 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Intelligent Cervical Spine Fracture Detection Using Deep Learning Methods
Nov 09, 2023
Cervical spine fractures constitute a critical medical emergency, with the potential for lifelong paralysis or even fatality if left untreated or undetected. Over time, these fractures can deteriorate without intervention. To address the lack of research on the practical application of deep learning techniques for the detection of spine fractures, this study leverages a dataset containing both cervical spine fractures and non-fractured computed tomography images. This paper introduces a two-stage pipeline designed to identify the presence of cervical vertebrae in each image slice and pinpoint the location of fractures. In the first stage, a multi-input network, incorporating image and image metadata, is trained. This network is based on the Global Context Vision Transformer, and its performance is benchmarked against popular deep learning image classification model. In the second stage, a YOLOv8 model is trained to detect fractures within the images, and its effectiveness is compared to YOLOv5. The obtained results indicate that the proposed algorithm significantly reduces the workload of radiologists and enhances the accuracy of fracture detection.
Inference for Probabilistic Dependency Graphs
Nov 09, 2023Probabilistic dependency graphs (PDGs) are a flexible class of probabilistic graphical models, subsuming Bayesian Networks and Factor Graphs. They can also capture inconsistent beliefs, and provide a way of measuring the degree of this inconsistency. We present the first tractable inference algorithm for PDGs with discrete variables, making the asymptotic complexity of PDG inference similar that of the graphical models they generalize. The key components are: (1) the observation that, in many cases, the distribution a PDG specifies can be formulated as a convex optimization problem (with exponential cone constraints), (2) a construction that allows us to express these problems compactly for PDGs of boundeed treewidth, (3) contributions to the theory of PDGs that justify the construction, and (4) an appeal to interior point methods that can solve such problems in polynomial time. We verify the correctness and complexity of our approach, and provide an implementation of it. We then evaluate our implementation, and demonstrate that it outperforms baseline approaches. Our code is available at http://github.com/orichardson/pdg-infer-uai.
* extended version of the paper with corrected reduction proof
Using ResNet to Utilize 4-class T2-FLAIR Slice Classification Based on the Cholinergic Pathways Hyperintensities Scale for Pathological Aging
Nov 09, 2023The Cholinergic Pathways Hyperintensities Scale (CHIPS) is a visual rating scale used to assess the extent of cholinergic white matter hyperintensities in T2-FLAIR images, serving as an indicator of dementia severity. However, the manual selection of four specific slices for rating throughout the entire brain is a time-consuming process. Our goal was to develop a deep learning-based model capable of automatically identifying the four slices relevant to CHIPS. To achieve this, we trained a 4-class slice classification model (BSCA) using the ADNI T2-FLAIR dataset (N=150) with the assistance of ResNet. Subsequently, we tested the model's performance on a local dataset (N=30). The results demonstrated the efficacy of our model, with an accuracy of 99.82% and an F1-score of 99.83%. This achievement highlights the potential impact of BSCA as an automatic screening tool, streamlining the selection of four specific T2-FLAIR slices that encompass white matter landmarks along the cholinergic pathways. Clinicians can leverage this tool to assess the risk of clinical dementia development efficiently.
Object-centric Cross-modal Feature Distillation for Event-based Object Detection
Nov 09, 2023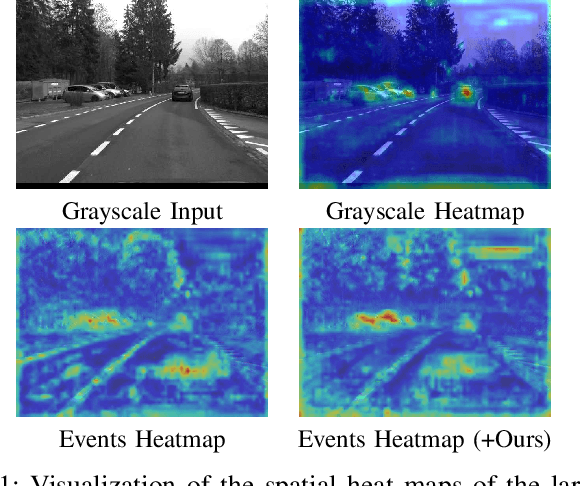
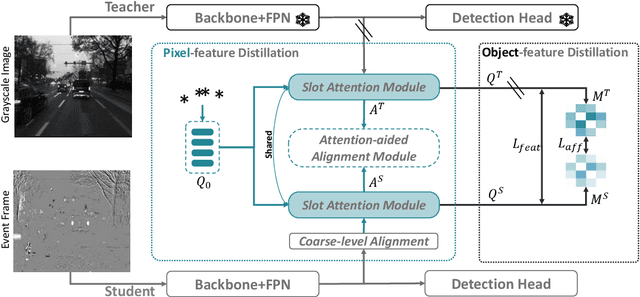
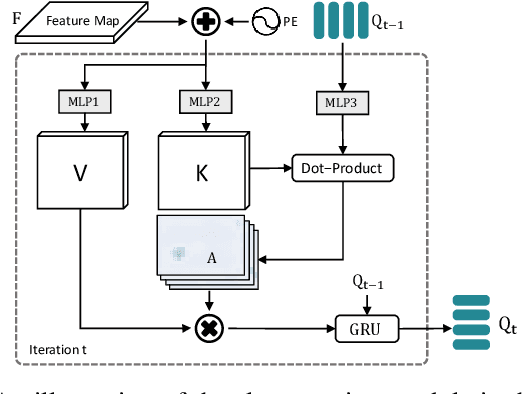
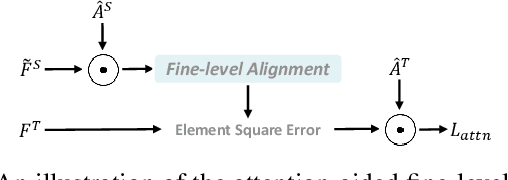
Event cameras are gaining popularity due to their unique properties, such as their low latency and high dynamic range. One task where these benefits can be crucial is real-time object detection. However, RGB detectors still outperform event-based detectors due to the sparsity of the event data and missing visual details. In this paper, we develop a novel knowledge distillation approach to shrink the performance gap between these two modalities. To this end, we propose a cross-modality object detection distillation method that by design can focus on regions where the knowledge distillation works best. We achieve this by using an object-centric slot attention mechanism that can iteratively decouple features maps into object-centric features and corresponding pixel-features used for distillation. We evaluate our novel distillation approach on a synthetic and a real event dataset with aligned grayscale images as a teacher modality. We show that object-centric distillation allows to significantly improve the performance of the event-based student object detector, nearly halving the performance gap with respect to the teacher.
Multi-label and Multi-target Sampling of Machine Annotation for Computational Stance Detection
Nov 08, 2023Data collection from manual labeling provides domain-specific and task-aligned supervision for data-driven approaches, and a critical mass of well-annotated resources is required to achieve reasonable performance in natural language processing tasks. However, manual annotations are often challenging to scale up in terms of time and budget, especially when domain knowledge, capturing subtle semantic features, and reasoning steps are needed. In this paper, we investigate the efficacy of leveraging large language models on automated labeling for computational stance detection. We empirically observe that while large language models show strong potential as an alternative to human annotators, their sensitivity to task-specific instructions and their intrinsic biases pose intriguing yet unique challenges in machine annotation. We introduce a multi-label and multi-target sampling strategy to optimize the annotation quality. Experimental results on the benchmark stance detection corpora show that our method can significantly improve performance and learning efficacy.
Improving Pacing in Long-Form Story Planning
Nov 08, 2023Existing LLM-based systems for writing long-form stories or story outlines frequently suffer from unnatural pacing, whether glossing over important events or over-elaborating on insignificant details, resulting in a jarring experience for the reader. We propose a CONCrete Outline ConTrol (CONCOCT) system to improve pacing when automatically generating story outlines. We first train a concreteness evaluator to judge which of two events is more concrete (low-level-detailed). This evaluator can then be used to control pacing in hierarchical outline generation; in this work, we explore a vaguest-first expansion procedure that aims for uniform pacing. We further use the evaluator to filter new outline items based on predicted concreteness. Compared to a baseline hierarchical outline generator, humans judge CONCOCT's pacing to be more consistent over 57% of the time across multiple outline lengths; the gains also translate to downstream stories. All code, data, and models are open-sourced.
Image Patch-Matching with Graph-Based Learning in Street Scenes
Nov 08, 2023Matching landmark patches from a real-time image captured by an on-vehicle camera with landmark patches in an image database plays an important role in various computer perception tasks for autonomous driving. Current methods focus on local matching for regions of interest and do not take into account spatial neighborhood relationships among the image patches, which typically correspond to objects in the environment. In this paper, we construct a spatial graph with the graph vertices corresponding to patches and edges capturing the spatial neighborhood information. We propose a joint feature and metric learning model with graph-based learning. We provide a theoretical basis for the graph-based loss by showing that the information distance between the distributions conditioned on matched and unmatched pairs is maximized under our framework. We evaluate our model using several street-scene datasets and demonstrate that our approach achieves state-of-the-art matching results.
Spoken Dialogue System for Medical Prescription Acquisition on Smartphone: Development, Corpus and Evaluation
Nov 06, 2023Hospital information systems (HIS) have become an essential part of healthcare institutions and now incorporate prescribing support software. Prescription support software allows for structured information capture, which improves the safety, appropriateness and efficiency of prescriptions and reduces the number of adverse drug events (ADEs). However, such a system increases the amount of time physicians spend at a computer entering information instead of providing medical care. In addition, any new visiting clinician must learn to manage complex interfaces since each HIS has its own interfaces. In this paper, we present a natural language interface for e-prescribing software in the form of a spoken dialogue system accessible on a smartphone. This system allows prescribers to record their prescriptions verbally, a form of interaction closer to their usual practice. The system extracts the formal representation of the prescription ready to be checked by the prescribing software and uses the dialogue to request mandatory information, correct errors or warn of particular situations. Since, to the best of our knowledge, there is no existing voice-based prescription dialogue system, we present the system developed in a low-resource environment, focusing on dialogue modeling, semantic extraction and data augmentation. The system was evaluated in the wild with 55 participants. This evaluation showed that our system has an average prescription time of 66.15 seconds for physicians and 35.64 seconds for other experts, and a task success rate of 76\% for physicians and 72\% for other experts. All evaluation data were recorded and annotated to form PxCorpus, the first spoken drug prescription corpus that has been made fully available to the community (\url{https://doi.org/10.5281/zenodo.6524162}).
Generative Pre-Training of Time-Series Data for Unsupervised Fault Detection in Semiconductor Manufacturing
Sep 20, 2023This paper introduces TRACE-GPT, which stands for Time-seRies Anomaly-detection with Convolutional Embedding and Generative Pre-trained Transformers. TRACE-GPT is designed to pre-train univariate time-series sensor data and detect faults on unlabeled datasets in semiconductor manufacturing. In semiconductor industry, classifying abnormal time-series sensor data from normal data is important because it is directly related to wafer defect. However, small, unlabeled, and even mixed training data without enough anomalies make classification tasks difficult. In this research, we capture features of time-series data with temporal convolutional embedding and Generative Pre-trained Transformer (GPT) to classify abnormal sequences from normal sequences using cross entropy loss. We prove that our model shows better performance than previous unsupervised models with both an open dataset, the University of California Riverside (UCR) time-series classification archive, and the process log of our Chemical Vapor Deposition (CVD) equipment. Our model has the highest F1 score at Equal Error Rate (EER) across all datasets and is only 0.026 below the supervised state-of-the-art baseline on the open dataset.
Towards a Prediction of Machine Learning Training Time to Support Continuous Learning Systems Development
Sep 20, 2023The problem of predicting the training time of machine learning (ML) models has become extremely relevant in the scientific community. Being able to predict a priori the training time of an ML model would enable the automatic selection of the best model both in terms of energy efficiency and in terms of performance in the context of, for instance, MLOps architectures. In this paper, we present the work we are conducting towards this direction. In particular, we present an extensive empirical study of the Full Parameter Time Complexity (FPTC) approach by Zheng et al., which is, to the best of our knowledge, the only approach formalizing the training time of ML models as a function of both dataset's and model's parameters. We study the formulations proposed for the Logistic Regression and Random Forest classifiers, and we highlight the main strengths and weaknesses of the approach. Finally, we observe how, from the conducted study, the prediction of training time is strictly related to the context (i.e., the involved dataset) and how the FPTC approach is not generalizable.