 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Stochastic Nonlinear Model Predictive Control with Look-ahead Deep Reinforcement Learning for Autonomous Vehicle Motion Control
Nov 07, 2023
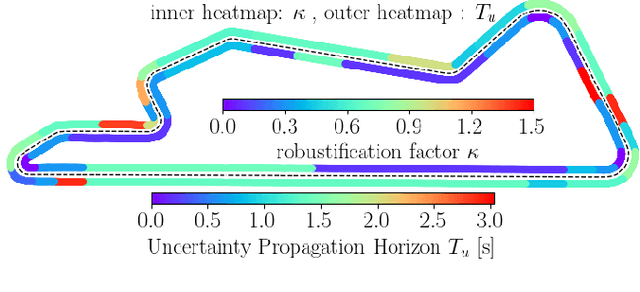
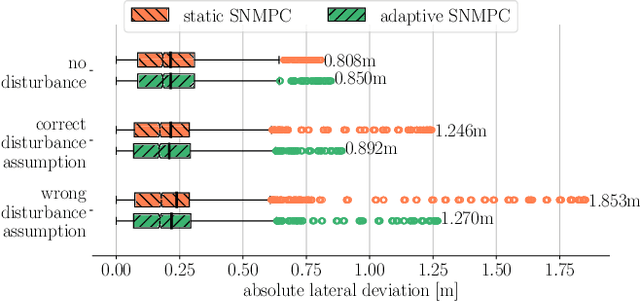
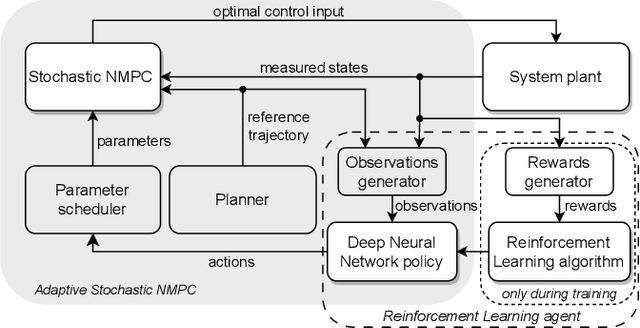
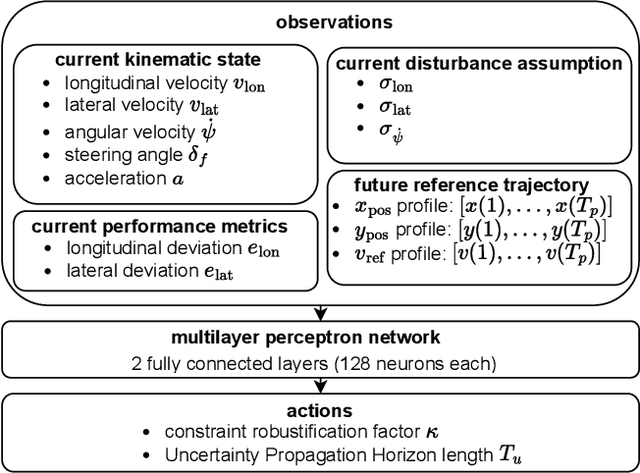
In this paper, we present a Deep Reinforcement Learning (RL)-driven Adaptive Stochastic Nonlinear Model Predictive Control (SNMPC) to optimize uncertainty handling, constraints robustification, feasibility, and closed-loop performance. To this end, we conceive an RL agent to proactively anticipate upcoming control tasks and to dynamically determine the most suitable combination of key SNMPC parameters - foremost the robustification factor $\kappa$ and the Uncertainty Propagation Horizon (UPH) $T_u$. We analyze the trained RL agent's decision-making process and highlight its ability to learn context-dependent optimal parameters. One key finding is that adapting the constraints robustification factor with the learned policy reduces conservatism and improves closed-loop performance while adapting UPH renders previously infeasible SNMPC problems feasible when faced with severe disturbances. We showcase the enhanced robustness and feasibility of our Adaptive SNMPC (aSNMPC) through the real-time motion control task of an autonomous passenger vehicle to follow an optimal race line when confronted with significant time-variant disturbances. Experimental findings demonstrate that our look-ahead RL-driven aSNMPC outperforms its Static SNMPC (sSNMPC) counterpart in minimizing the lateral deviation both with accurate and inaccurate disturbance assumptions and even when driving in previously unexplored environments.
Lightweight Portrait Matting via Regional Attention and Refinement
Nov 07, 2023We present a lightweight model for high resolution portrait matting. The model does not use any auxiliary inputs such as trimaps or background captures and achieves real time performance for HD videos and near real time for 4K. Our model is built upon a two-stage framework with a low resolution network for coarse alpha estimation followed by a refinement network for local region improvement. However, a naive implementation of the two-stage model suffers from poor matting quality if not utilizing any auxiliary inputs. We address the performance gap by leveraging the vision transformer (ViT) as the backbone of the low resolution network, motivated by the observation that the tokenization step of ViT can reduce spatial resolution while retain as much pixel information as possible. To inform local regions of the context, we propose a novel cross region attention (CRA) module in the refinement network to propagate the contextual information across the neighboring regions. We demonstrate that our method achieves superior results and outperforms other baselines on three benchmark datasets while only uses $1/20$ of the FLOPS compared to the existing state-of-the-art model.
Generative learning for nonlinear dynamics
Nov 07, 2023Modern generative machine learning models demonstrate surprising ability to create realistic outputs far beyond their training data, such as photorealistic artwork, accurate protein structures, or conversational text. These successes suggest that generative models learn to effectively parametrize and sample arbitrarily complex distributions. Beginning half a century ago, foundational works in nonlinear dynamics used tools from information theory to infer properties of chaotic attractors from time series, motivating the development of algorithms for parametrizing chaos in real datasets. In this perspective, we aim to connect these classical works to emerging themes in large-scale generative statistical learning. We first consider classical attractor reconstruction, which mirrors constraints on latent representations learned by state space models of time series. We next revisit early efforts to use symbolic approximations to compare minimal discrete generators underlying complex processes, a problem relevant to modern efforts to distill and interpret black-box statistical models. Emerging interdisciplinary works bridge nonlinear dynamics and learning theory, such as operator-theoretic methods for complex fluid flows, or detection of broken detailed balance in biological datasets. We anticipate that future machine learning techniques may revisit other classical concepts from nonlinear dynamics, such as transinformation decay and complexity-entropy tradeoffs.
A Hierarchical Spatial Transformer for Massive Point Samples in Continuous Space
Nov 08, 2023Transformers are widely used deep learning architectures. Existing transformers are mostly designed for sequences (texts or time series), images or videos, and graphs. This paper proposes a novel transformer model for massive (up to a million) point samples in continuous space. Such data are ubiquitous in environment sciences (e.g., sensor observations), numerical simulations (e.g., particle-laden flow, astrophysics), and location-based services (e.g., POIs and trajectories). However, designing a transformer for massive spatial points is non-trivial due to several challenges, including implicit long-range and multi-scale dependency on irregular points in continuous space, a non-uniform point distribution, the potential high computational costs of calculating all-pair attention across massive points, and the risks of over-confident predictions due to varying point density. To address these challenges, we propose a new hierarchical spatial transformer model, which includes multi-resolution representation learning within a quad-tree hierarchy and efficient spatial attention via coarse approximation. We also design an uncertainty quantification branch to estimate prediction confidence related to input feature noise and point sparsity. We provide a theoretical analysis of computational time complexity and memory costs. Extensive experiments on both real-world and synthetic datasets show that our method outperforms multiple baselines in prediction accuracy and our model can scale up to one million points on one NVIDIA A100 GPU. The code is available at \url{https://github.com/spatialdatasciencegroup/HST}.
Scalable and Effective Generative Information Retrieval
Nov 15, 2023Recent research has shown that transformer networks can be used as differentiable search indexes by representing each document as a sequences of document ID tokens. These generative retrieval models cast the retrieval problem to a document ID generation problem for each given query. Despite their elegant design, existing generative retrieval models only perform well on artificially-constructed and small-scale collections. This has led to serious skepticism in the research community on their real-world impact. This paper represents an important milestone in generative retrieval research by showing, for the first time, that generative retrieval models can be trained to perform effectively on large-scale standard retrieval benchmarks. For doing so, we propose RIPOR- an optimization framework for generative retrieval that can be adopted by any encoder-decoder architecture. RIPOR is designed based on two often-overlooked fundamental design considerations in generative retrieval. First, given the sequential decoding nature of document ID generation, assigning accurate relevance scores to documents based on the whole document ID sequence is not sufficient. To address this issue, RIPOR introduces a novel prefix-oriented ranking optimization algorithm. Second, initial document IDs should be constructed based on relevance associations between queries and documents, instead of the syntactic and semantic information in the documents. RIPOR addresses this issue using a relevance-based document ID construction approach that quantizes relevance-based representations learned for documents. Evaluation on MSMARCO and TREC Deep Learning Track reveals that RIPOR surpasses state-of-the-art generative retrieval models by a large margin (e.g., 30.5% MRR improvements on MS MARCO Dev Set), and perform better on par with popular dense retrieval models.
MAP's not dead yet: Uncovering true language model modes by conditioning away degeneracy
Nov 15, 2023It has been widely observed that exact or approximate MAP (mode-seeking) decoding from natural language generation (NLG) models consistently leads to degenerate outputs (Stahlberg and Byrne, 2019, Holtzman et al., 2019). This has generally been attributed to either a fundamental inadequacy of modes in models or weaknesses in language modeling. Contrastingly in this work, we emphasize that degenerate modes can even occur in the absence of any model error, due to contamination of the training data. Specifically, we show that mixing even a tiny amount of low-entropy noise with a population text distribution can cause the data distribution's mode to become degenerate, implying that any models trained on it will be as well. As the unconditional mode of NLG models will often be degenerate, we therefore propose to apply MAP decoding to the model's distribution conditional on avoiding specific degeneracies. Using exact-search, we empirically verify that the length-conditional modes of machine translation models and language models are indeed more fluent and topical than their unconditional modes. For the first time, we also share many examples of exact modal sequences from these models, and from several variants of the LLaMA-7B model. Notably, the modes of the LLaMA models are still degenerate, showing that improvements in modeling have not fixed this issue. Because of the cost of exact mode finding algorithms, we develop an approximate mode finding approach, ACBS, which finds sequences that are both high-likelihood and high-quality. We apply this approach to LLaMA-7B, a model which was not trained for instruction following, and find that we are able to elicit reasonable outputs without any finetuning.
Nothing Stands Still: A Spatiotemporal Benchmark on 3D Point Cloud Registration Under Large Geometric and Temporal Change
Nov 15, 2023
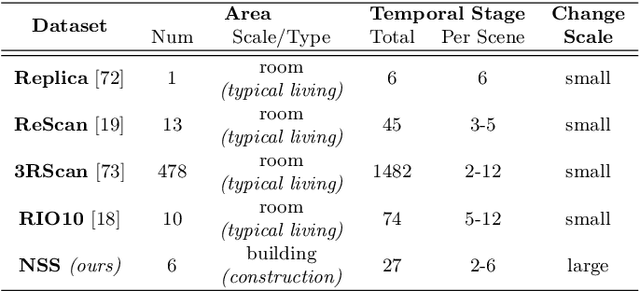
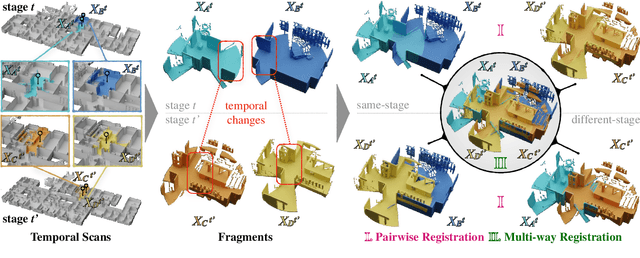
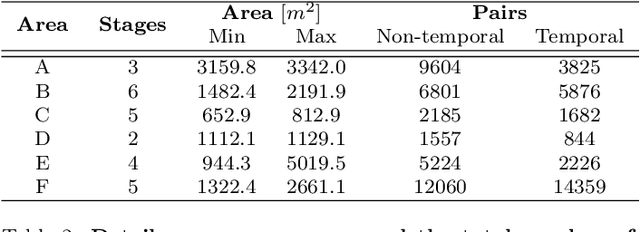
Building 3D geometric maps of man-made spaces is a well-established and active field that is fundamental to computer vision and robotics. However, considering the evolving nature of built environments, it is essential to question the capabilities of current mapping efforts in handling temporal changes. In addition, spatiotemporal mapping holds significant potential for achieving sustainability and circularity goals. Existing mapping approaches focus on small changes, such as object relocation or self-driving car operation; in all cases where the main structure of the scene remains fixed. Consequently, these approaches fail to address more radical changes in the structure of the built environment, such as geometry and topology. To this end, we introduce the Nothing Stands Still (NSS) benchmark, which focuses on the spatiotemporal registration of 3D scenes undergoing large spatial and temporal change, ultimately creating one coherent spatiotemporal map. Specifically, the benchmark involves registering two or more partial 3D point clouds (fragments) from the same scene but captured from different spatiotemporal views. In addition to the standard pairwise registration, we assess the multi-way registration of multiple fragments that belong to any temporal stage. As part of NSS, we introduce a dataset of 3D point clouds recurrently captured in large-scale building indoor environments that are under construction or renovation. The NSS benchmark presents three scenarios of increasing difficulty, to quantify the generalization ability of point cloud registration methods over space (within one building and across buildings) and time. We conduct extensive evaluations of state-of-the-art methods on NSS. The results demonstrate the necessity for novel methods specifically designed to handle large spatiotemporal changes. The homepage of our benchmark is at http://nothing-stands-still.com.
Semantic Map Guided Synthesis of Wireless Capsule Endoscopy Images using Diffusion Models
Nov 10, 2023Wireless capsule endoscopy (WCE) is a non-invasive method for visualizing the gastrointestinal (GI) tract, crucial for diagnosing GI tract diseases. However, interpreting WCE results can be time-consuming and tiring. Existing studies have employed deep neural networks (DNNs) for automatic GI tract lesion detection, but acquiring sufficient training examples, particularly due to privacy concerns, remains a challenge. Public WCE databases lack diversity and quantity. To address this, we propose a novel approach leveraging generative models, specifically the diffusion model (DM), for generating diverse WCE images. Our model incorporates semantic map resulted from visualization scale (VS) engine, enhancing the controllability and diversity of generated images. We evaluate our approach using visual inspection and visual Turing tests, demonstrating its effectiveness in generating realistic and diverse WCE images.
Local Discovery by Partitioning: Polynomial-Time Causal Discovery Around Exposure-Outcome Pairs
Oct 25, 2023This work addresses the problem of automated covariate selection under limited prior knowledge. Given an exposure-outcome pair {X,Y} and a variable set Z of unknown causal structure, the Local Discovery by Partitioning (LDP) algorithm partitions Z into subsets defined by their relation to {X,Y}. We enumerate eight exhaustive and mutually exclusive partitions of any arbitrary Z and leverage this taxonomy to differentiate confounders from other variable types. LDP is motivated by valid adjustment set identification, but avoids the pretreatment assumption commonly made by automated covariate selection methods. We provide theoretical guarantees that LDP returns a valid adjustment set for any Z that meets sufficient graphical conditions. Under stronger conditions, we prove that partition labels are asymptotically correct. Total independence tests is worst-case quadratic in |Z|, with sub-quadratic runtimes observed empirically. We numerically validate our theoretical guarantees on synthetic and semi-synthetic graphs. Adjustment sets from LDP yield less biased and more precise average treatment effect estimates than baselines, with LDP outperforming on confounder recall, test count, and runtime for valid adjustment set discovery.
Resource-Aware Hierarchical Federated Learning for Video Caching in Wireless Networks
Nov 12, 2023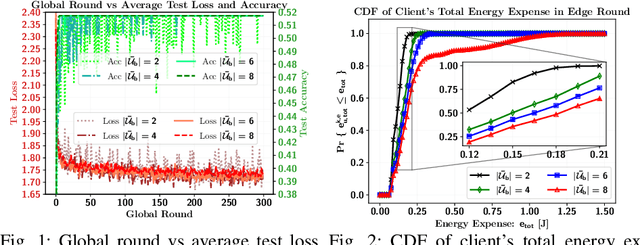
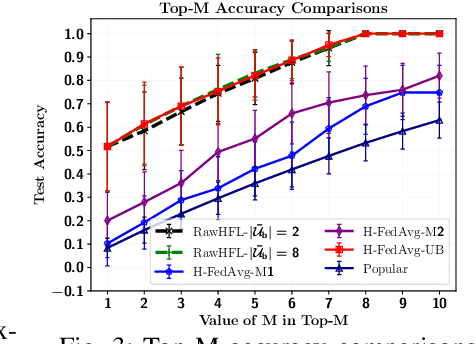
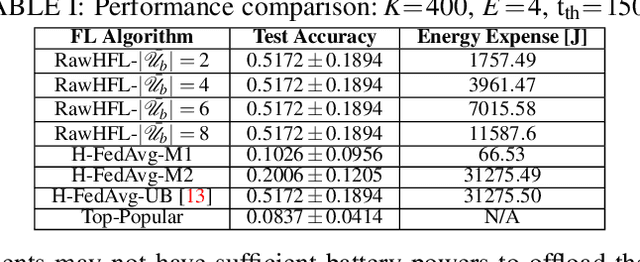
Video caching can significantly improve backhaul traffic congestion by locally storing the popular content that users frequently request. A privacy-preserving method is desirable to learn how users' demands change over time. As such, this paper proposes a novel resource-aware hierarchical federated learning (RawHFL) solution to predict users' future content requests under the realistic assumptions that content requests are sporadic and users' datasets can only be updated based on the requested content's information. Considering a partial client participation case, we first derive the upper bound of the global gradient norm that depends on the clients' local training rounds and the successful reception of their accumulated gradients over the wireless links. Under delay, energy and radio resource constraints, we then optimize client selection and their local rounds and central processing unit (CPU) frequencies to minimize a weighted utility function that facilitates RawHFL's convergence in an energy-efficient way. Our simulation results show that the proposed solution significantly outperforms the considered baselines in terms of prediction accuracy and total energy expenditure.