 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time Multi-modal Object Detection and Tracking on Edge for Regulatory Compliance Monitoring
Oct 05, 2023
Regulatory compliance auditing across diverse industrial domains requires heightened quality assurance and traceability. Present manual and intermittent approaches to such auditing yield significant challenges, potentially leading to oversights in the monitoring process. To address these issues, we introduce a real-time, multi-modal sensing system employing 3D time-of-flight and RGB cameras, coupled with unsupervised learning techniques on edge AI devices. This enables continuous object tracking thereby enhancing efficiency in record-keeping and minimizing manual interventions. While we validate the system in a knife sanitization context within agrifood facilities, emphasizing its prowess against occlusion and low-light issues with RGB cameras, its potential spans various industrial monitoring settings.
Utilizing dataset affinity prediction in object detection to assess training data
Nov 16, 2023Data pooling offers various advantages, such as increasing the sample size, improving generalization, reducing sampling bias, and addressing data sparsity and quality, but it is not straightforward and may even be counterproductive. Assessing the effectiveness of pooling datasets in a principled manner is challenging due to the difficulty in estimating the overall information content of individual datasets. Towards this end, we propose incorporating a data source prediction module into standard object detection pipelines. The module runs with minimal overhead during inference time, providing additional information about the data source assigned to individual detections. We show the benefits of the so-called dataset affinity score by automatically selecting samples from a heterogeneous pool of vehicle datasets. The results show that object detectors can be trained on a significantly sparser set of training samples without losing detection accuracy.
Guaranteeing Control Requirements via Reward Shaping in Reinforcement Learning
Nov 16, 2023In addressing control problems such as regulation and tracking through reinforcement learning, it is often required to guarantee that the acquired policy meets essential performance and stability criteria such as a desired settling time and steady-state error prior to deployment. Motivated by this necessity, we present a set of results and a systematic reward shaping procedure that (i) ensures the optimal policy generates trajectories that align with specified control requirements and (ii) allows to assess whether any given policy satisfies them. We validate our approach through comprehensive numerical experiments conducted in two representative environments from OpenAI Gym: the Inverted Pendulum swing-up problem and the Lunar Lander. Utilizing both tabular and deep reinforcement learning methods, our experiments consistently affirm the efficacy of our proposed framework, highlighting its effectiveness in ensuring policy adherence to the prescribed control requirements.
Multi-View Spectrogram Transformer for Respiratory Sound Classification
Nov 16, 2023Deep neural networks have been applied to audio spectrograms for respiratory sound classification. Existing models often treat the spectrogram as a synthetic image while overlooking its physical characteristics. In this paper, a Multi-View Spectrogram Transformer (MVST) is proposed to embed different views of time-frequency characteristics into the vision transformer. Specifically, the proposed MVST splits the mel-spectrogram into different sized patches, representing the multi-view acoustic elements of a respiratory sound. These patches and positional embeddings are then fed into transformer encoders to extract the attentional information among patches through a self-attention mechanism. Finally, a gated fusion scheme is designed to automatically weigh the multi-view features to highlight the best one in a specific scenario. Experimental results on the ICBHI dataset demonstrate that the proposed MVST significantly outperforms state-of-the-art methods for classifying respiratory sounds.
One Size Does Not Fit All: Customizing Open-Domain Procedures
Nov 16, 2023How-to procedures, such as how to plant a garden, are ubiquitous. But one size does not fit all - humans often need to customize these procedural plans according to their specific needs, e.g., planting a garden without pesticides. While LLMs can fluently generate generic procedures, we present the first study on how well LLMs can customize open-domain procedures. We introduce CustomPlans, a probe dataset of customization hints that encodes diverse user needs for open-domain How-to procedures. Using LLMs as CustomizationAgent and ExecutionAgent in different settings, we establish their abilities to perform open-domain procedure customization. Human evaluation shows that using these agents in a Sequential setting is the best, but they are good enough only ~51% of the time. Error analysis shows that LLMs do not sufficiently address user customization needs in their generated procedures.
Test-Time Training for Speech
Sep 19, 2023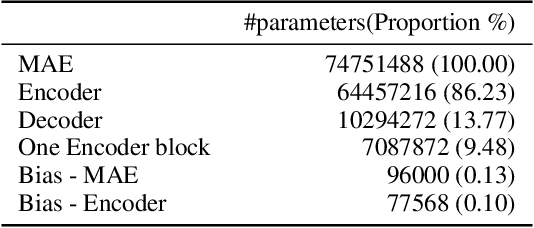

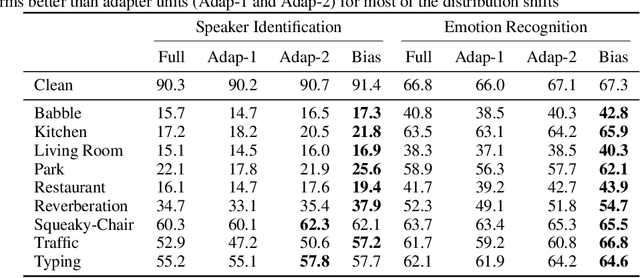
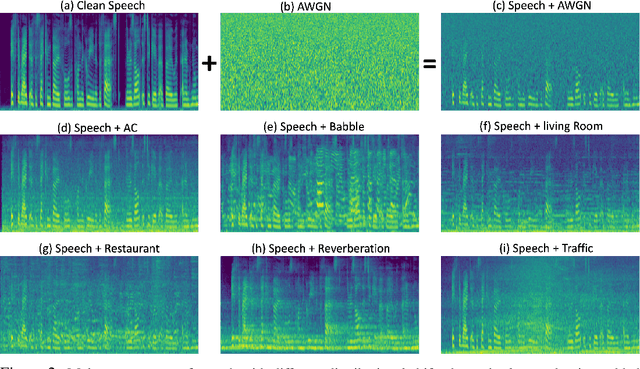
In this paper, we study the application of Test-Time Training (TTT) as a solution to handling distribution shifts in speech applications. In particular, we introduce distribution-shifts to the test datasets of standard speech-classification tasks -- for example, speaker-identification and emotion-detection -- and explore how Test-Time Training (TTT) can help adjust to the distribution-shift. In our experiments that include distribution shifts due to background noise and natural variations in speech such as gender and age, we identify some key-challenges with TTT including sensitivity to optimization hyperparameters (e.g., number of optimization steps and subset of parameters chosen for TTT) and scalability (e.g., as each example gets its own set of parameters, TTT is not scalable). Finally, we propose using BitFit -- a parameter-efficient fine-tuning algorithm proposed for text applications that only considers the bias parameters for fine-tuning -- as a solution to the aforementioned challenges and demonstrate that it is consistently more stable than fine-tuning all the parameters of the model.
Autoregressive Language Models For Estimating the Entropy of Epic EHR Audit Logs
Nov 14, 2023EHR audit logs are a highly granular stream of events that capture clinician activities, and is a significant area of interest for research in characterizing clinician workflow on the electronic health record (EHR). Existing techniques to measure the complexity of workflow through EHR audit logs (audit logs) involve time- or frequency-based cross-sectional aggregations that are unable to capture the full complexity of a EHR session. We briefly evaluate the usage of transformer-based tabular language model (tabular LM) in measuring the entropy or disorderedness of action sequences within workflow and release the evaluated models publicly.
RETRO: Reactive Trajectory Optimization for Real-Time Robot Motion Planning in Dynamic Environments
Oct 03, 2023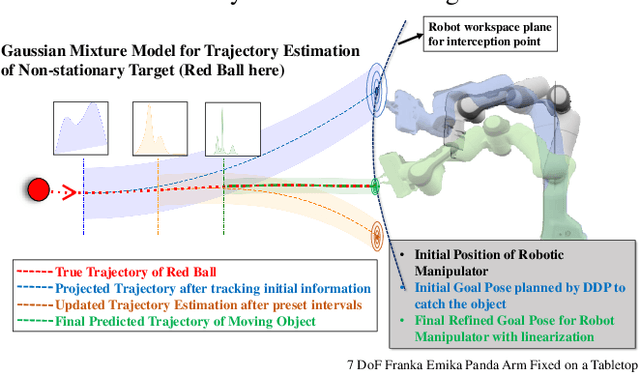
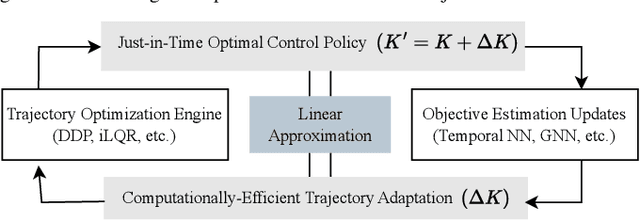
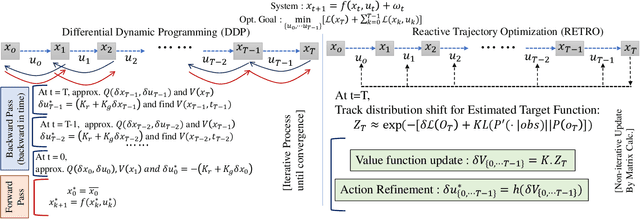
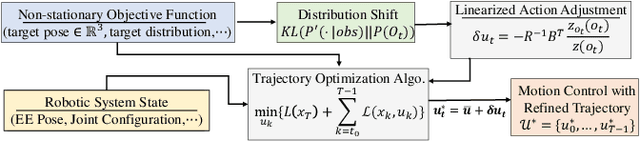
Reactive trajectory optimization for robotics presents formidable challenges, demanding the rapid generation of purposeful robot motion in complex and swiftly changing dynamic environments. While much existing research predominantly addresses robotic motion planning with predefined objectives, emerging problems in robotic trajectory optimization frequently involve dynamically evolving objectives and stochastic motion dynamics. However, effectively addressing such reactive trajectory optimization challenges for robot manipulators proves difficult due to inefficient, high-dimensional trajectory representations and a lack of consideration for time optimization. In response, we introduce a novel trajectory optimization framework called RETRO. RETRO employs adaptive optimization techniques that span both spatial and temporal dimensions. As a result, it achieves a remarkable computing complexity of $O(T^{2.4}) + O(Tn^{2})$, a significant improvement over the traditional application of DDP, which leads to a complexity of $O(n^{4})$ when reasonable time step sizes are used. To evaluate RETRO's performance in terms of error, we conducted a comprehensive analysis of its regret bounds, comparing it to an Oracle value function obtained through an Oracle trajectory optimization algorithm. Our analytical findings demonstrate that RETRO's total regret can be upper-bounded by a function of the chosen time step size. Moreover, our approach delivers smoothly optimized robot trajectories within the joint space, offering flexibility and adaptability for various tasks. It can seamlessly integrate task-specific requirements such as collision avoidance while maintaining real-time control rates. We validate the effectiveness of our framework through extensive simulations and real-world robot experiments in closed-loop manipulation scenarios.
Exploiting Inductive Biases in Video Modeling through Neural CDEs
Nov 08, 2023
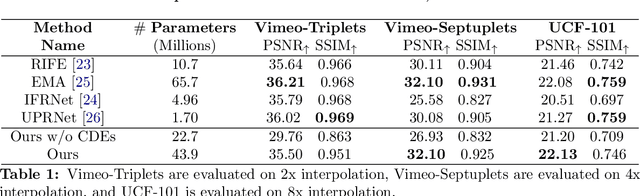

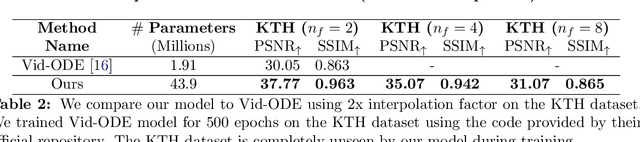
We introduce a novel approach to video modeling that leverages controlled differential equations (CDEs) to address key challenges in video tasks, notably video interpolation and mask propagation. We apply CDEs at varying resolutions leading to a continuous-time U-Net architecture. Unlike traditional methods, our approach does not require explicit optical flow learning, and instead makes use of the inherent continuous-time features of CDEs to produce a highly expressive video model. We demonstrate competitive performance against state-of-the-art models for video interpolation and mask propagation tasks.
Towards a Post-Market Monitoring Framework for Machine Learning-based Medical Devices: A case study
Nov 20, 2023After a machine learning (ML)-based system is deployed in clinical practice, performance monitoring is important to ensure the safety and effectiveness of the algorithm over time. The goal of this work is to highlight the complexity of designing a monitoring strategy and the need for a systematic framework that compares the multitude of monitoring options. One of the main decisions is choosing between using real-world (observational) versus interventional data. Although the former is the most convenient source of monitoring data, it exhibits well-known biases, such as confounding, selection, and missingness. In fact, when the ML algorithm interacts with its environment, the algorithm itself may be a primary source of bias. On the other hand, a carefully designed interventional study that randomizes individuals can explicitly eliminate such biases, but the ethics, feasibility, and cost of such an approach must be carefully considered. Beyond the decision of the data source, monitoring strategies vary in the performance criteria they track, the interpretability of the test statistics, the strength of their assumptions, and their speed at detecting performance decay. As a first step towards developing a framework that compares the various monitoring options, we consider a case study of an ML-based risk prediction algorithm for postoperative nausea and vomiting (PONV). Bringing together tools from causal inference and statistical process control, we walk through the basic steps of defining candidate monitoring criteria, describing potential sources of bias and the causal model, and specifying and comparing candidate monitoring procedures. We hypothesize that these steps can be applied more generally, as causal inference can address other sources of biases as well.