 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dual-Personalizing Adapter for Federated Foundation Models
Mar 28, 2024
Recently, foundation models, particularly large language models (LLMs), have demonstrated an impressive ability to adapt to various tasks by fine-tuning large amounts of instruction data. Notably, federated foundation models emerge as a privacy preservation method to fine-tune models collaboratively under federated learning (FL) settings by leveraging many distributed datasets with non-IID data. To alleviate communication and computation overhead, parameter-efficient methods are introduced for efficiency, and some research adapted personalization methods to federated foundation models for better user preferences alignment. However, a critical gap in existing research is the neglect of test-time distribution shifts in real-world applications. Therefore, to bridge this gap, we propose a new setting, termed test-time personalization, which not only concentrates on the targeted local task but also extends to other tasks that exhibit test-time distribution shifts. To address challenges in this new setting, we explore a simple yet effective solution to learn a comprehensive foundation model. Specifically, a dual-personalizing adapter architecture (FedDPA) is proposed, comprising a global adapter and a local adapter for addressing test-time distribution shifts and personalization, respectively. Additionally, we introduce an instance-wise dynamic weighting mechanism to optimize the balance between the global and local adapters, enhancing overall performance. The effectiveness of the proposed method has been evaluated on benchmark datasets across different NLP tasks.
Exploring the Efficacy of Group-Normalization in Deep Learning Models for Alzheimer's Disease Classification
Apr 01, 2024Batch Normalization is an important approach to advancing deep learning since it allows multiple networks to train simultaneously. A problem arises when normalizing along the batch dimension because B.N.'s error increases significantly as batch size shrinks because batch statistics estimates are inaccurate. As a result, computer vision tasks like detection, segmentation, and video, which require tiny batches based on memory consumption, aren't suitable for using Batch Normalization for larger model training and feature transfer. Here, we explore Group Normalization as an easy alternative to using Batch Normalization A Group Normalization is a channel normalization method in which each group is divided into different channels, and the corresponding mean and variance are calculated for each group. Group Normalization computations are accurate across a wide range of batch sizes and are independent of batch size. When trained using a large ImageNet database on ResNet-50, GN achieves a very low error rate of 10.6% compared to Batch Normalization. when a smaller batch size of only 2 is used. For usual batch sizes, the performance of G.N. is comparable to that of Batch Normalization, but at the same time, it outperforms other normalization techniques. Implementing Group Normalization as a direct alternative to B.N to combat the serious challenges faced by the Batch Normalization in deep learning models with comparable or improved classification accuracy. Additionally, Group Normalization can be naturally transferred from the pre-training to the fine-tuning phase. .
DASA: Delay-Adaptive Multi-Agent Stochastic Approximation
Mar 28, 2024We consider a setting in which $N$ agents aim to speedup a common Stochastic Approximation (SA) problem by acting in parallel and communicating with a central server. We assume that the up-link transmissions to the server are subject to asynchronous and potentially unbounded time-varying delays. To mitigate the effect of delays and stragglers while reaping the benefits of distributed computation, we propose \texttt{DASA}, a Delay-Adaptive algorithm for multi-agent Stochastic Approximation. We provide a finite-time analysis of \texttt{DASA} assuming that the agents' stochastic observation processes are independent Markov chains. Significantly advancing existing results, \texttt{DASA} is the first algorithm whose convergence rate depends only on the mixing time $\tau_{mix}$ and on the average delay $\tau_{avg}$ while jointly achieving an $N$-fold convergence speedup under Markovian sampling. Our work is relevant for various SA applications, including multi-agent and distributed temporal difference (TD) learning, Q-learning and stochastic optimization with correlated data.
CARL: Congestion-Aware Reinforcement Learning for Imitation-based Perturbations in Mixed Traffic Control
Mar 31, 2024Human-driven vehicles (HVs) exhibit complex and diverse behaviors. Accurately modeling such behavior is crucial for validating Robot Vehicles (RVs) in simulation and realizing the potential of mixed traffic control. However, existing approaches like parameterized models and data-driven techniques struggle to capture the full complexity and diversity. To address this, in this work, we introduce CARL, a hybrid technique combining imitation learning for close proximity car-following and probabilistic sampling for larger headways. We also propose two classes of RL-based RVs: a safety RV focused on maximizing safety and an efficiency RV focused on maximizing efficiency. Our experiments show that the safety RV increases Time-to-Collision above the critical 4 second threshold and reduces Deceleration Rate to Avoid a Crash by up to 80%, while the efficiency RV achieves improvements in throughput of up to 49%. These results demonstrate the effectiveness of CARL in enhancing both safety and efficiency in mixed traffic.
Solving the QAP by Two-Stage Graph Pointer Networks and Reinforcement Learning
Mar 31, 2024Quadratic Assignment Problem (QAP) is a practical combinatorial optimization problems that has been studied for several years. Since it is NP-hard, solving large problem instances of QAP is challenging. Although heuristics can find semi-optimal solutions, the execution time significantly increases as the problem size increases. Recently, solving combinatorial optimization problems by deep learning has been attracting attention as a faster solver than heuristics. Even with deep learning, however, solving large QAP is still challenging. In this paper, we propose the deep reinforcement learning model called the two-stage graph pointer network (GPN) for solving QAP. Two-stage GPN relies on GPN, which has been proposed for Euclidean Traveling Salesman Problem (TSP). First, we extend GPN for general TSP, and then we add new algorithms to that model for solving QAP. Our experimental results show that our two-stage GPN provides semi-optimal solutions for benchmark problem instances from TSPlib and QAPLIB.
HO-Gaussian: Hybrid Optimization of 3D Gaussian Splatting for Urban Scenes
Mar 29, 2024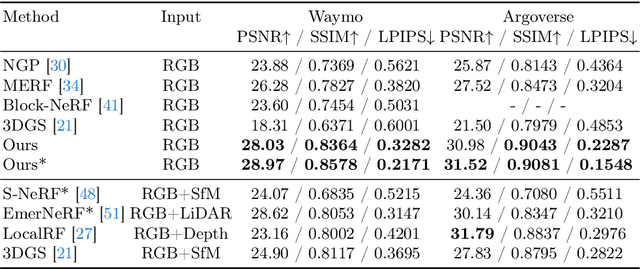
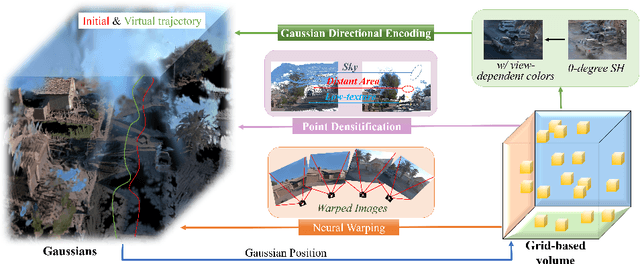
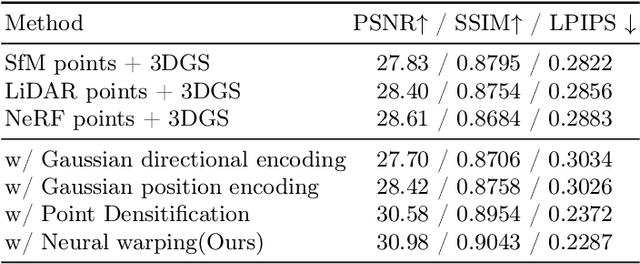
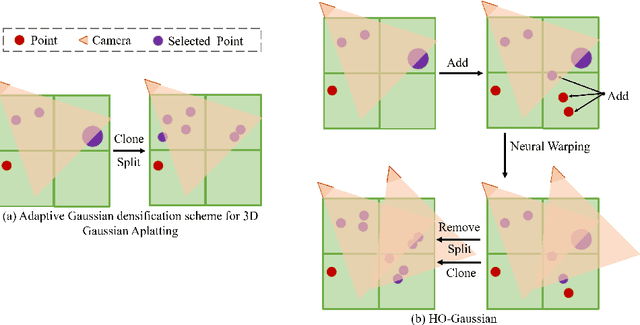
The rapid growth of 3D Gaussian Splatting (3DGS) has revolutionized neural rendering, enabling real-time production of high-quality renderings. However, the previous 3DGS-based methods have limitations in urban scenes due to reliance on initial Structure-from-Motion(SfM) points and difficulties in rendering distant, sky and low-texture areas. To overcome these challenges, we propose a hybrid optimization method named HO-Gaussian, which combines a grid-based volume with the 3DGS pipeline. HO-Gaussian eliminates the dependency on SfM point initialization, allowing for rendering of urban scenes, and incorporates the Point Densitification to enhance rendering quality in problematic regions during training. Furthermore, we introduce Gaussian Direction Encoding as an alternative for spherical harmonics in the rendering pipeline, which enables view-dependent color representation. To account for multi-camera systems, we introduce neural warping to enhance object consistency across different cameras. Experimental results on widely used autonomous driving datasets demonstrate that HO-Gaussian achieves photo-realistic rendering in real-time on multi-camera urban datasets.
Augmented Reality Warnings in Roadway Work Zones: Evaluating the Effect of Modality on Worker Reaction Times
Mar 29, 2024Given the aging highway infrastructure requiring extensive rebuilding and enhancements, and the consequent rise in the number of work zones, there is an urgent need to develop advanced safety systems to protect workers. While Augmented Reality (AR) holds significant potential for delivering warnings to workers, its integration into roadway work zones remains relatively unexplored. The primary objective of this study is to improve safety measures within roadway work zones by conducting an extensive analysis of how different combinations of multimodal AR warnings influence the reaction times of workers. This paper addresses this gap through a series of experiments that aim to replicate the distinctive conditions of roadway work zones, both in real-world and virtual reality environments. Our approach comprises three key components: an advanced AR system prototype, a VR simulation of AR functionality within the work zone environment, and the Wizard of Oz technique to synchronize user experiences across experiments. To assess reaction times, we leverage both the simple reaction time (SRT) technique and an innovative vision-based metric that utilizes real-time pose estimation. By conducting five experiments in controlled outdoor work zones and indoor VR settings, our study provides valuable information on how various multimodal AR warnings impact workers reaction times. Furthermore, our findings reveal the disparities in reaction times between VR simulations and real-world scenarios, thereby gauging VR's capability to mirror the dynamics of roadway work zones. Furthermore, our results substantiate the potential and reliability of vision-based reaction time measurements. These insights resonate well with those derived using the SRT technique, underscoring the viability of this approach for tangible real-world uses.
Chain-structured neural architecture search for financial time series forecasting
Mar 15, 2024We compare three popular neural architecture search strategies on chain-structured search spaces: Bayesian optimization, the hyperband method, and reinforcement learning in the context of financial time series forecasting.
TwinLiteNetPlus: A Stronger Model for Real-time Drivable Area and Lane Segmentation
Mar 25, 2024Semantic segmentation is crucial for autonomous driving, particularly for Drivable Area and Lane Segmentation, ensuring safety and navigation. To address the high computational costs of current state-of-the-art (SOTA) models, this paper introduces TwinLiteNetPlus (TwinLiteNet$^+$), a model adept at balancing efficiency and accuracy. TwinLiteNet$^+$ incorporates standard and depth-wise separable dilated convolutions, reducing complexity while maintaining high accuracy. It is available in four configurations, from the robust 1.94 million-parameter TwinLiteNet$^+_{\text{Large}}$ to the ultra-compact 34K-parameter TwinLiteNet$^+_{\text{Nano}}$. Notably, TwinLiteNet$^+_{\text{Large}}$ attains a 92.9\% mIoU for Drivable Area Segmentation and a 34.2\% IoU for Lane Segmentation. These results notably outperform those of current SOTA models while requiring a computational cost that is approximately 11 times lower in terms of Floating Point Operations (FLOPs) compared to the existing SOTA model. Extensively tested on various embedded devices, TwinLiteNet$^+$ demonstrates promising latency and power efficiency, underscoring its suitability for real-world autonomous vehicle applications.
Swarm Characteristics Classification Using Neural Networks
Mar 28, 2024
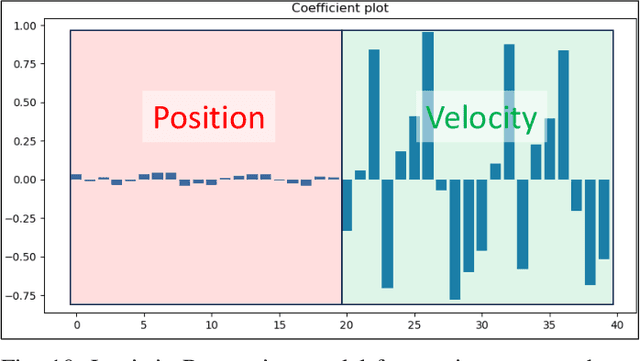
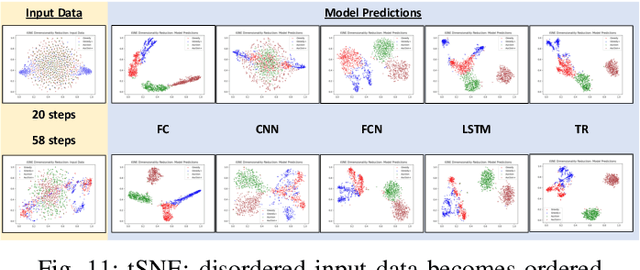
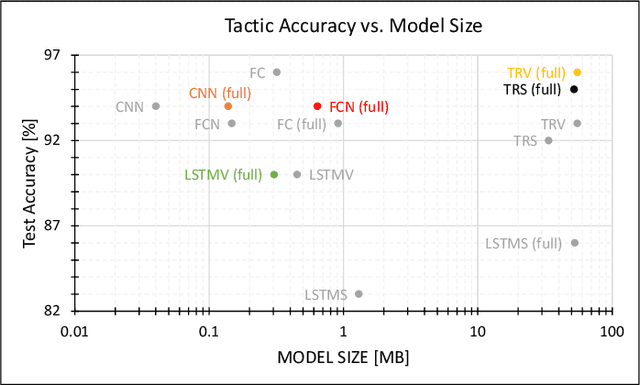
Understanding the characteristics of swarming autonomous agents is critical for defense and security applications. This article presents a study on using supervised neural network time series classification (NN TSC) to predict key attributes and tactics of swarming autonomous agents for military contexts. Specifically, NN TSC is applied to infer two binary attributes - communication and proportional navigation - which combine to define four mutually exclusive swarm tactics. We identify a gap in literature on using NNs for swarm classification and demonstrate the effectiveness of NN TSC in rapidly deducing intelligence about attacking swarms to inform counter-maneuvers. Through simulated swarm-vs-swarm engagements, we evaluate NN TSC performance in terms of observation window requirements, noise robustness, and scalability to swarm size. Key findings show NNs can predict swarm behaviors with 97% accuracy using short observation windows of 20 time steps, while also demonstrating graceful degradation down to 80% accuracy under 50% noise, as well as excellent scalability to swarm sizes from 10 to 100 agents. These capabilities are promising for real-time decision-making support in defense scenarios by rapidly inferring insights about swarm behavior.