly detection is a crucial task across different domains and data types. However, existing anomaly detection models are often designed for specific domains and modalities. This study explores the use of GPT-4V(ision), a powerful visual-linguistic model, to address anomaly detection tasks in a generic manner. We investigate the application of GPT-4V in multi-modality, multi-domain anomaly detection tasks, including image, video, point cloud, and time series data, across multiple application areas, such as industrial, medical, logical, video, 3D anomaly detection, and localization tasks. To enhance GPT-4V's performance, we incorporate different kinds of additional cues such as class information, human expertise, and reference images as prompts.Based on our experiments, GPT-4V proves to be highly effective in detecting and explaining global and fine-grained semantic patterns in zero/one-shot anomaly detection. This enables accurate differentiation between normal and abnormal instances. Although we conducted extensive evaluations in this study, there is still room for future evaluation to further exploit GPT-4V's generic anomaly detection capacity from different aspects. These include exploring quantitative metrics, expanding evaluation benchmarks, incorporating multi-round interactions, and incorporating human feedback loops. Nevertheless, GPT-4V exhibits promising performance in generic anomaly detection and understanding, thus opening up a new avenue for anomaly detection.
Interpretable Reinforcement Learning for Robotics and Continuous Control
Nov 16, 2023Interpretability in machine learning is critical for the safe deployment of learned policies across legally-regulated and safety-critical domains. While gradient-based approaches in reinforcement learning have achieved tremendous success in learning policies for continuous control problems such as robotics and autonomous driving, the lack of interpretability is a fundamental barrier to adoption. We propose Interpretable Continuous Control Trees (ICCTs), a tree-based model that can be optimized via modern, gradient-based, reinforcement learning approaches to produce high-performing, interpretable policies. The key to our approach is a procedure for allowing direct optimization in a sparse decision-tree-like representation. We validate ICCTs against baselines across six domains, showing that ICCTs are capable of learning policies that parity or outperform baselines by up to 33% in autonomous driving scenarios while achieving a 300x-600x reduction in the number of parameters against deep learning baselines. We prove that ICCTs can serve as universal function approximators and display analytically that ICCTs can be verified in linear time. Furthermore, we deploy ICCTs in two realistic driving domains, based on interstate Highway-94 and 280 in the US. Finally, we verify ICCT's utility with end-users and find that ICCTs are rated easier to simulate, quicker to validate, and more interpretable than neural networks.
Interpreting User Requests in the Context of Natural Language Standing Instructions
Nov 16, 2023Users of natural language interfaces, generally powered by Large Language Models (LLMs),often must repeat their preferences each time they make a similar request. To alleviate this, we propose including some of a user's preferences and instructions in natural language -- collectively termed standing instructions -- as additional context for such interfaces. For example, when a user states I'm hungry, their previously expressed preference for Persian food will be automatically added to the LLM prompt, so as to influence the search for relevant restaurants. We develop NLSI, a language-to-program dataset consisting of over 2.4K dialogues spanning 17 domains, where each dialogue is paired with a user profile (a set of users specific standing instructions) and corresponding structured representations (API calls). A key challenge in NLSI is to identify which subset of the standing instructions is applicable to a given dialogue. NLSI contains diverse phenomena, from simple preferences to interdependent instructions such as triggering a hotel search whenever the user is booking tickets to an event. We conduct experiments on NLSI using prompting with large language models and various retrieval approaches, achieving a maximum of 44.7% exact match on API prediction. Our results demonstrate the challenges in identifying the relevant standing instructions and their interpretation into API calls.
What Constitutes a Faithful Summary? Preserving Author Perspectives in News Summarization
Nov 16, 2023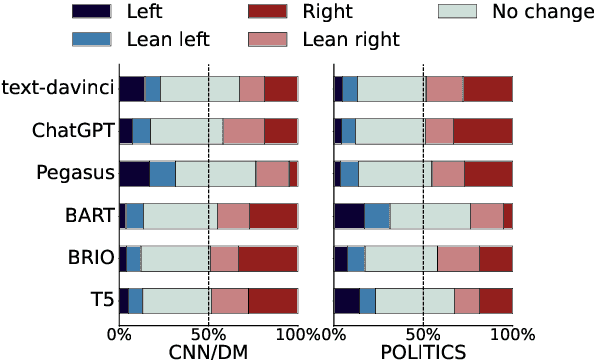
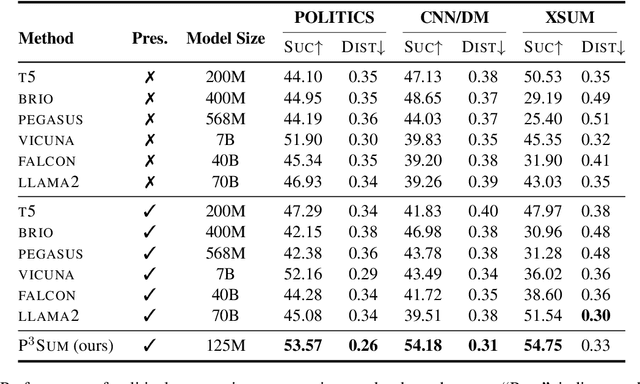
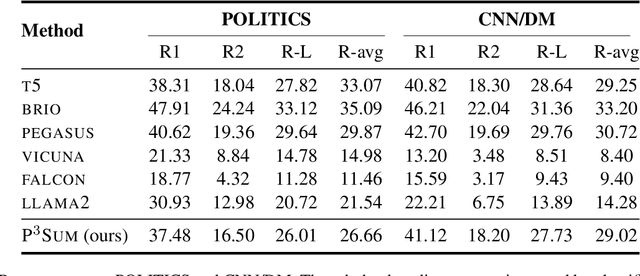
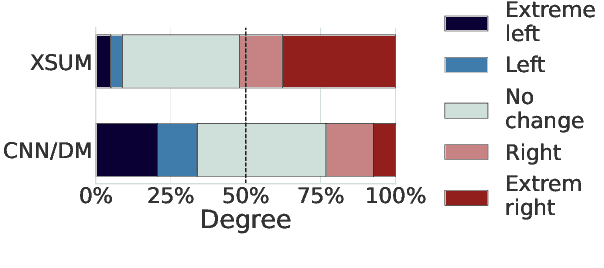
In this work, we take a first step towards designing summarization systems that are faithful to the author's opinions and perspectives. Focusing on a case study of preserving political perspectives in news summarization, we find that existing approaches alter the political opinions and stances of news articles in more than 50% of summaries, misrepresenting the intent and perspectives of the news authors. We thus propose P^3Sum, a diffusion model-based summarization approach controlled by political perspective classifiers. In P^3Sum, the political leaning of a generated summary is iteratively evaluated at each decoding step, and any drift from the article's original stance incurs a loss back-propagated to the embedding layers, steering the political stance of the summary at inference time. Extensive experiments on three news summarization datasets demonstrate that P^3Sum outperforms state-of-the-art summarization systems and large language models by up to 11.4% in terms of the success rate of stance preservation, with on-par performance on standard summarization utility metrics. These findings highlight the lacunae that even for state-of-the-art models it is still challenging to preserve author perspectives in news summarization, while P^3Sum presents an important first step towards evaluating and developing summarization systems that are faithful to author intent and perspectives.
Towards an Automatic AI Agent for Reaction Condition Recommendation in Chemical Synthesis
Nov 16, 2023Artificial intelligence (AI) for reaction condition optimization has become an important topic in the pharmaceutical industry, given that a data-driven AI model can assist drug discovery and accelerate reaction design. However, existing AI models lack the chemical insights and real-time knowledge acquisition abilities of experienced human chemists. This paper proposes a Large Language Model (LLM) empowered AI agent to bridge this gap. We put forth a novel three-phase paradigm and applied advanced intelligence-enhancement methods like in-context learning and multi-LLM debate so that the AI agent can borrow human insight and update its knowledge by searching the latest chemical literature. Additionally, we introduce a novel Coarse-label Contrastive Learning (CCL) based chemical fingerprint that greatly enhances the agent's performance in optimizing the reaction condition. With the above efforts, the proposed AI agent can autonomously generate the optimal reaction condition recommendation without any human interaction. Further, the agent is highly professional in terms of chemical reactions. It demonstrates close-to-human performance and strong generalization capability in both dry-lab and wet-lab experiments. As the first attempt in the chemical AI agent, this work goes a step further in the field of "AI for chemistry" and opens up new possibilities for computer-aided synthesis planning.