 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Audiosockets: A Python socket package for Real-Time Audio Processing
Mar 14, 2024
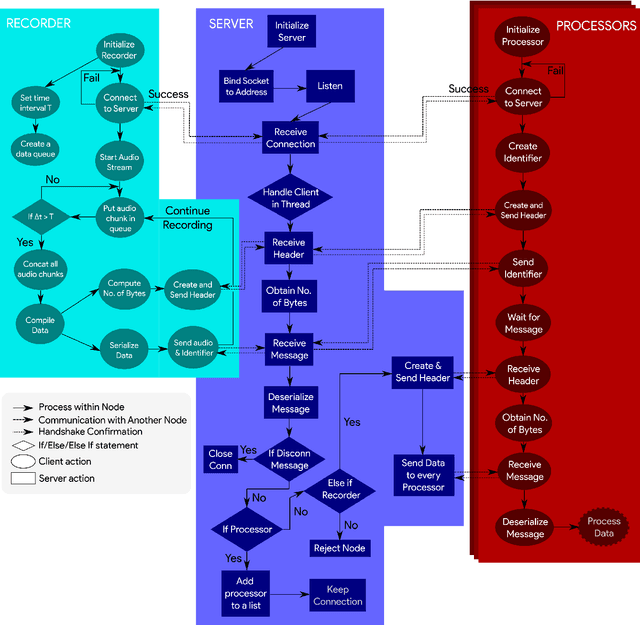
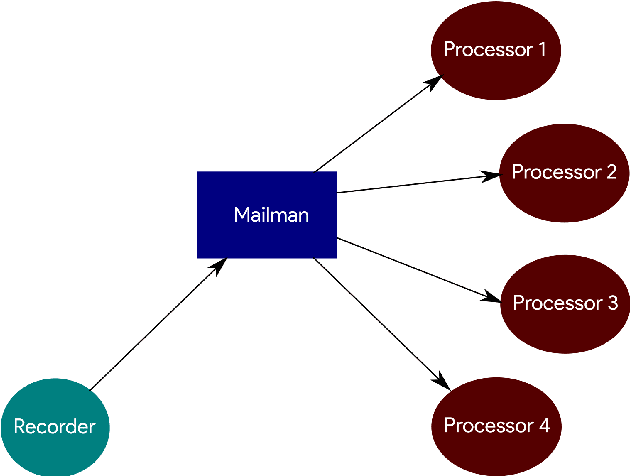
There are many packages in Python which allow one to perform real-time processing on audio data. Unfortunately, due to the synchronous nature of the language, there lacks a framework which allows for distributed parallel processing of the data without requiring a large programming overhead and in which the data acquisition is not blocked by subsequent processing operations. This work improves on packages used for audio data collection with a light-weight backend and a simple interface that allows for distributed processing through a socket-based structure. This is intended for real-time audio machine learning and data processing in Python with a quick deployment of multiple parallel operations on the same data, allowing users to spend less time debugging and more time developing.
Improving the Adaptive Moment Estimation (ADAM) stochastic optimizer through an Implicit-Explicit (IMEX) time-stepping approach
Mar 20, 2024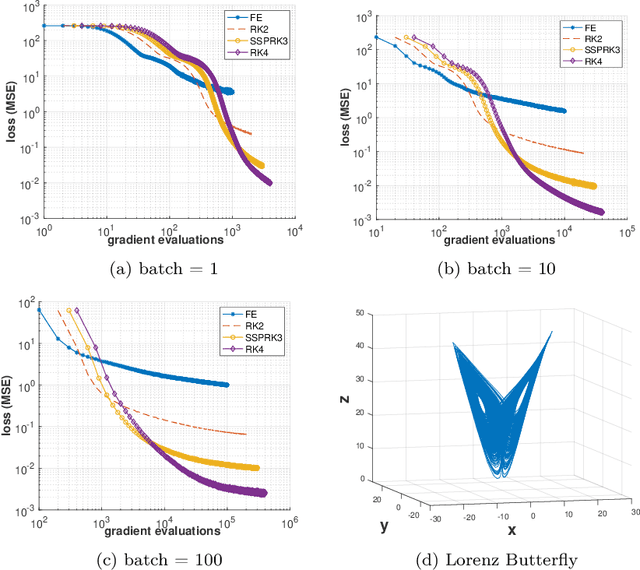
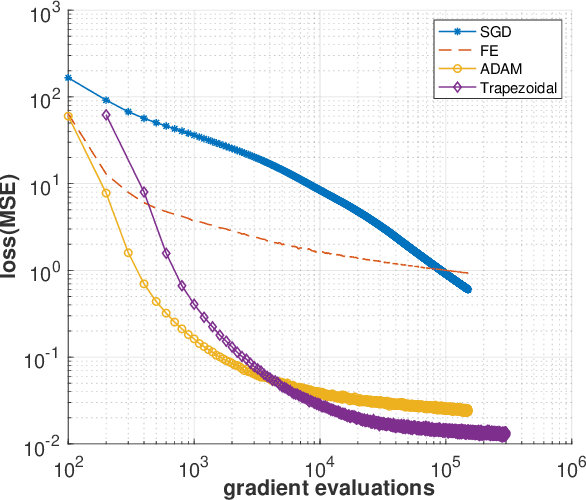
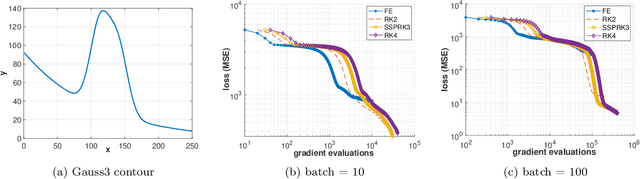
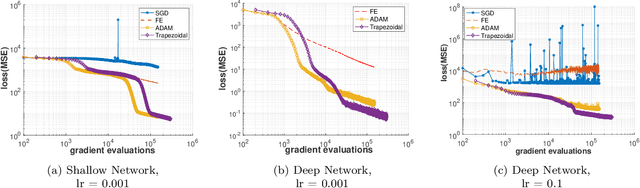
The Adam optimizer, often used in Machine Learning for neural network training, corresponds to an underlying ordinary differential equation (ODE) in the limit of very small learning rates. This work shows that the classical Adam algorithm is a first order implicit-explicit (IMEX) Euler discretization of the underlying ODE. Employing the time discretization point of view, we propose new extensions of the Adam scheme obtained by using higher order IMEX methods to solve the ODE. Based on this approach, we derive a new optimization algorithm for neural network training that performs better than classical Adam on several regression and classification problems.
MCformer: Multivariate Time Series Forecasting with Mixed-Channels Transformer
Mar 14, 2024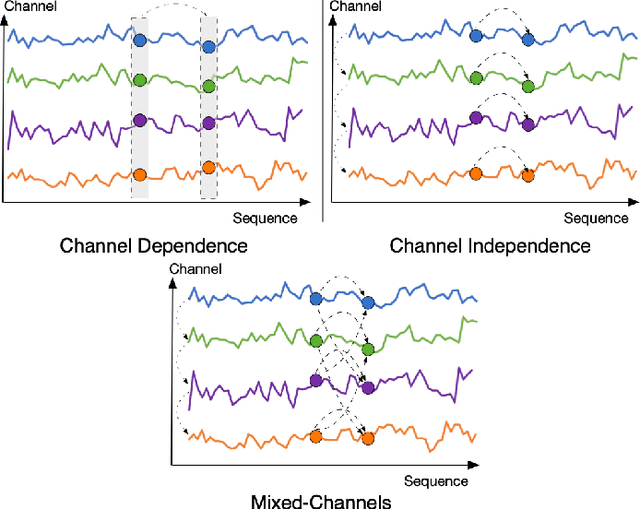

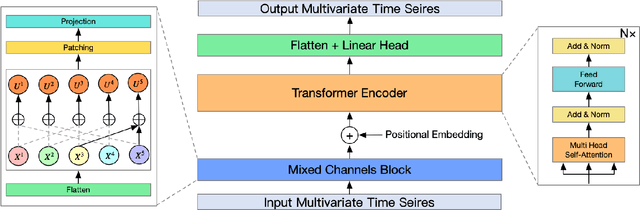

The massive generation of time-series data by largescale Internet of Things (IoT) devices necessitates the exploration of more effective models for multivariate time-series forecasting. In previous models, there was a predominant use of the Channel Dependence (CD) strategy (where each channel represents a univariate sequence). Current state-of-the-art (SOTA) models primarily rely on the Channel Independence (CI) strategy. The CI strategy treats all channels as a single channel, expanding the dataset to improve generalization performance and avoiding inter-channel correlation that disrupts long-term features. However, the CI strategy faces the challenge of interchannel correlation forgetting. To address this issue, we propose an innovative Mixed Channels strategy, combining the data expansion advantages of the CI strategy with the ability to counteract inter-channel correlation forgetting. Based on this strategy, we introduce MCformer, a multivariate time-series forecasting model with mixed channel features. The model blends a specific number of channels, leveraging an attention mechanism to effectively capture inter-channel correlation information when modeling long-term features. Experimental results demonstrate that the Mixed Channels strategy outperforms pure CI strategy in multivariate time-series forecasting tasks.
A Multi-Branched Radial Basis Network Approach to Predicting Complex Chaotic Behaviours
Mar 31, 2024In this study, we propose a multi branched network approach to predict the dynamics of a physics attractor characterized by intricate and chaotic behavior. We introduce a unique neural network architecture comprised of Radial Basis Function (RBF) layers combined with an attention mechanism designed to effectively capture nonlinear inter-dependencies inherent in the attractor's temporal evolution. Our results demonstrate successful prediction of the attractor's trajectory across 100 predictions made using a real-world dataset of 36,700 time-series observations encompassing approximately 28 minutes of activity. To further illustrate the performance of our proposed technique, we provide comprehensive visualizations depicting the attractor's original and predicted behaviors alongside quantitative measures comparing observed versus estimated outcomes. Overall, this work showcases the potential of advanced machine learning algorithms in elucidating hidden structures in complex physical systems while offering practical applications in various domains requiring accurate short-term forecasting capabilities.
ADs: Active Data-sharing for Data Quality Assurance in Advanced Manufacturing Systems
Mar 31, 2024Machine learning (ML) methods are widely used in industrial applications, which usually require a large amount of training data. However, data collection needs extensive time costs and investments in the manufacturing system, and data scarcity commonly exists. Therefore, data-sharing is widely enabled among multiple machines with similar functionality to augment the dataset for building ML methods. However, distribution mismatch inevitably exists in their data due to different working conditions, while the ML methods are assumed to be built and tested on the dataset following the same distribution. Thus, an Active Data-sharing (ADs) framework is proposed to ensure the quality of the shared data among multiple machines. It is designed to simultaneously select the most informative data points benefiting the downstream tasks and mitigate the distribution mismatch among all selected data points. The proposed method is validated on anomaly detection on in-situ monitoring data from three additive manufacturing processes.
Revealing Trends in Datasets from the 2022 ACL and EMNLP Conferences
Mar 31, 2024Natural language processing (NLP) has grown significantly since the advent of the Transformer architecture. Transformers have given birth to pre-trained large language models (PLMs). There has been tremendous improvement in the performance of NLP systems across several tasks. NLP systems are on par or, in some cases, better than humans at accomplishing specific tasks. However, it remains the norm that \emph{better quality datasets at the time of pretraining enable PLMs to achieve better performance, regardless of the task.} The need to have quality datasets has prompted NLP researchers to continue creating new datasets to satisfy particular needs. For example, the two top NLP conferences, ACL and EMNLP, accepted ninety-two papers in 2022, introducing new datasets. This work aims to uncover the trends and insights mined within these datasets. Moreover, we provide valuable suggestions to researchers interested in curating datasets in the future.
Exploring the Efficacy of Group-Normalization in Deep Learning Models for Alzheimer's Disease Classification
Apr 01, 2024Batch Normalization is an important approach to advancing deep learning since it allows multiple networks to train simultaneously. A problem arises when normalizing along the batch dimension because B.N.'s error increases significantly as batch size shrinks because batch statistics estimates are inaccurate. As a result, computer vision tasks like detection, segmentation, and video, which require tiny batches based on memory consumption, aren't suitable for using Batch Normalization for larger model training and feature transfer. Here, we explore Group Normalization as an easy alternative to using Batch Normalization A Group Normalization is a channel normalization method in which each group is divided into different channels, and the corresponding mean and variance are calculated for each group. Group Normalization computations are accurate across a wide range of batch sizes and are independent of batch size. When trained using a large ImageNet database on ResNet-50, GN achieves a very low error rate of 10.6% compared to Batch Normalization. when a smaller batch size of only 2 is used. For usual batch sizes, the performance of G.N. is comparable to that of Batch Normalization, but at the same time, it outperforms other normalization techniques. Implementing Group Normalization as a direct alternative to B.N to combat the serious challenges faced by the Batch Normalization in deep learning models with comparable or improved classification accuracy. Additionally, Group Normalization can be naturally transferred from the pre-training to the fine-tuning phase. .
Ziv-Zakai-Optimal OFDM Resource Allocation for Time-of-Arrival Estimation
Mar 19, 2024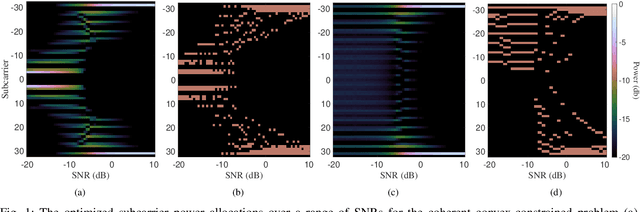
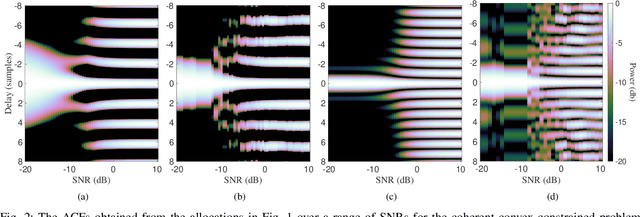
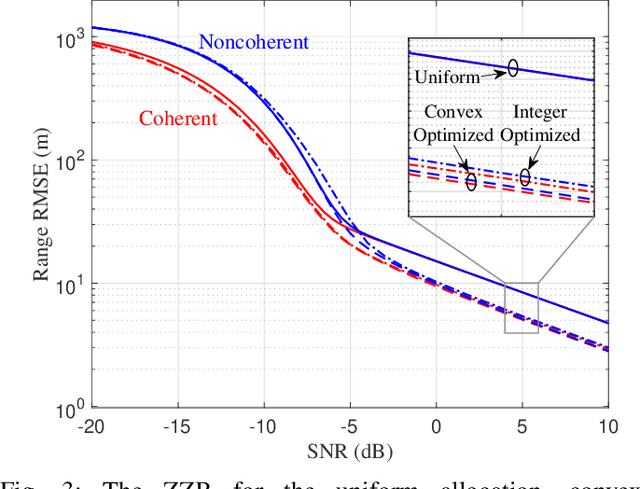
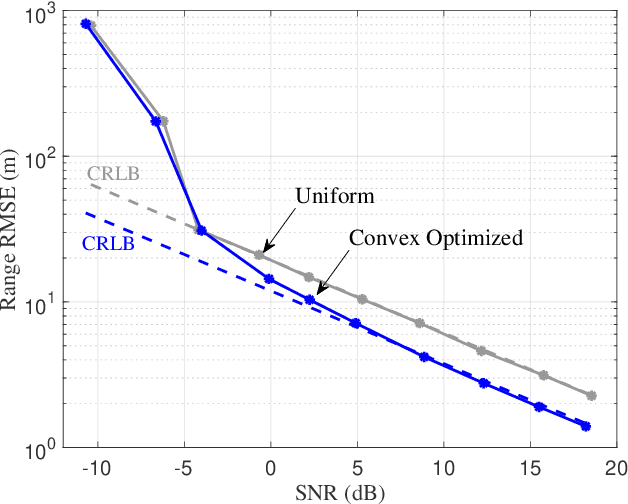
This paper presents methods of optimizing the placement and power allocations of pilots in an orthogonal frequency-division multiplexing (OFDM) signal to minimize time-of-arrival (TOA) estimation errors under power and resource allocation constraints. TOA errors in this optimization are quantified through the Ziv-Zakai bound (ZZB), which captures error thresholding effects caused by sidelobes in the signal's autocorrelation function (ACF) which are not captured by the Cramer-Rao lower bound. This paper is the first to solve for these ZZB-optimal allocations in the context of OFDM signals, under integer resource allocation constraints, and under both coherent and noncoherent reception. Under convex constraints, the optimization of the ZZB is proven to be convex; under integer constraints, the optimization is lower bounded by a convex relaxation and a branch-and-bound algorithm is proposed for efficiently allocating pilot resources. These allocations are evaluated by their ZZBs and ACFs, compared against a typical uniform allocation, and deployed on a software-defined radio TOA measurement platform to demonstrate their applicability in real-world systems.
Fast OMP for Exact Recovery and Sparse Approximation
Mar 29, 2024Orthogonal Matching Pursuit (OMP) has been a powerful method in sparse signal recovery and approximation. However OMP suffers computational issue when the signal has large number of non-zeros. This paper advances OMP in two fronts: it offers a fast algorithm for the orthogonal projection of the input signal at each iteration, and a new selection criterion for making the greedy choice, which reduces the number of iterations it takes to recover the signal. The proposed modifications to OMP directly reduce the computational complexity. Experiment results show significant improvement over the classical OMP in computation time. The paper also provided a sufficient condition for exact recovery under the new greedy choice criterion. For general signals that may not have sparse representations, the paper provides a bound for the approximation error. The approximation error is at the same order as OMP but is obtained within fewer iterations and less time.
Dual-Personalizing Adapter for Federated Foundation Models
Mar 28, 2024Recently, foundation models, particularly large language models (LLMs), have demonstrated an impressive ability to adapt to various tasks by fine-tuning large amounts of instruction data. Notably, federated foundation models emerge as a privacy preservation method to fine-tune models collaboratively under federated learning (FL) settings by leveraging many distributed datasets with non-IID data. To alleviate communication and computation overhead, parameter-efficient methods are introduced for efficiency, and some research adapted personalization methods to federated foundation models for better user preferences alignment. However, a critical gap in existing research is the neglect of test-time distribution shifts in real-world applications. Therefore, to bridge this gap, we propose a new setting, termed test-time personalization, which not only concentrates on the targeted local task but also extends to other tasks that exhibit test-time distribution shifts. To address challenges in this new setting, we explore a simple yet effective solution to learn a comprehensive foundation model. Specifically, a dual-personalizing adapter architecture (FedDPA) is proposed, comprising a global adapter and a local adapter for addressing test-time distribution shifts and personalization, respectively. Additionally, we introduce an instance-wise dynamic weighting mechanism to optimize the balance between the global and local adapters, enhancing overall performance. The effectiveness of the proposed method has been evaluated on benchmark datasets across different NLP tasks.