 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Image Patch-Matching with Graph-Based Learning in Street Scenes
Nov 08, 2023
Matching landmark patches from a real-time image captured by an on-vehicle camera with landmark patches in an image database plays an important role in various computer perception tasks for autonomous driving. Current methods focus on local matching for regions of interest and do not take into account spatial neighborhood relationships among the image patches, which typically correspond to objects in the environment. In this paper, we construct a spatial graph with the graph vertices corresponding to patches and edges capturing the spatial neighborhood information. We propose a joint feature and metric learning model with graph-based learning. We provide a theoretical basis for the graph-based loss by showing that the information distance between the distributions conditioned on matched and unmatched pairs is maximized under our framework. We evaluate our model using several street-scene datasets and demonstrate that our approach achieves state-of-the-art matching results.
Data-driven rules for multidimensional reflection problems
Nov 11, 2023Over the recent past data-driven algorithms for solving stochastic optimal control problems in face of model uncertainty have become an increasingly active area of research. However, for singular controls and underlying diffusion dynamics the analysis has so far been restricted to the scalar case. In this paper we fill this gap by studying a multivariate singular control problem for reversible diffusions with controls of reflection type. Our contributions are threefold. We first explicitly determine the long-run average costs as a domain-dependent functional, showing that the control problem can be equivalently characterized as a shape optimization problem. For given diffusion dynamics, assuming the optimal domain to be strongly star-shaped, we then propose a gradient descent algorithm based on polytope approximations to numerically determine a cost-minimizing domain. Finally, we investigate data-driven solutions when the diffusion dynamics are unknown to the controller. Using techniques from nonparametric statistics for stochastic processes, we construct an optimal domain estimator, whose static regret is bounded by the minimax optimal estimation rate of the unreflected process' invariant density. In the most challenging situation, when the dynamics must be learned simultaneously to controlling the process, we develop an episodic learning algorithm to overcome the emerging exploration-exploitation dilemma and show that given the static regret as a baseline, the loss in its sublinear regret per time unit is of natural order compared to the one-dimensional case.
Unsupervised and semi-supervised co-salient object detection via segmentation frequency statistics
Nov 11, 2023In this paper, we address the detection of co-occurring salient objects (CoSOD) in an image group using frequency statistics in an unsupervised manner, which further enable us to develop a semi-supervised method. While previous works have mostly focused on fully supervised CoSOD, less attention has been allocated to detecting co-salient objects when limited segmentation annotations are available for training. Our simple yet effective unsupervised method US-CoSOD combines the object co-occurrence frequency statistics of unsupervised single-image semantic segmentations with salient foreground detections using self-supervised feature learning. For the first time, we show that a large unlabeled dataset e.g. ImageNet-1k can be effectively leveraged to significantly improve unsupervised CoSOD performance. Our unsupervised model is a great pre-training initialization for our semi-supervised model SS-CoSOD, especially when very limited labeled data is available for training. To avoid propagating erroneous signals from predictions on unlabeled data, we propose a confidence estimation module to guide our semi-supervised training. Extensive experiments on three CoSOD benchmark datasets show that both of our unsupervised and semi-supervised models outperform the corresponding state-of-the-art models by a significant margin (e.g., on the Cosal2015 dataset, our US-CoSOD model has an 8.8% F-measure gain over a SOTA unsupervised co-segmentation model and our SS-CoSOD model has an 11.81% F-measure gain over a SOTA semi-supervised CoSOD model).
Rethinking Benchmark and Contamination for Language Models with Rephrased Samples
Nov 11, 2023Large language models are increasingly trained on all the data ever produced by humans. Many have raised concerns about the trustworthiness of public benchmarks due to potential contamination in pre-training or fine-tuning datasets. While most data decontamination efforts apply string matching (e.g., n-gram overlap) to remove benchmark data, we show that these methods are insufficient, and simple variations of test data (e.g., paraphrasing, translation) can easily bypass these decontamination measures. Furthermore, we demonstrate that if such variation of test data is not eliminated, a 13B model can easily overfit a test benchmark and achieve drastically high performance, on par with GPT-4. We validate such observations in widely used benchmarks such as MMLU, GSK8k, and HumanEval. To address this growing risk, we propose a stronger LLM-based decontamination method and apply it to widely used pre-training and fine-tuning datasets, revealing significant previously unknown test overlap. For example, in pre-training sets such as RedPajama-Data-1T and StarCoder-Data, we identified that 8-18\% of the HumanEval benchmark overlaps. Interestingly, we also find such contamination in synthetic dataset generated by GPT-3.5/4, suggesting a potential risk of unintentional contamination. We urge the community to adopt stronger decontamination approaches when using public benchmarks. Moreover, we call for the community to actively develop fresh one-time exams to evaluate models accurately. Our decontamination tool is publicly available at https://github.com/lm-sys/llm-decontaminator.
Spoken Dialogue System for Medical Prescription Acquisition on Smartphone: Development, Corpus and Evaluation
Nov 06, 2023Hospital information systems (HIS) have become an essential part of healthcare institutions and now incorporate prescribing support software. Prescription support software allows for structured information capture, which improves the safety, appropriateness and efficiency of prescriptions and reduces the number of adverse drug events (ADEs). However, such a system increases the amount of time physicians spend at a computer entering information instead of providing medical care. In addition, any new visiting clinician must learn to manage complex interfaces since each HIS has its own interfaces. In this paper, we present a natural language interface for e-prescribing software in the form of a spoken dialogue system accessible on a smartphone. This system allows prescribers to record their prescriptions verbally, a form of interaction closer to their usual practice. The system extracts the formal representation of the prescription ready to be checked by the prescribing software and uses the dialogue to request mandatory information, correct errors or warn of particular situations. Since, to the best of our knowledge, there is no existing voice-based prescription dialogue system, we present the system developed in a low-resource environment, focusing on dialogue modeling, semantic extraction and data augmentation. The system was evaluated in the wild with 55 participants. This evaluation showed that our system has an average prescription time of 66.15 seconds for physicians and 35.64 seconds for other experts, and a task success rate of 76\% for physicians and 72\% for other experts. All evaluation data were recorded and annotated to form PxCorpus, the first spoken drug prescription corpus that has been made fully available to the community (\url{https://doi.org/10.5281/zenodo.6524162}).
Universal Sharpness Dynamics in Neural Network Training: Fixed Point Analysis, Edge of Stability, and Route to Chaos
Nov 03, 2023In gradient descent dynamics of neural networks, the top eigenvalue of the Hessian of the loss (sharpness) displays a variety of robust phenomena throughout training. This includes early time regimes where the sharpness may decrease during early periods of training (sharpness reduction), and later time behavior such as progressive sharpening and edge of stability. We demonstrate that a simple $2$-layer linear network (UV model) trained on a single training example exhibits all of the essential sharpness phenomenology observed in real-world scenarios. By analyzing the structure of dynamical fixed points in function space and the vector field of function updates, we uncover the underlying mechanisms behind these sharpness trends. Our analysis reveals (i) the mechanism behind early sharpness reduction and progressive sharpening, (ii) the required conditions for edge of stability, and (iii) a period-doubling route to chaos on the edge of stability manifold as learning rate is increased. Finally, we demonstrate that various predictions from this simplified model generalize to real-world scenarios and discuss its limitations.
EXIM: A Hybrid Explicit-Implicit Representation for Text-Guided 3D Shape Generation
Nov 03, 2023
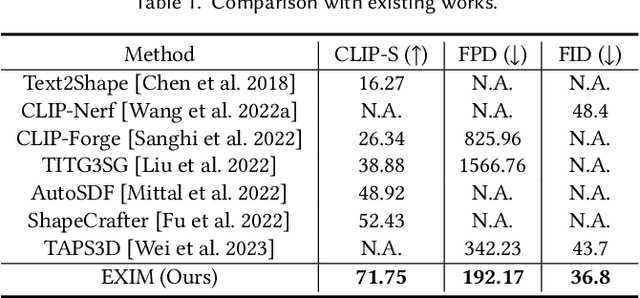
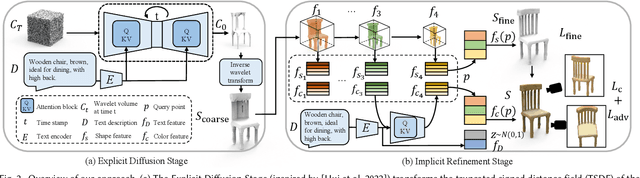
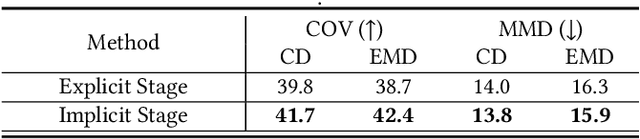
This paper presents a new text-guided technique for generating 3D shapes. The technique leverages a hybrid 3D shape representation, namely EXIM, combining the strengths of explicit and implicit representations. Specifically, the explicit stage controls the topology of the generated 3D shapes and enables local modifications, whereas the implicit stage refines the shape and paints it with plausible colors. Also, the hybrid approach separates the shape and color and generates color conditioned on shape to ensure shape-color consistency. Unlike the existing state-of-the-art methods, we achieve high-fidelity shape generation from natural-language descriptions without the need for time-consuming per-shape optimization or reliance on human-annotated texts during training or test-time optimization. Further, we demonstrate the applicability of our approach to generate indoor scenes with consistent styles using text-induced 3D shapes. Through extensive experiments, we demonstrate the compelling quality of our results and the high coherency of our generated shapes with the input texts, surpassing the performance of existing methods by a significant margin. Codes and models are released at https://github.com/liuzhengzhe/EXIM.
Testing LLMs on Code Generation with Varying Levels of Prompt Specificity
Nov 10, 2023Large language models (LLMs) have demonstrated unparalleled prowess in mimicking human-like text generation and processing. Among the myriad of applications that benefit from LLMs, automated code generation is increasingly promising. The potential to transform natural language prompts into executable code promises a major shift in software development practices and paves the way for significant reductions in manual coding efforts and the likelihood of human-induced errors. This paper reports the results of a study that evaluates the performance of various LLMs, such as Bard, ChatGPT-3.5, ChatGPT-4, and Claude-2, in generating Python for coding problems. We focus on how levels of prompt specificity impact the accuracy, time efficiency, and space efficiency of the generated code. A benchmark of 104 coding problems, each with four types of prompts with varying degrees of tests and specificity, was employed to examine these aspects comprehensively. Our results indicate significant variations in performance across different LLMs and prompt types, and its key contribution is to reveal the ideal prompting strategy for creating accurate Python functions. This study lays the groundwork for further research in LLM capabilities and suggests practical implications for utilizing LLMs in automated code generation tasks and test-driven development.
MonoProb: Self-Supervised Monocular Depth Estimation with Interpretable Uncertainty
Nov 10, 2023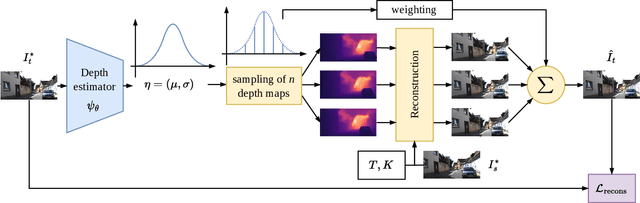
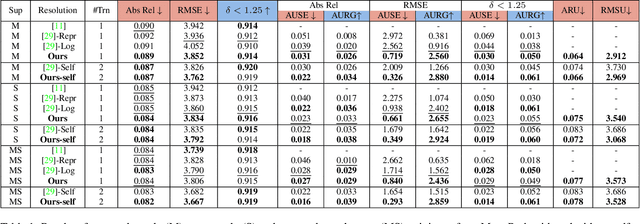


Self-supervised monocular depth estimation methods aim to be used in critical applications such as autonomous vehicles for environment analysis. To circumvent the potential imperfections of these approaches, a quantification of the prediction confidence is crucial to guide decision-making systems that rely on depth estimation. In this paper, we propose MonoProb, a new unsupervised monocular depth estimation method that returns an interpretable uncertainty, which means that the uncertainty reflects the expected error of the network in its depth predictions. We rethink the stereo or the structure-from-motion paradigms used to train unsupervised monocular depth models as a probabilistic problem. Within a single forward pass inference, this model provides a depth prediction and a measure of its confidence, without increasing the inference time. We then improve the performance on depth and uncertainty with a novel self-distillation loss for which a student is supervised by a pseudo ground truth that is a probability distribution on depth output by a teacher. To quantify the performance of our models we design new metrics that, unlike traditional ones, measure the absolute performance of uncertainty predictions. Our experiments highlight enhancements achieved by our method on standard depth and uncertainty metrics as well as on our tailored metrics. https://github.com/CEA-LIST/MonoProb
U3DS$^3$: Unsupervised 3D Semantic Scene Segmentation
Nov 10, 2023Contemporary point cloud segmentation approaches largely rely on richly annotated 3D training data. However, it is both time-consuming and challenging to obtain consistently accurate annotations for such 3D scene data. Moreover, there is still a lack of investigation into fully unsupervised scene segmentation for point clouds, especially for holistic 3D scenes. This paper presents U3DS$^3$, as a step towards completely unsupervised point cloud segmentation for any holistic 3D scenes. To achieve this, U3DS$^3$ leverages a generalized unsupervised segmentation method for both object and background across both indoor and outdoor static 3D point clouds with no requirement for model pre-training, by leveraging only the inherent information of the point cloud to achieve full 3D scene segmentation. The initial step of our proposed approach involves generating superpoints based on the geometric characteristics of each scene. Subsequently, it undergoes a learning process through a spatial clustering-based methodology, followed by iterative training using pseudo-labels generated in accordance with the cluster centroids. Moreover, by leveraging the invariance and equivariance of the volumetric representations, we apply the geometric transformation on voxelized features to provide two sets of descriptors for robust representation learning. Finally, our evaluation provides state-of-the-art results on the ScanNet and SemanticKITTI, and competitive results on the S3DIS, benchmark datasets.