 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Astrocytes as a mechanism for meta-plasticity and contextually-guided network function
Nov 06, 2023
Astrocytes are a highly expressed and highly enigmatic cell-type in the mammalian brain. Traditionally viewed as a mediator of basic physiological sustenance, it is increasingly recognized that astrocytes may play a more direct role in neural computation. A conceptual challenge to this idea is the fact that astrocytic activity takes a very different form than that of neurons, and in particular, occurs at orders-of-magnitude slower time-scales. In the current paper, we engage how such time-scale separation may endow astrocytes with the capability to enable learning in context-dependent settings, where fluctuations in task parameters may occur much more slowly than within-task requirements. This idea is based on the recent supposition that astrocytes, owing to their sensitivity to a host of physiological covariates, may be particularly well poised to modulate the dynamics of neural circuits in functionally salient ways. We pose a general model of neural-synaptic-astrocyte interaction and use formal analysis to characterize how astrocytic modulation may constitute a form of meta-plasticity, altering the ways in which synapses and neurons adapt as a function of time. We then embed this model in a bandit-based reinforcement learning task environment, and show how the presence of time-scale separated astrocytic modulation enables learning over multiple fluctuating contexts. Indeed, these networks learn far more reliably versus dynamically homogenous networks and conventional non-network-based bandit algorithms. Our results indicate how the presence of neural-astrocyte interaction in the brain may benefit learning over different time-scale and the conveyance of task relevant contextual information onto circuit dynamics.
BrainZ-BP: A Non-invasive Cuff-less Blood Pressure Estimation Approach Leveraging Brain Bio-impedance and Electrocardiogram
Nov 18, 2023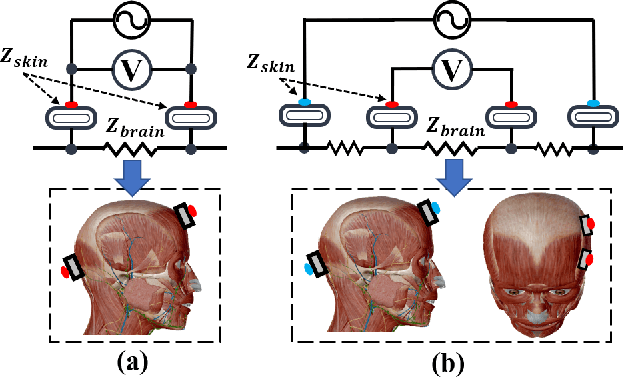
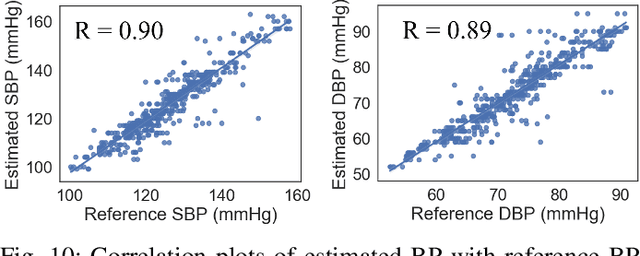
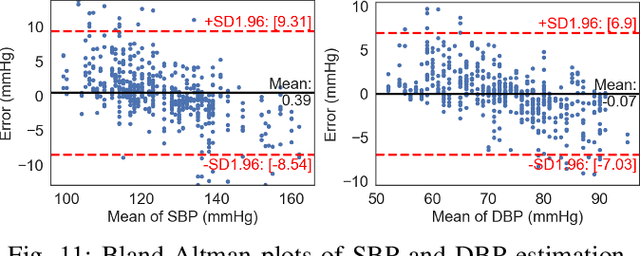
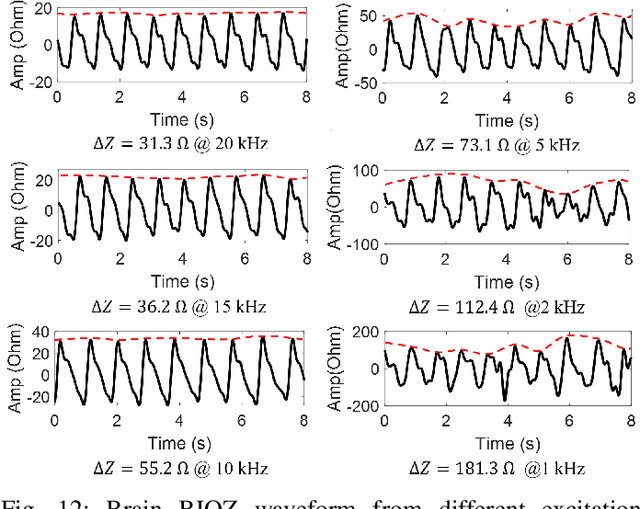
Accurate and continuous blood pressure (BP) monitoring is essential to the early prevention of cardiovascular diseases. Non-invasive and cuff-less BP estimation algorithm has gained much attention in recent years. Previous studies have demonstrated that brain bio-impedance (BIOZ) is a promising technique for non-invasive intracranial pressure (ICP) monitoring. Clinically, treatment for patients with traumatic brain injuries (TBI) requires monitoring the ICP and BP of patients simultaneously. Estimating BP by brain BIOZ directly can reduce the number of sensors attached to the patients, thus improving their comfort. To address the issues, in this study, we explore the feasibility of leveraging brain BIOZ for BP estimation and propose a novel cuff-less BP estimation approach called BrainZ-BP. Two electrodes are placed on the forehead and occipital bone of the head in the anterior-posterior direction for brain BIOZ measurement. Various features including pulse transit time and morphological features of brain BIOZ are extracted and fed into four regression models for BP estimation. Results show that the mean absolute error, root mean square error, and correlation coefficient of random forest regression model are 2.17 mmHg, 3.91 mmHg, and 0.90 for systolic pressure estimation, and are 1.71 mmHg, 3.02 mmHg, and 0.89 for diastolic pressure estimation. The presented BrainZ-BP can be applied in the brain BIOZ-based ICP monitoring scenario to monitor BP simultaneously.
Contextualizing Internet Memes Across Social Media Platforms
Nov 18, 2023Internet memes have emerged as a novel format for communication and expressing ideas on the web. Their fluidity and creative nature are reflected in their widespread use, often across platforms and occasionally for unethical or harmful purposes. While computational work has already analyzed their high-level virality over time and developed specialized classifiers for hate speech detection, there have been no efforts to date that aim to holistically track, identify, and map internet memes posted on social media. To bridge this gap, we investigate whether internet memes across social media platforms can be contextualized by using a semantic repository of knowledge, namely, a knowledge graph. We collect thousands of potential internet meme posts from two social media platforms, namely Reddit and Discord, and perform an extract-transform-load procedure to create a data lake with candidate meme posts. By using vision transformer-based similarity, we match these candidates against the memes cataloged in a recently released knowledge graph of internet memes, IMKG. We provide evidence that memes published online can be identified by mapping them to IMKG. We leverage this grounding to study the prevalence of memes on different platforms, discover popular memes, and select common meme channels and subreddits. Finally, we illustrate how the grounding can enable users to get context about memes on social media thanks to their link to the knowledge graph.
Discret2Di -- Deep Learning based Discretization for Model-based Diagnosis
Nov 06, 2023Consistency-based diagnosis is an established approach to diagnose technical applications, but suffers from significant modeling efforts, especially for dynamic multi-modal time series. Machine learning seems to be an obvious solution, which becomes less obvious when looking at details: Which notion of consistency can be used? If logical calculi are still to be used, how can dynamic time series be transferred into the discrete world? This paper presents the methodology Discret2Di for automated learning of logical expressions for consistency-based diagnosis. While these logical calculi have advantages by providing a clear notion of consistency, they have the key problem of relying on a discretization of the dynamic system. The solution presented combines machine learning from both the time series and the symbolic domain to automate the learning of logical rules for consistency-based diagnosis.
Cross-modal Generative Model for Visual-Guided Binaural Stereo Generation
Nov 13, 2023
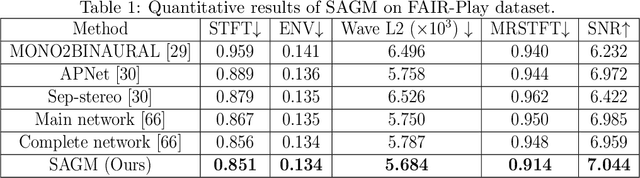
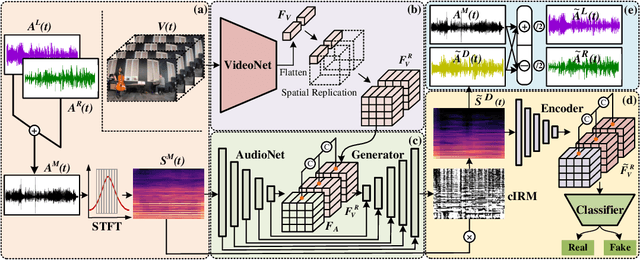
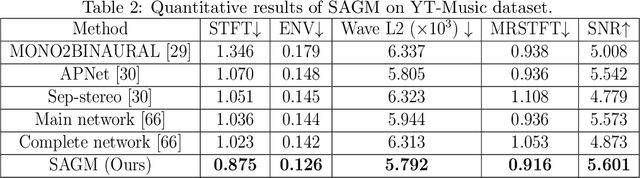
Binaural stereo audio is recorded by imitating the way the human ear receives sound, which provides people with an immersive listening experience. Existing approaches leverage autoencoders and directly exploit visual spatial information to synthesize binaural stereo, resulting in a limited representation of visual guidance. For the first time, we propose a visually guided generative adversarial approach for generating binaural stereo audio from mono audio. Specifically, we develop a Stereo Audio Generation Model (SAGM), which utilizes shared spatio-temporal visual information to guide the generator and the discriminator to work separately. The shared visual information is updated alternately in the generative adversarial stage, allowing the generator and discriminator to deliver their respective guided knowledge while visually sharing. The proposed method learns bidirectional complementary visual information, which facilitates the expression of visual guidance in generation. In addition, spatial perception is a crucial attribute of binaural stereo audio, and thus the evaluation of stereo spatial perception is essential. However, previous metrics failed to measure the spatial perception of audio. To this end, a metric to measure the spatial perception of audio is proposed for the first time. The proposed metric is capable of measuring the magnitude and direction of spatial perception in the temporal dimension. Further, considering its function, it is feasible to utilize it instead of demanding user studies to some extent. The proposed method achieves state-of-the-art performance on 2 datasets and 5 evaluation metrics. Qualitative experiments and user studies demonstrate that the method generates space-realistic stereo audio.
Self-Supervised Disentanglement by Leveraging Structure in Data Augmentations
Nov 15, 2023Self-supervised representation learning often uses data augmentations to induce some invariance to "style" attributes of the data. However, with downstream tasks generally unknown at training time, it is difficult to deduce a priori which attributes of the data are indeed "style" and can be safely discarded. To address this, we introduce a more principled approach that seeks to disentangle style features rather than discard them. The key idea is to add multiple style embedding spaces where: (i) each is invariant to all-but-one augmentation; and (ii) joint entropy is maximized. We formalize our structured data-augmentation procedure from a causal latent-variable-model perspective, and prove identifiability of both content and (multiple blocks of) style variables. We empirically demonstrate the benefits of our approach on synthetic datasets and then present promising but limited results on ImageNet.
Towards Verifiable Text Generation with Symbolic References
Nov 15, 2023Large language models (LLMs) have demonstrated an impressive ability to synthesize plausible and fluent text. However they remain vulnerable to hallucinations, and thus their outputs generally require manual human verification for high-stakes applications, which can be time-consuming and difficult. This paper proposes symbolically grounded generation (SymGen) as a simple approach for enabling easier validation of an LLM's output. SymGen prompts an LLM to interleave its regular output text with explicit symbolic references to fields present in some conditioning data (e.g., a table in JSON format). The references can be used to display the provenance of different spans of text in the generation, reducing the effort required for manual verification. Across data-to-text and question answering experiments, we find that LLMs are able to directly output text that makes use of symbolic references while maintaining fluency and accuracy.
I Was Blind but Now I See: Implementing Vision-Enabled Dialogue in Social Robots
Nov 15, 2023In the rapidly evolving landscape of human-computer interaction, the integration of vision capabilities into conversational agents stands as a crucial advancement. This paper presents an initial implementation of a dialogue manager that leverages the latest progress in Large Language Models (e.g., GPT-4, IDEFICS) to enhance the traditional text-based prompts with real-time visual input. LLMs are used to interpret both textual prompts and visual stimuli, creating a more contextually aware conversational agent. The system's prompt engineering, incorporating dialogue with summarisation of the images, ensures a balance between context preservation and computational efficiency. Six interactions with a Furhat robot powered by this system are reported, illustrating and discussing the results obtained. By implementing this vision-enabled dialogue system, the paper envisions a future where conversational agents seamlessly blend textual and visual modalities, enabling richer, more context-aware dialogues.
UAV Formation Optimization for Communication-assisted InSAR Sensing
Nov 12, 2023Interferometric synthetic aperture radar (InSAR) is an increasingly important remote sensing technique that enables three-dimensional (3D) sensing applications such as the generation of accurate digital elevation models (DEMs). In this paper, we investigate the joint formation and communication resource allocation optimization for a system comprising two unmanned aerial vehicles (UAVs) to perform InSAR sensing and to transfer the acquired data to the ground. To this end, we adopt as sensing performance metrics the interferometric coherence, i.e., the local correlation between the two co-registered UAV radar images, and the height of ambiguity (HoA), which together are a measure for the accuracy with which the InSAR system can estimate the height of ground objects. In addition, an analytical expression for the coverage of the considered InSAR sensing system is derived. Our objective is to maximize the InSAR coverage while satisfying all relevant InSAR-specific sensing and communication performance metrics. To tackle the non-convexity of the formulated optimization problem, we employ alternating optimization (AO) techniques combined with successive convex approximation (SCA). Our simulation results reveal that the resulting resource allocation algorithm outperforms two benchmark schemes in terms of InSAR coverage while satisfying all sensing and real-time communication requirements. Furthermore, we highlight the importance of efficient communication resource allocation in facilitating real-time sensing and unveil the trade-off between InSAR height estimation accuracy and coverage.
Determining the Optimal Number of Clusters for Time Series Datasets with Symbolic Pattern Forest
Oct 01, 2023Clustering algorithms are among the most widely used data mining methods due to their exploratory power and being an initial preprocessing step that paves the way for other techniques. But the problem of calculating the optimal number of clusters (say k) is one of the significant challenges for such methods. The most widely used clustering algorithms like k-means and k-shape in time series data mining also need the ground truth for the number of clusters that need to be generated. In this work, we extended the Symbolic Pattern Forest algorithm, another time series clustering algorithm, to determine the optimal number of clusters for the time series datasets. We used SPF to generate the clusters from the datasets and chose the optimal number of clusters based on the Silhouette Coefficient, a metric used to calculate the goodness of a clustering technique. Silhouette was calculated on both the bag of word vectors and the tf-idf vectors generated from the SAX words of each time series. We tested our approach on the UCR archive datasets, and our experimental results so far showed significant improvement over the baseline.