 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Comparison of model selection techniques for seafloor scattering statistics
Nov 14, 2023
In quantitative analysis of seafloor imagery, it is common to model the collection of individual pixel intensities scattered by the seafloor as a random variable with a given statistical distribution. There is a considerable literature on statistical models for seafloor scattering, mostly focused on areas with statistically homogeneous properties (i.e. exhibiting spatial stationarity). For more complex seafloors, the pixel intensity distribution is more appropriately modeled using a mixture of simple distributions. For very complex seafloors, fitting 3 or more mixture components makes physical sense, but the statistical model becomes much more complex in these cases. Therefore, picking the number of components of the mixture model is a decision that must be made, using a priori information, or using a data driven approach. However, this information is time consuming to collect, and depends on the skill and experience of the human. Therefore, a data-driven approach is advantageous to use, and is explored in this work. Criteria for choosing a model always need to balance the trade-off for the best fit for the data on the one hand and the model complexity on the other hand. In this work, we compare several statistical model selection criteria, e.g., the Bayesian information criterion. Examples are given for SAS data collected by an autonomous underwater vehicle in a rocky environment off the coast of Bergen, Norway using data from the HISAS-1032 synthetic aperture sonar system.
Identifying Light-curve Signals with a Deep Learning Based Object Detection Algorithm. II. A General Light Curve Classification Framework
Nov 14, 2023Vast amounts of astronomical photometric data are generated from various projects, requiring significant efforts to identify variable stars and other object classes. In light of this, a general, widely applicable classification framework would simplify the task of designing custom classifiers. We present a novel deep learning framework for classifying light curves using a weakly supervised object detection model. Our framework identifies the optimal windows for both light curves and power spectra automatically, and zooms in on their corresponding data. This allows for automatic feature extraction from both time and frequency domains, enabling our model to handle data across different scales and sampling intervals. We train our model on datasets obtained from both space-based and ground-based multi-band observations of variable stars and transients. We achieve an accuracy of 87% for combined variables and transient events, which is comparable to the performance of previous feature-based models. Our trained model can be utilized directly to other missions, such as ASAS-SN, without requiring any retraining or fine-tuning. To address known issues with miscalibrated predictive probabilities, we apply conformal prediction to generate robust predictive sets that guarantee true label coverage with a given probability. Additionally, we incorporate various anomaly detection algorithms to empower our model with the ability to identify out-of-distribution objects. Our framework is implemented in the Deep-LC toolkit, which is an open-source Python package hosted on Github and PyPI.
Large Language Model-Driven Classroom Flipping: Empowering Student-Centric Peer Questioning with Flipped Interaction
Nov 14, 2023Reciprocal questioning is essential for effective teaching and learning, fostering active engagement and deeper understanding through collaborative interactions, especially in large classrooms. Can large language model (LLM), such as OpenAI's GPT (Generative Pre-trained Transformer) series, assist in this? This paper investigates a pedagogical approach of classroom flipping based on flipped interaction in LLMs. Flipped interaction involves using language models to prioritize generating questions instead of answers to prompts. We demonstrate how traditional classroom flipping techniques, including Peer Instruction and Just-in-Time Teaching (JiTT), can be enhanced through flipped interaction techniques, creating student-centric questions for hybrid teaching. In particular, we propose a workflow to integrate prompt engineering with clicker and JiTT quizzes by a poll-prompt-quiz routine and a quiz-prompt-discuss routine to empower students to self-regulate their learning capacity and enable teachers to swiftly personalize training pathways. We develop an LLM-driven chatbot software that digitizes various elements of classroom flipping and facilitates the assessment of students using these routines to deliver peer-generated questions. We have applied our LLM-driven chatbot software for teaching both undergraduate and graduate students from 2020 to 2022, effectively useful for bridging the gap between teachers and students in remote teaching during the COVID-19 pandemic years. In particular, LLM-driven classroom flipping can be particularly beneficial in large class settings to optimize teaching pace and enable engaging classroom experiences.
MetisFL: An Embarrassingly Parallelized Controller for Scalable & Efficient Federated Learning Workflows
Nov 13, 2023
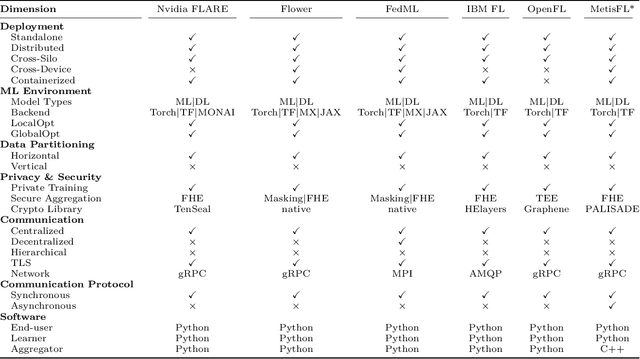
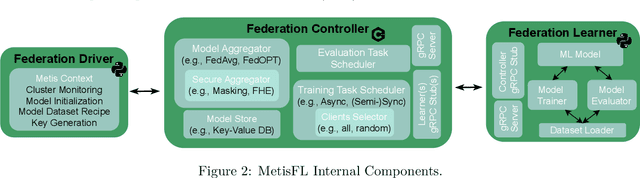
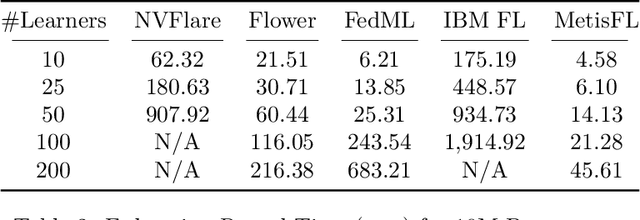
A Federated Learning (FL) system typically consists of two core processing entities: the federation controller and the learners. The controller is responsible for managing the execution of FL workflows across learners and the learners for training and evaluating federated models over their private datasets. While executing an FL workflow, the FL system has no control over the computational resources or data of the participating learners. Still, it is responsible for other operations, such as model aggregation, task dispatching, and scheduling. These computationally heavy operations generally need to be handled by the federation controller. Even though many FL systems have been recently proposed to facilitate the development of FL workflows, most of these systems overlook the scalability of the controller. To meet this need, we designed and developed a novel FL system called MetisFL, where the federation controller is the first-class citizen. MetisFL re-engineers all the operations conducted by the federation controller to accelerate the training of large-scale FL workflows. By quantitatively comparing MetisFL against other state-of-the-art FL systems, we empirically demonstrate that MetisFL leads to a 10-fold wall-clock time execution boost across a wide range of challenging FL workflows with increasing model sizes and federation sites.
RESenv: A Realistic Earthquake Simulation Environment based on Unreal Engine
Nov 13, 2023

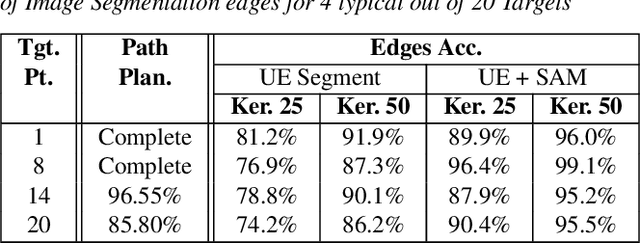
Earthquakes have a significant impact on societies and economies, driving the need for effective search and rescue strategies. With the growing role of AI and robotics in these operations, high-quality synthetic visual data becomes crucial. Current simulation methods, mostly focusing on single building damages, often fail to provide realistic visuals for complex urban settings. To bridge this gap, we introduce an innovative earthquake simulation system using the Chaos Physics System in Unreal Engine. Our approach aims to offer detailed and realistic visual simulations essential for AI and robotic training in rescue missions. By integrating real seismic waveform data, we enhance the authenticity and relevance of our simulations, ensuring they closely mirror real-world earthquake scenarios. Leveraging the advanced capabilities of Unreal Engine, our system delivers not only high-quality visualisations but also real-time dynamic interactions, making the simulated environments more immersive and responsive. By providing advanced renderings, accurate physical interactions, and comprehensive geological movements, our solution outperforms traditional methods in efficiency and user experience. Our simulation environment stands out in its detail and realism, making it a valuable tool for AI tasks such as path planning and image recognition related to earthquake responses. We validate our approach through three AI-based tasks: similarity detection, path planning, and image segmentation.
Robust and Scalable Hyperdimensional Computing With Brain-Like Neural Adaptations
Nov 13, 2023The Internet of Things (IoT) has facilitated many applications utilizing edge-based machine learning (ML) methods to analyze locally collected data. Unfortunately, popular ML algorithms often require intensive computations beyond the capabilities of today's IoT devices. Brain-inspired hyperdimensional computing (HDC) has been introduced to address this issue. However, existing HDCs use static encoders, requiring extremely high dimensionality and hundreds of training iterations to achieve reasonable accuracy. This results in a huge efficiency loss, severely impeding the application of HDCs in IoT systems. We observed that a main cause is that the encoding module of existing HDCs lacks the capability to utilize and adapt to information learned during training. In contrast, neurons in human brains dynamically regenerate all the time and provide more useful functionalities when learning new information. While the goal of HDC is to exploit the high-dimensionality of randomly generated base hypervectors to represent the information as a pattern of neural activity, it remains challenging for existing HDCs to support a similar behavior as brain neural regeneration. In this work, we present dynamic HDC learning frameworks that identify and regenerate undesired dimensions to provide adequate accuracy with significantly lowered dimensionalities, thereby accelerating both the training and inference.
KnowSafe: Combined Knowledge and Data Driven Hazard Mitigation in Artificial Pancreas Systems
Nov 13, 2023Significant progress has been made in anomaly detection and run-time monitoring to improve the safety and security of cyber-physical systems (CPS). However, less attention has been paid to hazard mitigation. This paper proposes a combined knowledge and data driven approach, KnowSafe, for the design of safety engines that can predict and mitigate safety hazards resulting from safety-critical malicious attacks or accidental faults targeting a CPS controller. We integrate domain-specific knowledge of safety constraints and context-specific mitigation actions with machine learning (ML) techniques to estimate system trajectories in the far and near future, infer potential hazards, and generate optimal corrective actions to keep the system safe. Experimental evaluation on two realistic closed-loop testbeds for artificial pancreas systems (APS) and a real-world clinical trial dataset for diabetes treatment demonstrates that KnowSafe outperforms the state-of-the-art by achieving higher accuracy in predicting system state trajectories and potential hazards, a low false positive rate, and no false negatives. It also maintains the safe operation of the simulated APS despite faults or attacks without introducing any new hazards, with a hazard mitigation success rate of 92.8%, which is at least 76% higher than solely rule-based (50.9%) and data-driven (52.7%) methods.
On Measuring Faithfulness of Natural Language Explanations
Nov 13, 2023Large language models (LLMs) can explain their own predictions, through post-hoc or Chain-of-Thought (CoT) explanations. However the LLM could make up reasonably sounding explanations that are unfaithful to its underlying reasoning. Recent work has designed tests that aim to judge the faithfulness of either post-hoc or CoT explanations. In this paper we argue that existing faithfulness tests are not actually measuring faithfulness in terms of the models' inner workings, but only evaluate their self-consistency on the output level. The aims of our work are two-fold. i) We aim to clarify the status of existing faithfulness tests in terms of model explainability, characterising them as self-consistency tests instead. This assessment we underline by constructing a Comparative Consistency Bank for self-consistency tests that for the first time compares existing tests on a common suite of 11 open-source LLMs and 5 datasets -- including ii) our own proposed self-consistency measure CC-SHAP. CC-SHAP is a new fine-grained measure (not test) of LLM self-consistency that compares a model's input contributions to answer prediction and generated explanation. With CC-SHAP, we aim to take a step further towards measuring faithfulness with a more interpretable and fine-grained method. Code available at \url{https://github.com/Heidelberg-NLP/CC-SHAP}
Yet Another Generative Model For Room Impulse Response Estimation
Nov 05, 2023Recent neural room impulse response (RIR) estimators typically comprise an encoder for reference audio analysis and a generator for RIR synthesis. Especially, it is the performance of the generator that directly influences the overall estimation quality. In this context, we explore an alternate generator architecture for improved performance. We first train an autoencoder with residual quantization to learn a discrete latent token space, where each token represents a small time-frequency patch of the RIR. Then, we cast the RIR estimation problem as a reference-conditioned autoregressive token generation task, employing transformer variants that operate across frequency, time, and quantization depth axes. This way, we address the standard blind estimation task and additional acoustic matching problem, which aims to find an RIR that matches the source signal to the target signal's reverberation characteristics. Experimental results show that our system is preferable to other baselines across various evaluation metrics.
Towards Effective Paraphrasing for Information Disguise
Nov 08, 2023Information Disguise (ID), a part of computational ethics in Natural Language Processing (NLP), is concerned with best practices of textual paraphrasing to prevent the non-consensual use of authors' posts on the Internet. Research on ID becomes important when authors' written online communication pertains to sensitive domains, e.g., mental health. Over time, researchers have utilized AI-based automated word spinners (e.g., SpinRewriter, WordAI) for paraphrasing content. However, these tools fail to satisfy the purpose of ID as their paraphrased content still leads to the source when queried on search engines. There is limited prior work on judging the effectiveness of paraphrasing methods for ID on search engines or their proxies, neural retriever (NeurIR) models. We propose a framework where, for a given sentence from an author's post, we perform iterative perturbation on the sentence in the direction of paraphrasing with an attempt to confuse the search mechanism of a NeurIR system when the sentence is queried on it. Our experiments involve the subreddit 'r/AmItheAsshole' as the source of public content and Dense Passage Retriever as a NeurIR system-based proxy for search engines. Our work introduces a novel method of phrase-importance rankings using perplexity scores and involves multi-level phrase substitutions via beam search. Our multi-phrase substitution scheme succeeds in disguising sentences 82% of the time and hence takes an essential step towards enabling researchers to disguise sensitive content effectively before making it public. We also release the code of our approach.
* Accepted at ECIR 2023