 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Radiology Report Generation Using Transformers Conditioned with Non-imaging Data
Nov 18, 2023
Medical image interpretation is central to most clinical applications such as disease diagnosis, treatment planning, and prognostication. In clinical practice, radiologists examine medical images and manually compile their findings into reports, which can be a time-consuming process. Automated approaches to radiology report generation, therefore, can reduce radiologist workload and improve efficiency in the clinical pathway. While recent deep-learning approaches for automated report generation from medical images have seen some success, most studies have relied on image-derived features alone, ignoring non-imaging patient data. Although a few studies have included the word-level contexts along with the image, the use of patient demographics is still unexplored. This paper proposes a novel multi-modal transformer network that integrates chest x-ray (CXR) images and associated patient demographic information, to synthesise patient-specific radiology reports. The proposed network uses a convolutional neural network to extract visual features from CXRs and a transformer-based encoder-decoder network that combines the visual features with semantic text embeddings of patient demographic information, to synthesise full-text radiology reports. Data from two public databases were used to train and evaluate the proposed approach. CXRs and reports were extracted from the MIMIC-CXR database and combined with corresponding patients' data MIMIC-IV. Based on the evaluation metrics used including patient demographic information was found to improve the quality of reports generated using the proposed approach, relative to a baseline network trained using CXRs alone. The proposed approach shows potential for enhancing radiology report generation by leveraging rich patient metadata and combining semantic text embeddings derived thereof, with medical image-derived visual features.
TOPPQuad: Dynamically-Feasible Time Optimal Path Parametrization for Quadrotors
Sep 20, 2023
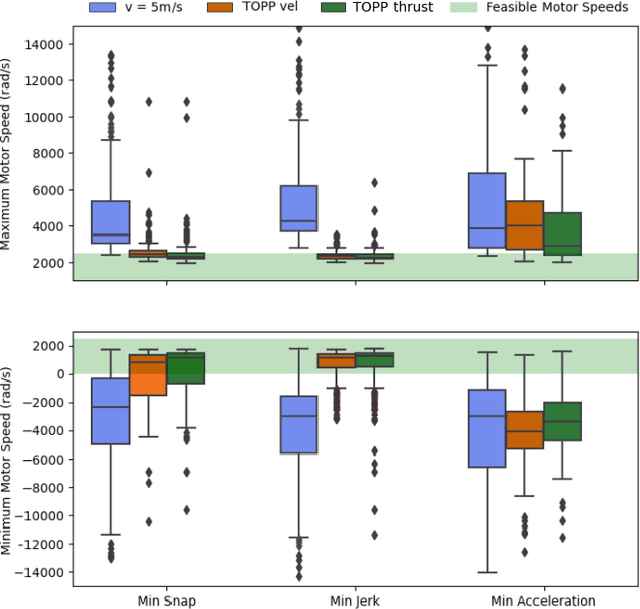
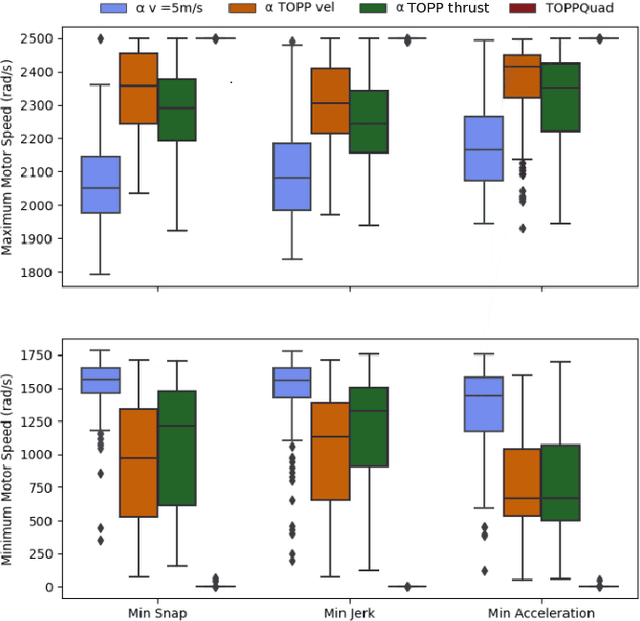
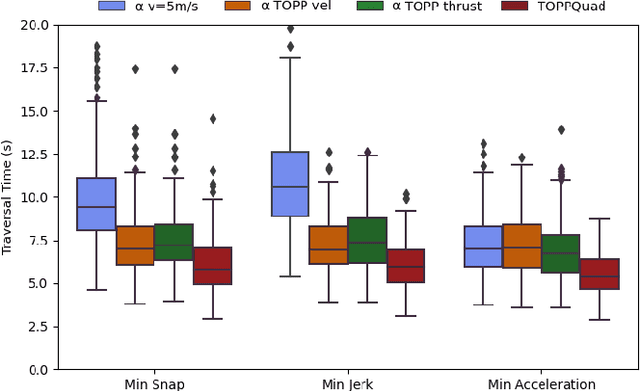
Planning time-optimal trajectories for quadrotors in cluttered environments is a challenging, non-convex problem. This paper addresses minimizing the traversal time of a given collision-free geometric path without violating bounds on individual motor thrusts of the vehicle. Previous approaches have either relied on convex relaxations that do not guarantee dynamic feasibility, or have generated overly conservative time parametrizations. We propose TOPPQuad, a time-optimal path parameterization algorithm for quadrotors which explicitly incorporates quadrotor rigid body dynamics and constraints such as bounds on inputs (including motor speeds) and state of the vehicle (including the pose, linear and angular velocity and acceleration). We demonstrate the ability of the planner to generate faster trajectories that respect hardware constraints of the robot compared to several planners with relaxed notions of dynamic feasibility. We also demonstrate how TOPPQuad can be used to plan trajectories for quadrotors that utilize bidirectional motors. Overall, the proposed approach paves a way towards maximizing the efficacy of autonomous micro aerial vehicles while ensuring their safety.
Non-Orthogonal Time-Frequency Space Modulation
Sep 19, 2023This paper proposes a Time-Frequency Space Transformation (TFST) to derive non-orthogonal bases for modulation techniques over the delay-doppler plane. A family of Overloaded Delay-Doppler Modulation (ODDM) techniques is proposed based on the TFST, which enhances flexibility and efficiency by expressing modulated signals as a linear combination of basis signals. A Non-Orthogonal Time-Frequency Space (NOTFS) digital modulation is derived for the proposed ODDM techniques, and simulations show that they offer high-mobility communication systems with improved spectral efficiency and low latency, particularly in challenging scenarios such as high overloading factors and Additive White Gaussian Noise (AWGN) channels. A modified sphere decoding algorithm is also presented to efficiently decode the received signal. The proposed modulation and decoding techniques contribute to the advancement of non-orthogonal approaches in the next-generation of mobile communication systems, delivering superior spectral efficiency and low latency, and offering a promising solution towards the development of efficient high-mobility communication systems.
Improving fit to human reading times via temperature-scaled surprisal
Nov 15, 2023Past studies have provided broad support for that words with lower predictability (i.e., higher surprisal) require more time for comprehension by using large language models (LLMs) to simulate humans' cognitive load. In general, these studies have implicitly assumed that the probability scores from LLMs are accurate, ignoring the discrepancies between human cognition and LLMs from this standpoint. Inspired by the concept of probability calibration, we are the first work to focus on the probability distribution for human reading simulation. We propose to use temperature-scaled surprisal, a surprisal calculated by shaped probability, to be the predictor of human reading times. Our results across three corpora consistently revealed that such a surprisal can drastically improve the prediction of reading times. Setting the temperature to be approximately 2.5 across all models and datasets can yield up to an 89% of increase in delta log-likelihood in our setting. We also propose a calibration metric to quantify the possible human-likeness bias. Further analysis was done and provided insights into this phenomenon.
Coreset Selection with Prioritized Multiple Objectives
Nov 15, 2023Coreset selection is powerful in reducing computational costs and accelerating data processing for deep learning algorithms. It strives to identify a small subset from large-scale data, so that training only on the subset practically performs on par with full data. When coreset selection is applied in realistic scenes, under the premise that the identified coreset has achieved comparable model performance, practitioners regularly desire the identified coreset can have a size as small as possible for lower costs and greater acceleration. Motivated by this desideratum, for the first time, we pose the problem of "coreset selection with prioritized multiple objectives", in which the smallest coreset size under model performance constraints is explored. Moreover, to address this problem, an innovative method is proposed, which maintains optimization priority order over the model performance and coreset size, and efficiently optimizes them in the coreset selection procedure. Theoretically, we provide the convergence guarantee of the proposed method. Empirically, extensive experiments confirm its superiority compared with previous strategies, often yielding better model performance with smaller coreset sizes.
Fast Chain-of-Thought: A Glance of Future from Parallel Decoding Leads to Answers Faster
Nov 14, 2023In this work, we propose FastCoT, a model-agnostic framework based on parallel decoding without any further training of an auxiliary model or modification to the LLM itself. FastCoT uses a size-varying context window whose size changes with position to conduct parallel decoding and auto-regressive decoding simultaneously, thus fully utilizing GPU computation resources. In FastCoT, the parallel decoding part provides the LLM with a quick glance of the future composed of approximate tokens, which could lead to faster answers compared to regular autoregressive decoding used by causal transformers. We also provide an implementation of parallel decoding within LLM, which supports KV-cache generation and batch processing. Through extensive experiments, we demonstrate that FastCoT saves inference time by nearly 20% with only a negligible performance drop compared to the regular approach. Additionally, we show that the context window size exhibits considerable robustness for different tasks.
Labeling Indoor Scenes with Fusion of Out-of-the-Box Perception Models
Nov 17, 2023The image annotation stage is a critical and often the most time-consuming part required for training and evaluating object detection and semantic segmentation models. Deployment of the existing models in novel environments often requires detecting novel semantic classes not present in the training data. Furthermore, indoor scenes contain significant viewpoint variations, which need to be handled properly by trained perception models. We propose to leverage the recent advancements in state-of-the-art models for bottom-up segmentation (SAM), object detection (Detic), and semantic segmentation (MaskFormer), all trained on large-scale datasets. We aim to develop a cost-effective labeling approach to obtain pseudo-labels for semantic segmentation and object instance detection in indoor environments, with the ultimate goal of facilitating the training of lightweight models for various downstream tasks. We also propose a multi-view labeling fusion stage, which considers the setting where multiple views of the scenes are available and can be used to identify and rectify single-view inconsistencies. We demonstrate the effectiveness of the proposed approach on the Active Vision dataset and the ADE20K dataset. We evaluate the quality of our labeling process by comparing it with human annotations. Also, we demonstrate the effectiveness of the obtained labels in downstream tasks such as object goal navigation and part discovery. In the context of object goal navigation, we depict enhanced performance using this fusion approach compared to a zero-shot baseline that utilizes large monolithic vision-language pre-trained models.
Learning transformer-based heterogeneously salient graph representation for multimodal fusion classification of hyperspectral image and LiDAR data
Nov 17, 2023Data collected by different modalities can provide a wealth of complementary information, such as hyperspectral image (HSI) to offer rich spectral-spatial properties, synthetic aperture radar (SAR) to provide structural information about the Earth's surface, and light detection and ranging (LiDAR) to cover altitude information about ground elevation. Therefore, a natural idea is to combine multimodal images for refined and accurate land-cover interpretation. Although many efforts have been attempted to achieve multi-source remote sensing image classification, there are still three issues as follows: 1) indiscriminate feature representation without sufficiently considering modal heterogeneity, 2) abundant features and complex computations associated with modeling long-range dependencies, and 3) overfitting phenomenon caused by sparsely labeled samples. To overcome the above barriers, a transformer-based heterogeneously salient graph representation (THSGR) approach is proposed in this paper. First, a multimodal heterogeneous graph encoder is presented to encode distinctively non-Euclidean structural features from heterogeneous data. Then, a self-attention-free multi-convolutional modulator is designed for effective and efficient long-term dependency modeling. Finally, a mean forward is put forward in order to avoid overfitting. Based on the above structures, the proposed model is able to break through modal gaps to obtain differentiated graph representation with competitive time cost, even for a small fraction of training samples. Experiments and analyses on three benchmark datasets with various state-of-the-art (SOTA) methods show the performance of the proposed approach.
Breaking Boundaries: Balancing Performance and Robustness in Deep Wireless Traffic Forecasting
Nov 17, 2023Balancing the trade-off between accuracy and robustness is a long-standing challenge in time series forecasting. While most of existing robust algorithms have achieved certain suboptimal performance on clean data, sustaining the same performance level in the presence of data perturbations remains extremely hard. In this paper, we study a wide array of perturbation scenarios and propose novel defense mechanisms against adversarial attacks using real-world telecom data. We compare our strategy against two existing adversarial training algorithms under a range of maximal allowed perturbations, defined using $\ell_{\infty}$-norm, $\in [0.1,0.4]$. Our findings reveal that our hybrid strategy, which is composed of a classifier to detect adversarial examples, a denoiser to eliminate noise from the perturbed data samples, and a standard forecaster, achieves the best performance on both clean and perturbed data. Our optimal model can retain up to $92.02\%$ the performance of the original forecasting model in terms of Mean Squared Error (MSE) on clean data, while being more robust than the standard adversarially trained models on perturbed data. Its MSE is 2.71$\times$ and 2.51$\times$ lower than those of comparing methods on normal and perturbed data, respectively. In addition, the components of our models can be trained in parallel, resulting in better computational efficiency. Our results indicate that we can optimally balance the trade-off between the performance and robustness of forecasting models by improving the classifier and denoiser, even in the presence of sophisticated and destructive poisoning attacks.
Continual Test-time Domain Adaptation via Dynamic Sample Selection
Oct 05, 2023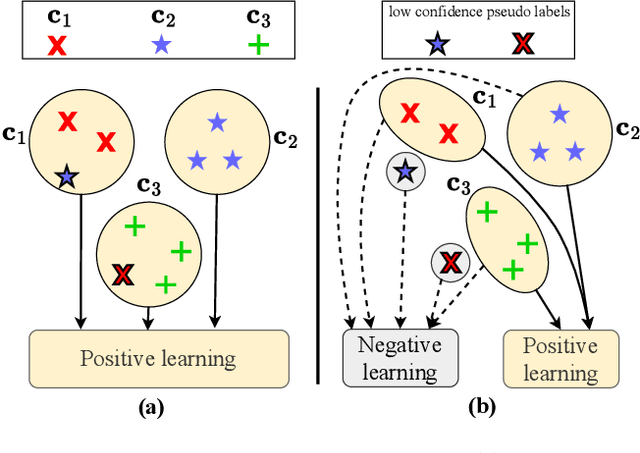

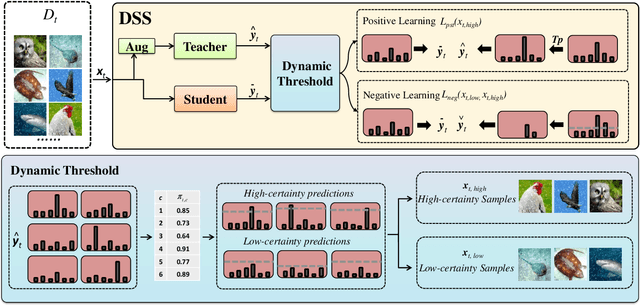

The objective of Continual Test-time Domain Adaptation (CTDA) is to gradually adapt a pre-trained model to a sequence of target domains without accessing the source data. This paper proposes a Dynamic Sample Selection (DSS) method for CTDA. DSS consists of dynamic thresholding, positive learning, and negative learning processes. Traditionally, models learn from unlabeled unknown environment data and equally rely on all samples' pseudo-labels to update their parameters through self-training. However, noisy predictions exist in these pseudo-labels, so all samples are not equally trustworthy. Therefore, in our method, a dynamic thresholding module is first designed to select suspected low-quality from high-quality samples. The selected low-quality samples are more likely to be wrongly predicted. Therefore, we apply joint positive and negative learning on both high- and low-quality samples to reduce the risk of using wrong information. We conduct extensive experiments that demonstrate the effectiveness of our proposed method for CTDA in the image domain, outperforming the state-of-the-art results. Furthermore, our approach is also evaluated in the 3D point cloud domain, showcasing its versatility and potential for broader applicability.